版本1.7.3.RELEASE
©2012-2018 Pivotal Software,Inc。
本文档的副本可供您自己使用并分发给他人,前提是您不对此类副本收取任何费用,并且每份副本均包含本版权声明,无论是以印刷版还是电子版分发。
前言
1.关于文档
2.获得帮助
遇到Spring Cloud Data Flow问题,我们想帮忙!
-
问一个问题。我们监控stackoverflow.com以获取标记的问题
spring-cloud-dataflow。 -
在github.com/spring-cloud/spring-cloud-dataflow/issues上使用Spring Cloud Data Flow报告错误。
| 所有Spring Cloud Data Flow都是开源的,包括文档!如果您发现文档有问题,或者您只想改进它们,请参与其中。 |
入门
如果您开始使用Spring Cloud Data Flow,则本节适合您。在本节中,我们回答基本的“什么?”,“如何?”和“为什么?”的问题。您可以找到Spring Cloud Data Flow的简要介绍以及安装说明。然后,我们构建一个介绍性的Spring Cloud Data Flow应用程序,讨论一些核心原则。
3.系统要求
4. Docker Compose入门
从Spring Cloud Data Flow 1.4开始,提供Docker Compose文件以快速显示Spring Cloud Data Flow及其依赖项,而无需手动获取它们。运行时,组合系统包括Spring Cloud Data Flow本地服务器的最新GA版本,使用Kafka绑定器进行通信。Docker Compose是必需的,建议使用最新版本。
-
下载Spring Cloud Data Flow本地服务器Docker Compose文件:
$ wget https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v1.7.3.RELEASE/spring-cloud-dataflow-server-local/docker-compose.yml
如果wget命令不可用,则可以使用curl或其他特定于平台的实用程序。或者导航到web中的https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v1.7.3.RELEASE/spring-cloud-dataflow-server-local/docker-compose.yml浏览器并保存内容。确保下载的文件名为docker-compose.yml。
|
-
启动Docker Compose
在您下载
docker-compose.yml的目录中,启动系统,如下所示:$ export DATAFLOW_VERSION=1.7.3.RELEASE $ docker-compose updocker-compose.yml文件定义变量DATAFLOW_VERSION,以便可以轻松更改。上面的命令首先设置要在环境中使用的DATAFLOW_VERSION,然后启动docker-compose。只将
DATAFLOW_VERSION变量暴露给docker-compose进程而不是在环境中设置的简写版本如下:$ DATAFLOW_VERSION=1.7.3.RELEASE docker-compose up使用Windows时,使用
set命令定义环境变量。要在Windows上启动系统,请输入以下命令:C:\ set DATAFLOW_VERSION=1.7.3.RELEASE C:\ docker-compose up默认情况下,Docker Compose将使用本地可用的图像。例如,在使用 latest标记时,请在docker-compose up之前执行docker-compose pull以确保下载最新图像。 -
启动Spring Cloud Data Flow仪表板
docker-compose命令停止发出日志消息后,Spring Cloud Data Flow将可以使用。此时,在浏览器中导航到Spring Cloud Data Flow仪表板。默认情况下,将自动导入最新的GA版本的Stream和Task应用程序。 -
创建一个流
要创建流,首先导航到“Streams”菜单链接,然后单击“Create Stream”链接。在“Create Stream”textarea中输入
time | log,然后单击“CREATE STREAM”按钮。输入“ticktock”作为流名称,然后单击“Deploy Stream(s)”复选框,如下图所示: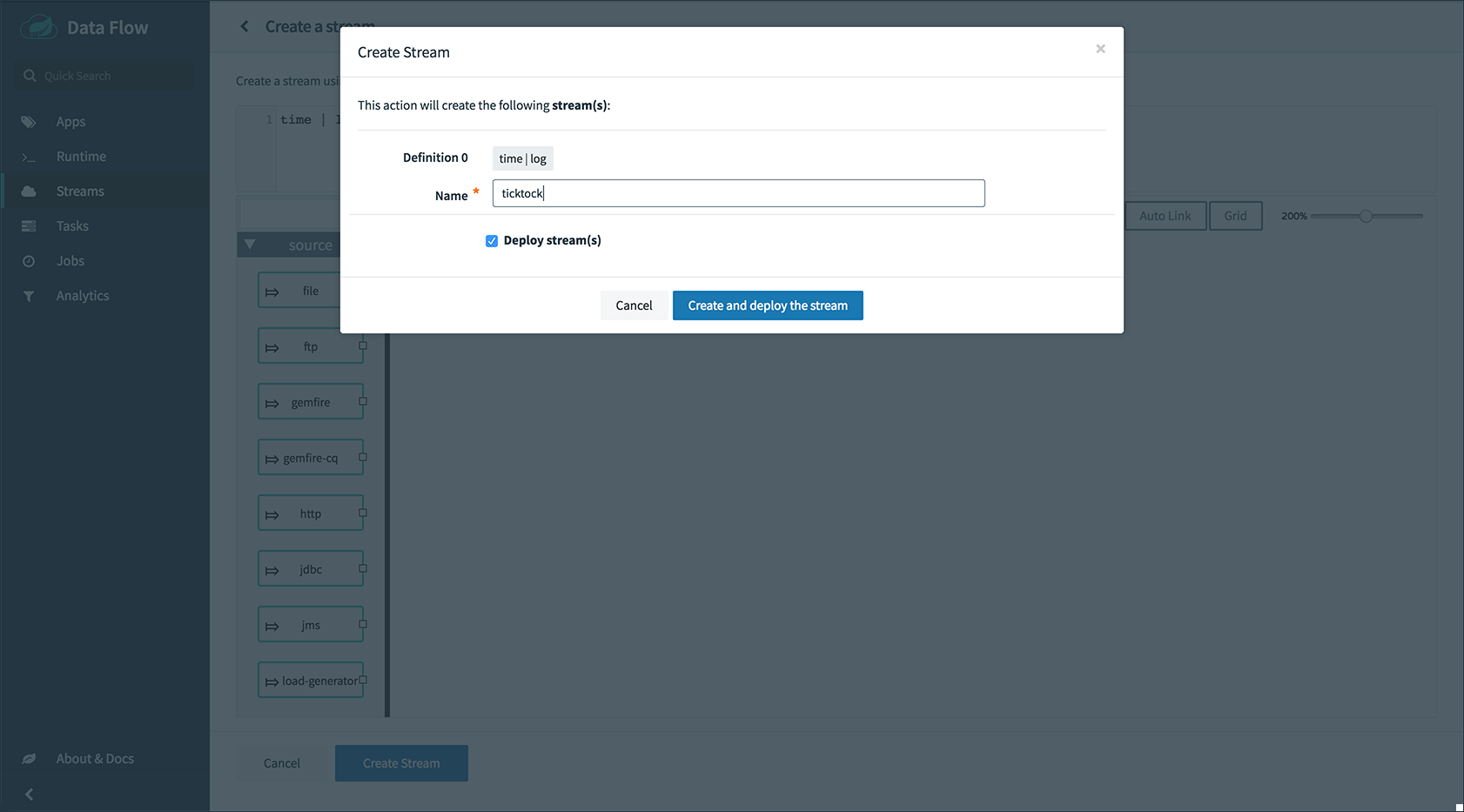 图1.创建流
图1.创建流然后单击“确定”,它将返回到“定义”页面。流将处于“部署”状态,并在完成后移至“已部署”。您可能需要刷新浏览器才能看到更新后的状态。
-
查看流日志
要查看流日志,请导航到“运行时”菜单链接,然后单击“ticktock.log”链接。复制仪表板上“stdout”文本框中的路径以及另一种控制台类型:
$ docker exec -it dataflow-server tail -f /path/from/stdout/textbox/in/dashboard您现在应该看到日志接收器的输出,每秒打印一次时间戳。按CTRL + c结束
tail。 -
删除流
要删除流,首先导航到仪表板中的“Streams”菜单链接,然后单击“ticktock”行上的复选框。单击“DESTROY ALL 1 SELECTED STREAMS”按钮,然后单击“YES”以销毁流。
-
销毁快速启动环境
要破坏快速启动环境,请在
docker-compose.yml所在的另一个控制台中键入如下内容:$ docker-compose down某些流应用程序可能会打开一个端口,例如 http --server.port=。默认情况下,端口范围9000-9010从容器暴露给主机。如果要更改此范围,请修改docker-compose.yml文件中dataflow-server服务的ports块。
4.1.Docker撰写自定义
开箱即用的Spring Cloud Data Flow将使用H2嵌入式数据库来存储状态,Kafka用于通信而不使用分析。可以通过编辑docker-compose.yml文件对这些组件进行自定义,如下所述。
-
要使用MySQL而不是H2嵌入式数据库,请在
services部分下添加以下配置:mysql: image: mariadb:10.2 environment: MYSQL_DATABASE: dataflow MYSQL_USER: root MYSQL_ROOT_PASSWORD: rootpw expose: - 3306需要将以下条目添加到
dataflow-server服务定义的environment块中:- spring.datasource.url=jdbc:mysql://mysql:3306/dataflow - spring.datasource.username=root - spring.datasource.password=rootpw - spring.datasource.driver-class-name=org.mariadb.jdbc.Driver -
要使用RabbitMQ代替Kafka进行通信,请替换
services部分下的以下配置:kafka: image: wurstmeister/kafka:1.1.0 expose: - "9092" environment: - KAFKA_ADVERTISED_PORT=9092 - KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 - KAFKA_ADVERTISED_HOST_NAME=kafka zookeeper: image: wurstmeister/zookeeper expose: - "2181"附:
rabbitmq: image: rabbitmq:3.7 expose: - "5672"在
dataflow-server服务配置块中,添加以下environment条目:- spring.cloud.dataflow.applicationProperties.stream.spring.rabbitmq.host=rabbitmq最后,修改
app-import服务定义command属性,将bit.ly/Celsius-SR3-stream-applications-kafka-10-maven替换为bit.ly/Celsius-SR3-stream-applications-rabbit-maven。 -
要使用redis作为后端启用分析,请在
services部分下添加以下配置:redis: image: redis:2.8 expose: - "6379"然后将以下条目添加到
dataflow-server服务定义的environment块中:- spring.cloud.dataflow.applicationProperties.stream.spring.redis.host=redis - spring.redis.host=redis -
要直接从主机启用
app starters注册,您必须将源主机文件夹装载到dataflow-server容器。例如,如果my-app.jar位于主机上的/foo/bar/apps文件夹中,则将以下volumes块添加到dataflow-server服务定义中:dataflow-server: image: springcloud/spring-cloud-dataflow-server-local:${DATAFLOW_VERSION} container_name: dataflow-server ports: - "9393:9393" environment: - spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=kafka:9092 - spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=zookeeper:2181 volumes: - /foo/bar/apps:/root/apps稍后,可以从容器的
/root/apps/文件夹中访问my-app.jar(以及文件夹中的其他文件)。检查撰写文件参考以了解其他配置详细信息。显式卷安装将docker-compose耦合到主机的文件系统,从而限制了对其他计算机和操作系统的可移植性。与 docker不同,docker-compose不允许从命令行进行卷安装(例如,没有-v类参数)。相反,您可以定义占位符环境变量(例如HOST_APP_FOLDER)来代替硬编码路径:- ${HOST_APP_FOLDER}:/root/apps并在启动docker-compose之前设置此变量。dataflow:>app register --type source --name my-app --uri file://root/apps/my-app.jar如果元数据jar在/ root / apps中可用,也可以使用 --metadata-uri。要从
dataflow-server容器中访问主机的本地maven存储库,您应该将主机maven本地存储库(OSX和Linux的默认值为~/.m2,Windows的默认值为C:\Documents and Settings{your-username}\.m2)挂载到名为{的dataflow-server卷。 5 /}。对于MacOS或Linux主机,这看起来像这样:dataflow-server: ......... volumes: - ~/.m2:/root/.m2现在,您可以使用
maven://URI模式和maven坐标来解析安装在主机maven存储库中的jar:dataflow:>app register --type processor --name pose-estimation --uri maven://org.springframework.cloud.stream.app:pose-estimation-processor-rabbit:2.0.2.BUILD-SNAPSHOT --metadata-uri maven://org.springframework.cloud.stream.app:pose-estimation-processor-rabbit:jar:metadata:2.0.2.BUILD-SNAPSHOT --force这种方法允许您直接与数据流服务器容器共享构建并安装在主机上的jar(例如
mvn clean install)。也可以直接在docker-compose中预先注册应用程序。对于每个预先注册的app starer,在
app-import块配置中添加一个额外的wget语句:app-import: image: alpine:3.7 command: > /bin/sh -c " .... wget -qO- 'http://dataflow-server:9393/apps/source/my-app' --post-data='uri=file:/root/apps/my-app.jar&metadata-uri=file:/root/apps/my-app-metadata.jar'; echo 'My custom apps imported'"有关更多详细信息,请查看SCDF REST API。
-
要启用Spring Cloud Skipper以及Metrics支持,需要进行以下修改。在此示例中,假设stock
docker-compose.yml文件用作起点。仍然可以应用自定义,例如使用上面的示例与Rabbit交换Kafka。首先,在
zookeeper服务定义之后:-
按照使用Redis启用分析中所述添加Redis
然后在
dataflow-server服务定义下添加Skipper和Metrics:skipper-server: image: springcloud/spring-cloud-skipper-server:1.1.2.RELEASE container_name: skipper ports: - "7577:7577" - "9000-9010:9000-9010" environment: - spring.datasource.url=jdbc:mysql://mysql:3306/dataflow - spring.datasource.username=root - spring.datasource.password=rootpw - spring.datasource.driver-class-name=org.mariadb.jdbc.Driver metrics-collector: image: springcloud/metrics-collector-kafka:2.0.0.RELEASE environment: - spring.cloud.stream.kafka.binder.brokers=kafka:9092 - spring.cloud.stream.kafka.binder.zkNodes=zookeeper:2181 - spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.security.servlet.SecurityAutoConfiguration expose: - "8080"从
dataflow-server删除应用程序端口映射,因为它们现在已分配给skipper-server容器:dataflow-server: ... ports: - "9393:9393" - "9000-9010:9000-9010"变为:
dataflow-server: ... ports: - "9393:9393"最后将以下环境变量附加到
dataflow-serverenvironment块:- spring.cloud.dataflow.features.skipper-enabled=true - spring.cloud.skipper.client.serverUri=http://skipper-server:7577/api使用Skipper时,已启动的应用程序及其日志驻留在 skipper容器而不是dataflow-server容器中。例如,如前所述查看流日志时,将引用skipper容器:$ docker exec -it skipper tail -f /path/from/stdout/textbox/in/dashboard
5.手动安装入门
-
下载Spring Cloud Data Flow服务器和Shell应用程序:
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server-local/1.7.3.RELEASE/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-shell/1.7.3.RELEASE/spring-cloud-dataflow-shell-1.7.3.RELEASE.jar从1.3.x开始,数据流服务器可以以
skipper或classic模式运行。classic模式是数据流服务器在1.2.x版本中的工作方式。使用属性spring.cloud.dataflow.features.skipper-enabled启动数据流服务器时指定模式。默认情况下,启用classic模式。 -
如果您希望在Streams中升级和回滚应用程序的附加功能,请下载Skipper,因为Data Flow会委托Skipper获取这些功能。
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-skipper-server/1.1.2.RELEASE/spring-cloud-skipper-server-1.1.2.RELEASE.jar wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-skipper-shell/1.1.2.RELEASE/spring-cloud-skipper-shell-1.1.2.RELEASE.jar -
启动Skipper(仅当您要在
skipper模式下运行Spring Cloud Data Flow服务器时才需要)在您下载Skipper的目录中,使用
java -jar运行服务器,如下所示:$ java -jar spring-cloud-skipper-server-1.1.2.RELEASE.jar -
启动数据流服务器
在下载数据流的目录中,使用
java -jar运行服务器,如下所示:要以
classic模式运行数据流服务器:$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar要以
skipper模式运行数据流服务器:$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --spring.cloud.dataflow.features.skipper-enabled=true如果Skipper和数据流服务器未在同一主机上运行,请将配置属性
spring.cloud.skipper.client.serverUri设置为Skipper的位置,例如$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --spring.cloud.skipper.client.serverUri=http://192.51.100.1:7577/api -
启动数据流Shell,如下所示:
启动Data Flow shell需要指定适当的数据流服务器模式。要以
classic模式运行的数据流服务器启动数据流Shell:$ java -jar spring-cloud-dataflow-shell-1.7.3.RELEASE.jar要以
skipper模式运行的数据流服务器启动数据流Shell:$ java -jar spring-cloud-dataflow-shell-1.7.3.RELEASE.jar --dataflow.mode=skipper数据流服务器和命令行管理程序必须处于同一模式。 如果数据流服务器和shell未在同一主机上运行,则在shell的交互模式下,您还可以使用
dataflow config server命令将shell指向数据流服务器URL。如果数据流服务器和shell未在同一主机上运行,请将shell指向数据流服务器URL,如下所示:
server-unknown:>dataflow config server http://198.51.100.0 Successfully targeted http://198.51.100.0 dataflow:>或者,传入命令行选项
--dataflow.uri。shell的命令行选项--help显示可用的内容。
6.部署Streams
-
注册流应用
默认情况下,应用程序注册表为空。例如,注册使用RabbitMQ进行通信的两个应用程序
http和log。dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE Successfully registered application 'source:http' dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE Successfully registered application 'sink:log'有关更多详细信息,例如如何注册基于docker容器的应用程序或使用Kafka作为消息传递中间件,请查看有关如何注册应用程序的部分。
根据您的环境,您可能需要将数据流服务器配置为指向自定义Maven存储库位置或配置代理设置。有关更多信息,请参阅Maven。 在本入门部分中,我们仅显示部署流,因此命令在服务器的
skipper和classic模式下是相同的。 -
创建一个流
使用
stream create命令创建一个带有http源和log接收器的流并部署它:dataflow:> stream create --name httptest --definition "http --server.port=9000 | log" --deploy在发布数据之前,您需要等待一段时间,直到应用程序实际部署成功。查看数据流服务器的日志文件,以获取 http和log应用程序的日志文件的位置。对每个应用程序使用日志文件上的tail命令验证应用程序是否已启动。现在发布一些数据,如下例所示:
dataflow:> http post --target http://localhost:9000 --data "hello world"检查
hello world应用程序的日志文件中是否hello world结束。log应用程序的日志文件的位置将显示在数据流服务器的日志中。
您可以在使用Skipper的Stream Lifecycle部分以及如何使用Skipper在Streams中升级和回滚流中,阅读有关使用Skipper部署流的一般功能的更多信息。
|
在本地部署时,每个应用程序(以及每个应用程序实例,在 |
7.部署任务
在本入门部分,我们将展示如何注册任务,创建任务定义然后启动它。然后,我们还将审查有关任务执行的信息。
| 启动Spring Cloud Task应用程序不会委托给Skipper,因为它们是短期应用程序。通过数据流服务器直接部署任务。 |
-
注册任务应用程序
默认情况下,应用程序注册表为空。例如,我们将注册一个任务应用程序
timestamp,它只是将当前时间打印到日志中。dataflow:>app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:1.3.0.RELEASE Successfully registered application 'task:timestamp'根据您的环境,您可能需要将数据流服务器配置为指向自定义Maven存储库位置或配置代理设置。有关更多信息,请参阅Maven。 -
创建任务定义
使用
task create命令使用以前注册的timestamp应用程序创建任务定义。在此示例中,没有使用其他属性来配置timestamp应用程序。dataflow:> task create --name printTimeStamp --definition "timestamp" -
启动任务
任务定义的启动是通过shell的
task launch命令完成的。dataflow:> task launch printTimeStamp检查时间戳是否在时间戳任务的日志文件中结束。任务应用程序的日志文件的位置将显示在数据流服务器的日志中。您应该看到类似的日志条目
TimestampTaskConfiguration$TimestampTask : 2018-02-28 16:42:21.051 -
检查任务执行
可以使用命令
task execution list获取有关任务执行的信息。dataflow:>task execution list ╔══════════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗ ║ Task Name │ID│ Start Time │ End Time │Exit Code║ ╠══════════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣ ║printTimeStamp│1 │Wed Feb 28 16:42:21 EST 2018│Wed Feb 28 16:42:21 EST 2018│0 ║ ╚══════════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝可以使用命令
task execution status获取其他信息。dataflow:>task execution status --id 1 ╔══════════════════════╤═══════════════════════════════════════════════════╗ ║ Key │ Value ║ ╠══════════════════════╪═══════════════════════════════════════════════════╣ ║Id │1 ║ ║Name │printTimeStamp ║ ║Arguments │[--spring.cloud.task.executionid=1] ║ ║Job Execution Ids │[] ║ ║Start Time │Wed Feb 28 16:42:21 EST 2018 ║ ║End Time │Wed Feb 28 16:42:21 EST 2018 ║ ║Exit Code │0 ║ ║Exit Message │ ║ ║Error Message │ ║ ║External Execution Id │printTimeStamp-ab86b2cc-0508-4c1e-b33d-b3896d17fed7║ ╚══════════════════════╧═══════════════════════════════════════════════════╝
应用
8.可用应用程序
| 资源 | 处理器 | 下沉 | 任务 |
|---|---|---|---|
task-launcher-yarn |
|||
task-launcher-local |
|||
loggregator |
|||
tasklaunchrequest-transform |
|||
task-launcher-cloudfoundry |
架构
9.简介
Spring Cloud Data Flow简化了专注于数据处理用例的应用程序的开发和部署。该体系结构的主要概念是Applications,Data Flow Server和目标运行时。
应用程序有两种形式:
-
长期存在的Stream应用程序,通过消息传递中间件消耗或生成无限量的数据。
-
短期任务应用程序,处理有限的数据集然后终止。
根据运行时的不同,应用程序可以通过两种方式打包:
-
托管在maven存储库,文件或HTTP(S)中的Spring Boot uber-jar。
-
Docker图像。
运行时是应用程序执行的位置。应用程序的目标运行时是您可能已用于其他应用程序部署的平台。
支持的平台是:
-
Cloud Foundry
-
Kubernetes
-
本地服务器
| 生产中支持本地服务器以进行任务部署,以替代Spring Batch Admin项目。Stream部署的生产中不支持本地服务器。 |
有一个部署服务提供程序接口(SPI),允许您扩展数据流以部署到其他运行时。社区实施
有两个互斥选项可确定将流应用程序部署到平台的时间。
-
选择面向单个平台的Spring Cloud Data Flow服务器可执行jar。
-
使Spring Cloud Data Flow服务器能够将应用程序的部署和运行时状态委派给Spring Cloud Skipper Server,后者具有部署到多个平台的能力。
选择Spring Cloud Skipper选项还可以在运行时更新和回滚Stream中的应用程序。
数据流服务器还负责:
-
解释和执行流DSL,该流描述通过多个长期存在的应用程序的数据逻辑流。
-
启动一个长期存在的任务应用程序。
-
解释和执行组合任务DSL,描述通过多个短期应用程序的数据逻辑流程。
-
应用描述应用程序到运行时映射的部署清单 - 例如,设置初始实例数,内存要求和数据分区。
-
提供已部署应用程序的运行时状态。
作为示例,用于描述从HTTP源到Apache Cassandra接收器的数据流的流DSL将使用Unix管道和过滤器语法“http | cassandra”来编写。DSL中的每个名称都映射到可以存储Maven或Docker存储库的应用程序。您还可以将申请注册到http位置。许多常见用例(例如JDBC,HDFS,HTTP和路由器)的源,处理器和接收器应用程序由Spring Cloud Data Flow团队提供。管道符号表示通过消息传递中间件在两个应用程序之间进行通信。支持的两个消息传递中间件代理是:
-
Apache Kafka
-
RabbitMQ
在Kafka的情况下,在部署流时,数据流服务器负责创建与每个管道符号对应的主题,并配置每个应用程序以生成或使用主题,从而实现所需的数据流。类似地,对于RabbitMQ,根据需要创建交换和队列以实现期望的流。
主要组件的交互如下图所示:
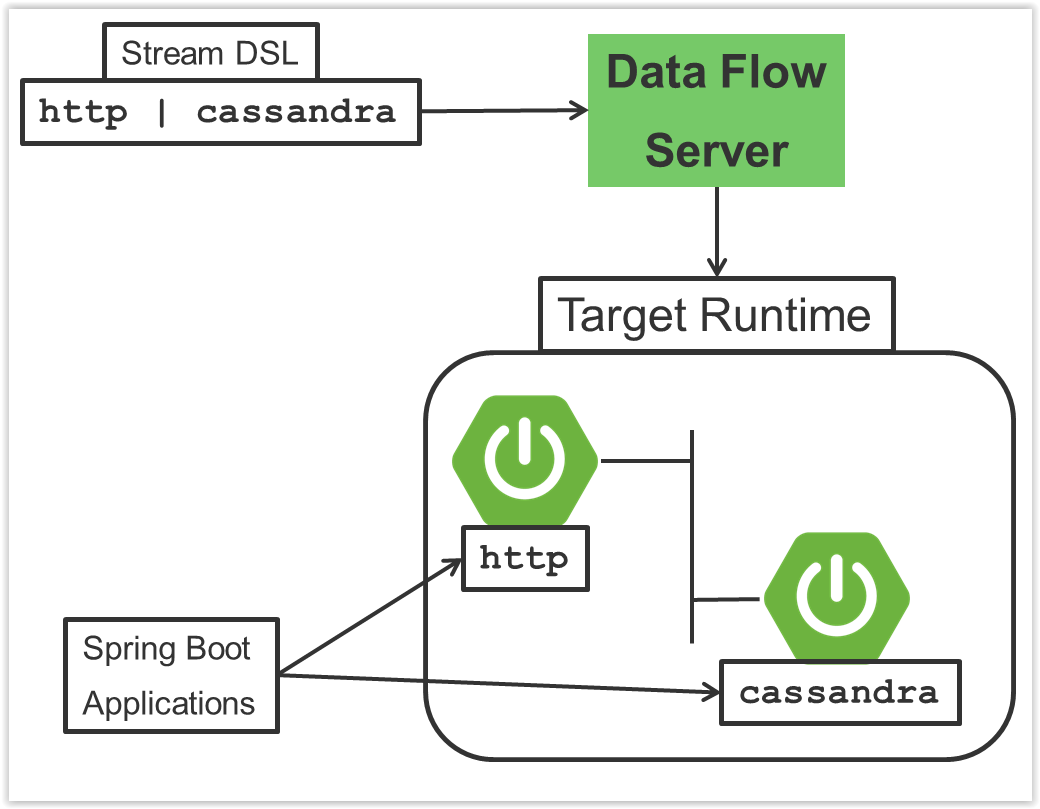
在上图中,流的DSL描述被POST到数据流服务器。基于DSL应用程序名称到Maven和Docker工件的映射,http-source和cassandra-sink应用程序部署在目标运行时上。然后,发布到HTTP应用程序的数据将存储在Cassandra中。的样品Repository显示了在全部细节这种使用情况。
10.微服务架构风格
数据流服务器将应用程序部署到符合微服务架构风格的目标运行时。例如,流表示一个高级应用程序,它由多个小型微服务应用程序组成,每个应用程序都在自己的进程中运行。每个微服务应用程序可以独立于另一个扩展或缩小,并且每个应用程序都有自己的版本控制生命周期。通过使用带有Skipper的数据流,您可以在运行时独立升级或回滚每个应用程序。
Streaming和基于任务的微服务应用程序都基于Spring Boot作为基础库。这为所有微服务应用程序提供了诸如运行状况检查,安全性,可配置日志记录,监视和管理功能以及可执行JAR打包等功能。
需要强调的是,这些微服务应用程序只是“应用程序”,您可以使用java -jar并传递适当的配置属性来自行运行。我们为常见操作提供了许多常见的微服务应用程序,因此在处理基于Spring项目的丰富生态系统的常见用例时,您无需从头开始,例如Spring Integration,Spring Data和Spring Batch。创建自己的微服务应用程序与创建其他Spring Boot应用程序类似。您可以首先使用Spring Initializr web站点来创建基于Stream或任务的微服务的基本支架。
除了将适当的应用程序属性传递给每个应用程序之外,数据流服务器还负责准备目标平台的基础结构,以便可以部署应用程序。例如,在Cloud Foundry中,它会将指定的服务绑定到应用程序,并为每个应用程序执行cf push命令。对于Kubernetes,它将创建复制控制器,服务和负载均衡器。
数据流服务器有助于简化将多个相关应用程序部署到目标运行时,设置必要的输入和输出主题,分区和度量标准功能。但是,也可以选择手动部署每个微服务应用程序,而根本不使用数据流。对于小规模部署而言,这种方法可能更合适,在开发更多应用程序时逐渐采用数据流的便利性和一致性。手动部署基于流和任务的微服务也是一项有用的教育练习,可以帮助您更好地理解数据流服务器提供的一些自动应用程序配置和平台定位步骤。
10.1.与其他平台架构的比较
Spring Cloud Data Flow的架构风格与其他Stream和Batch处理平台不同。例如,在Apache Spark,Apache Flink和Google Cloud Dataflow中,应用程序在专用计算引擎集群上运行。与Spring Cloud Data Flow相比,计算引擎的性质为这些平台提供了更丰富的环境,可以对数据执行复杂的计算,但它引入了创建以数据为中心的应用程序时通常不需要的另一个执行环境的复杂性。这并不意味着您在使用Spring Cloud Data Flow时无法进行实时数据计算。请参阅“ 分析 ”部分,该部分描述了Redis与处理常见的基于计数的用例的集成。Spring Cloud Stream还支持使用Reactive API,例如Project Reactor和RxJava,这对于创建包含时间滑动窗口和移动平均功能的功能样式应用程序非常有用。同样,Spring Cloud Stream也支持使用Kafka Streams API 开发应用程序。
Apache Storm,Hortonworks DataFlow和Spring Cloud Data Flow的前身Spring XD使用专用的应用程序执行集群,该集群对每个产品都是唯一的,它确定代码应在集群上运行的位置并执行运行状况检查以确保如果失败,则重新启动长期应用程序。通常,需要特定于框架的接口才能正确地“插入”到集群的执行框架。
正如我们在Spring XD的发展过程中发现的那样,2015年多个容器框架的兴起使我们自己的运行时创建了重复工作。当有多个运行时平台已经提供此功能时,没有理由构建自己的资源管理机制。考虑到这些因素是我们转向当前架构的原因,我们将执行委托给流行的运行时,您可能已将其用于其他目的。这是一个优势,因为它减少了创建和管理以数据为中心的应用程序的认知距离,因为许多用于部署其他最终用户/ web应用程序的相同技能都适用。
11.数据流服务器
数据流服务器提供以下功能:
11.1.端点
数据流服务器使用嵌入式servlet容器并公开REST端点,用于创建,部署,取消部署和销毁流和任务,查询运行时状态,分析等。数据流服务器通过使用Spring的MVC框架和Spring HATEOAS库来实现,以创建遵循HATEOAS原则的REST表示,如下图所示:
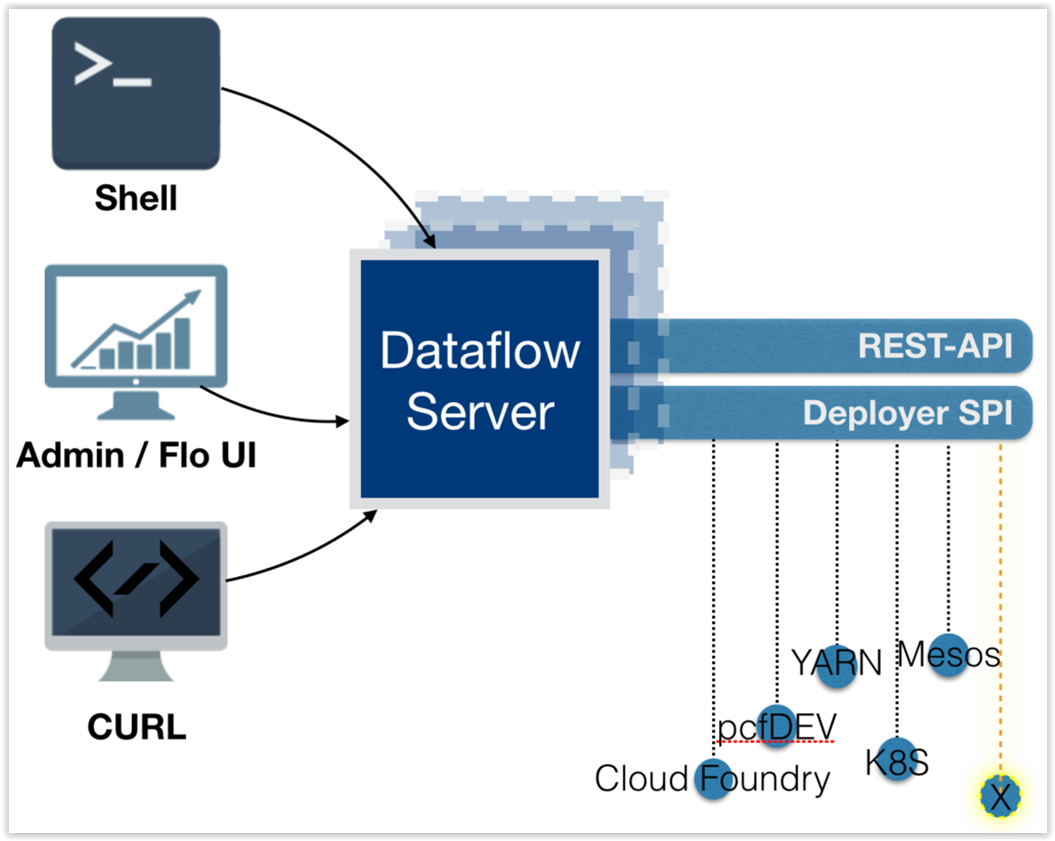
[注意]将应用程序部署到本地计算机的数据流服务器不打算用于流式用例的生产,而是用于开发和测试基于流的应用程序。本地数据流量是打算在生产中使用批量使用情况作为Spring Batch管理项目的替代品。流式和批量使用情况都是在部署到Cloud Foundry或Kuberenetes时用于生产。
11.2.安全
数据流服务器可执行jar支持基本HTTP,LDAP(S),基于文件和OAuth 2.0身份验证以访问其端点。有关更多信息,请参阅安全性部分。
12.流
12.1.拓扑
Stream DSL描述了流经系统的线性数据序列。例如,在流定义http | transformer | cassandra中,每个管道符号将左侧的应用程序连接到右侧的应用程序。命名通道可用于路由和扇出/扇出数据到多个消息传递目的地。
敲击的概念可用于“监听”流过任何管道符号的数据。“Taps”只是其他流,它们使用输入目标流中的任何一个“管道”,并且与目标流具有独立的生命周期。
12.2.并发
对于使用事件的应用程序,Spring Cloud Stream公开了一个并发设置,该设置控制用于调度传入消息的线程池的大小。有关更多信息,请参阅使用者属性文档。
12.3.分区
流处理中的常见模式是在数据从一个应用程序移动到下一个应用程序时对数据进行分区。出于性能或一致性原因,分区是有状态处理中的关键概念,以确保所有相关数据一起处理。例如,在时间窗口平均计算示例中,重要的是来自任何给定传感器的所有测量都由相同的应用实例处理。或者,您可能希望缓存与传入事件相关的一些数据,以便可以在不进行远程过程调用的情况下丰富它以检索相关数据。
Spring Cloud Data Flow通过配置Spring Cloud Stream的输出和输入绑定来支持分区。Spring Cloud Stream提供了一种通用抽象,用于跨不同类型的中间件以统一的方式实现分区处理用例。因此,无论代理本身是自然分区(例如,Kafka主题)还是不分区(RabbitMQ),都可以使用分区。下图显示了如何将数据分区为两个存储区,以便平均处理器应用程序的每个实例都使用一组唯一的数据。
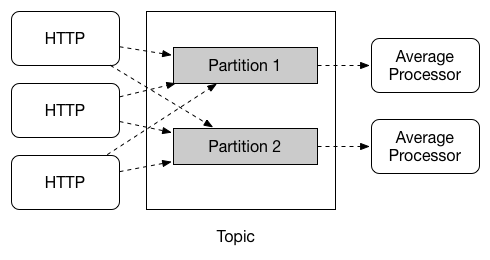
要在Spring Cloud Data Flow中使用简单的分区策略,您只需为流中的每个应用程序设置实例计数,并在部署流时设置partitionKeyExpression生产者属性。partitionKeyExpression标识消息的哪个部分用作分区底层中间件中数据的密钥。ingest流可以定义为http | averageprocessor | cassandra。(请注意,Cassandra接收器未在上图中显示。)假设发送到HTTP源的有效负载是JSON格式,并且有一个名为sensorId的字段。例如,考虑使用shell命令stream deploy ingest --propertiesFile ingestStream.properties部署流的情况,其中ingestStream.properties文件的内容如下:
deployer.http.count=3
deployer.averageprocessor.count=2
app.http.producer.partitionKeyExpression=payload.sensorId结果是部署流,以便配置所有输入和输出目标以使数据流过应用程序,同时确保始终将一组唯一数据传递到每个averageprocessor实例。在这种情况下,默认算法是评估payload.sensorId % partitionCount partitionCount,其中partitionCount是RabbitMQ的应用程序计数,而Kafka是主题的分区计数。
有关在部署期间对流进行分区的其他策略以及它们如何映射到基础Spring Cloud Stream分区属性,请参阅传递流分区Properties。
12.4.消息传递保证
Streams由使用Spring Cloud Stream库作为与底层消息传递中间件产品进行通信的基础的应用程序组成。Spring Cloud Stream还提供了来自多个供应商的中间件的固定配置,特别是提供持久的发布 - 订阅语义。
Spring Cloud Stream中的Binder抽象是将应用程序连接到中间件的原因。绑定器的几个配置属性可以跨所有绑定器实现移植,还有一些属于中间件。
对于使用者应用程序,在消息处理期间生成的异常存在重试策略。通过使用公共使用者属性 maxAttempts,backOffInitialInterval,backOffMaxInterval和backOffMultiplier 配置重试策略。这些属性的默认值重试回调方法调用3次,并等待一秒钟进行第一次重试。退避乘数2用于第二次和第三次尝试。
当重试次数超过maxAttempts值时,异常和失败的消息将成为消息的有效负载,并发送到应用程序的错误通道。默认情况下,此错误通道的默认消息处理程序会记录该消息。您可以通过创建自己的订阅错误通道的消息处理程序来更改应用程序中的默认行为。
13.流编程模型
虽然Spring Boot为创建DevOps友好的微服务应用程序提供了基础,但Spring生态系统中的其他库有助于创建基于流的微服务应用程序。其中最重要的是Spring Cloud Stream。
Spring Cloud Stream编程模型的本质是提供一种简单的方法来描述通过消息传递中间件进行通信的应用程序的多个输入和输出。这些输入和输出映射到Kafka主题或Rabbit交换和队列以及KStream / KTable编程模型。生成数据的Source,消耗和生成数据的处理器以及消耗数据的Sink的常见应用程序配置作为库的一部分提供。
13.1.命令式编程模型
Spring Cloud Stream与Spring Integration的命令式“一次一个事件”编程模型最紧密地结合在一起。这意味着您编写处理单个事件回调的代码,如以下示例所示,
@EnableBinding(Sink.class)
public class LoggingSink {
@StreamListener(Sink.INPUT)
public void log(String message) {
System.out.println(message);
}
}在这种情况下,输入通道上的消息的String有效载荷将传递给log方法。@EnableBinding注释用于将输入通道绑定到外部中间件。
13.2.功能编程模型
但是,Spring Cloud Stream可以支持其他编程样式,例如反应式API,其中传入和传出数据作为连续数据流处理,以及如何处理每个单独的消息。对于许多反应性AOI,您还可以使用描述从入站数据流到出站数据流的功能转换的运算符。这是一个例子:
@EnableBinding(Processor.class)
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Flux<String> receive(@Input(Processor.INPUT) Flux<String> input) {
return input.map(s -> s.toUpperCase());
}
}14.应用程序版本控制
现在,在将数据流与Skipper一起使用时,现在支持在Stream中进行应用程序版本控制。您可以更新应用程序和部署属性以及应用程序的版本。还支持回滚到先前的应用程序版本。
15.任务编程模型
Spring Cloud Task编程模型提供:
-
持久化任务的生命周期事件和退出代码状态。
-
生命周期钩子在任务执行之前或之后执行代码。
-
在任务生命周期中将任务事件发送到流(作为源)的能力。
-
与Spring Batch工作集成。
有关更多信息,请参阅任务部分。
16.分析
17.运行时
数据流服务器依赖于目标平台来实现以下运行时功能:
17.1.容错
数据流支持的目标运行时都能够重新启动长期存在的应用程序。部署应用程序时,运行时环境需要Spring Cloud Data Flow设置运行状况探测器。您还可以自定义运行状况探测器。
组成流的所有应用程序的集合状态用于确定流的状态。如果应用程序失败,则流的状态将从“已部署”更改为“部分”。
17.2.资源管理
每个目标运行时都允许您控制分配给每个应用程序的内存,磁盘和CPU的数量。它们通过使用每个运行时唯一的键名称作为部署清单中的属性传递。有关更多信息,请参阅每个平台的服务器文档。
17.3.在运行时缩放
部署流时,您可以为组成流的每个应用程序设置实例计数。部署流后,每个目标运行时都允许您控制每个应用程序的目标实例数。使用每个运行时的API,UI或命令行工具,您可以根据需要向上或向下扩展实例数。
目前,Kafka绑定器以及分区流不支持运行时扩展,建议的解决方法是使用更新的实例数重新部署流。两种情况都需要根据有关总实例数和当前实例索引的信息来设置静态使用者。
组态
本节介绍如何配置Spring Cloud Data Flow服务器的功能,例如要使用的关系数据库和安全性。它还介绍了如何配置Spring Cloud Data Flow的shell功能。
18.功能切换
Sprig Cloud Data Flow Server提供了一组特定功能,可在启动时启用/禁用。这些功能包括所有生命周期操作和REST端点(服务器和客户端实现,包括shell和UI):
-
流
-
任务
-
Analytics(分析)
-
船长
-
任务计划程序
可以通过在启动数据流服务器时设置以下布尔属性来启用和禁用这些功能:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled -
spring.cloud.dataflow.features.analytics-enabled -
spring.cloud.dataflow.features.skipper-enabled -
spring.cloud.dataflow.features.schedules-enabled
默认情况下,启用流,任务和分析,默认情况下禁用Skipper和Task Scheduler。
由于默认情况下启用了分析功能,因此数据流服务器希望将有效的Redis存储作为分析存储库提供给服务器,因为Spring Cloud Data Flow提供了基于Redis的默认分析实现。这也意味着数据流服务器的health也取决于redis商店的可用性。如果您不希望Data Flow的端点读取写入Redis的分析数据,请通过设置上述属性来禁用分析功能。
|
REST /about端点提供有关已启用和禁用的功能的信息。
19.数据库
关系数据库用于存储流和任务定义以及执行任务的状态。Spring Cloud Data Flow为H2,HSQLDB,MySQL,Oracle,Postgresql,DB2和SqlServer提供模式。服务器启动时会自动创建架构。
默认情况下,Spring Cloud Data Flow提供H2数据库的嵌入式实例。H2数据库有利于开发目的,但不建议用于生产。
MySQL(通过MariaDB驱动程序),HSQLDB,PostgreSQL和嵌入式H2的JDBC驱动程序无需额外配置即可使用。如果您正在使用任何其他数据库,则需要将相应的JDBC驱动程序jar放在服务器的类路径上。
数据库属性可以作为环境变量或命令行参数传递给数据流服务器。
以下示例显示如何使用环境变量定义数据库连接:
export spring_datasource_url=jdbc:postgresql://localhost:5432/mydb
export spring_datasource_username=myuser
export spring_datasource_password=mypass
export spring_datasource_driver_class_name="org.postgresql.Driver"以下示例显示如何使用命令行参数定义MySQL数据库连接
java -jar spring-cloud-dataflow-server-local/target/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar \
--spring.datasource.url=jdbc:mysql://localhost:3306/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=org.mariadb.jdbc.Driver & 以下示例显示如何使用命令行参数定义PostgreSQL数据库连接:
java -jar spring-cloud-dataflow-server-local/target/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar \
--spring.datasource.url=jdbc:postgresql://localhost:5432/mydb \
--spring.datasource.username= \
--spring.datasource.password= \
--spring.datasource.driver-class-name=org.postgresql.Driver & 以下示例显示如何使用命令行参数定义HSQLDB数据库连接:
java -jar spring-cloud-dataflow-server-local/target/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar \
--spring.datasource.url=jdbc:hsqldb://localhost:9001/mydb \
--spring.datasource.username=SA \
--spring.datasource.driver-class-name=org.hsqldb.jdbc.JDBCDriver &
如果您希望使用外部H2数据库实例而不是嵌入Spring Cloud Data Flow的实例,请将spring.dataflow.embedded.database.enabled属性设置为false。如果spring.dataflow.embedded.database.enabled设置为false或者将h2以外的数据库指定为数据源,则嵌入式数据库不会启动。
|
19.1.禁用数据库架构创建和迁移策略
您可以控制数据流是否在启动时引导数据库。在大多数生产环境中,您可能无法获得足够的权限。如果是这种情况,您可以通过将属性spring.cloud.dataflow.rdbms.initialize.enable设置为false来禁用它。可以在spring-cloud-dataflow-core/src/main/resources/文件夹下找到服务器用于引导数据库的脚本。
对于新安装,运行位于/schemas和/migrations.1.x.x下的相应数据库脚本,对于版本1.2.0的升级,您只需运行/migrations.1.x.x脚本。
19.2.添加自定义JDBC驱动程序
要为数据库添加自定义驱动程序(例如,Oracle),您应该重建数据流服务器并将依赖项添加到Maven pom.xml文件。由于每个目标平台都有一个Spring Cloud Data Flow服务器,因此您需要为每个平台修改相应的maven pom.xml。每个服务器版本的每个GitHub存储库中都有标记。
要为本地服务器实现添加自定义JDBC驱动程序依赖项:
-
选择与要重建的服务器版本对应的标记并克隆github存储库。
-
编辑spring-cloud-dataflow-server-local / pom.xml,并在
dependencies部分中添加所需数据库驱动程序的依赖项。在以下示例中,已选择Oracle驱动程序:
<dependencies>
...
<dependency>
<groupId>com.oracle.jdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>12.2.0.1</version>
</dependency>
...
</dependencies>-
构建应用程序,如构建Spring Cloud Data Flow中所述
您还可以通过向dataflow-server.yml文件添加必要的属性来重建服务器时提供默认值,如以下PostgreSQL示例所示:
spring:
datasource:
url: jdbc:postgresql://localhost:5432/mydb
username: myuser
password: mypass
driver-class-name:org.postgresql.Driver20.当地部署人员
您可以使用Data Flow Local服务器部署程序的以下配置属性来自定义应用程序的部署方式:
spring.cloud.deployer.local.workingDirectoriesRoot=java.io.tmpdir # Directory in which all created processes will run and create log files.
spring.cloud.deployer.local.deleteFilesOnExit=true # Whether to delete created files and directories on JVM exit.
spring.cloud.deployer.local.envVarsToInherit=TMP,LANG,LANGUAGE,"LC_.*. # Array of regular expression patterns for environment variables that are passed to launched applications.
spring.cloud.deployer.local.javaCmd=java # Command to run java.
spring.cloud.deployer.local.shutdownTimeout=30 # Max number of seconds to wait for app shutdown.
spring.cloud.deployer.local.javaOpts= # The Java options to pass to the JVM
spring.cloud.deployer.local.freeDiskSpacePercentage=5 # The target percentage of free disk space to always aim for when cleaning downloaded resources (typically via the local maven repository). Specify as an integer greater than zero and less than 100. Default is 5.|
数据流本地服务器本身从其默认值覆盖 |
部署应用程序时,您还可以设置以deployer.<name of application>为前缀的部署程序属性。例如,要在ticktock流中为时间应用程序设置Java选项,请使用以下流部署属性。
dataflow:> stream create --name ticktock --definition "time --server.port=9000 | log"
dataflow:> stream deploy --name ticktock --properties "deployer.time.local.javaOpts=-Xmx2048m -Dtest=foo"为方便起见,您可以设置deployer.memory属性以设置Java选项-Xmx,如以下示例所示:
dataflow:> stream deploy --name ticktock --properties "deployer.time.memory=2048m"在部署时,如果在deployer.<app>.local.javaOpts属性中指定-Xmx选项以及deployer.<app>.local.memory选项的值,则javaOpts属性中的值具有优先权。此外,部署应用程序时设置的javaOpts属性优先于数据流服务器的spring.cloud.deployer.local.javaOpts属性。
21. Maven
如果要覆盖特定的maven配置属性(远程存储库,代理和其他)或在代理后面运行数据流服务器,则需要在启动数据流服务器时将这些属性指定为命令行参数,如下所示例:
$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --maven.localRepository=mylocal
--maven.remote-repositories.repo1.url=https://repo1
--maven.remote-repositories.repo1.auth.username=user1
--maven.remote-repositories.repo1.auth.password=pass1
--maven.remote-repositories.repo1.snapshot-policy.update-policy=daily
--maven.remote-repositories.repo1.snapshot-policy.checksum-policy=warn
--maven.remote-repositories.repo1.release-policy.update-policy=never
--maven.remote-repositories.repo1.release-policy.checksum-policy=fail
--maven.remote-repositories.repo2.url=https://repo2
--maven.remote-repositories.repo2.policy.update-policy=always
--maven.remote-repositories.repo2.policy.checksum-policy=fail
--maven.proxy.host=proxy1
--maven.proxy.port=9010 --maven.proxy.auth.username=proxyuser1
--maven.proxy.auth.password=proxypass1默认情况下,协议设置为http。如果代理不需要用户名和密码,则可以省略auth属性。此外,maven localRepository默认设置为${user.home}/.m2/repository/。如前面的示例所示,可以指定远程存储库及其身份验证(如果需要)。如果远程存储库位于代理后面,则可以指定代理属性,如上例所示。
可以为每个远程存储库配置指定存储库策略,如上例所示。密钥policy适用于snapshot和release存储库策略。
您可以参考Repository策略以获取支持的存储库策略列表。
由于它们是Spring Boot @ConfigurationProperties,您还可以将它们指定为环境变量,例如MAVEN_REMOTE_REPOSITORIES_REPO1_URL。另一个常见选项是通过设置SPRING_APPLICATION_JSON环境变量来设置属性。以下示例显示了JSON的结构:
$ SPRING_APPLICATION_JSON='{ "maven": { "local-repository": null,
"remote-repositories": { "repo1": { "url": "https://repo1", "auth": { "username": "repo1user", "password": "repo1pass" } }, "repo2": { "url": "https://repo2" } },
"proxy": { "host": "proxyhost", "port": 9018, "auth": { "username": "proxyuser", "password": "proxypass" } } } }' java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar22.本地数据流服务器日志记录配置
Spring Cloud Data Flow local服务器配置为使用RollingFileAppender进行日志记录。
logging: config: classpath:logback-scdf-local.xml
默认情况下,日志文件配置为使用:
<property name="LOG_FILE" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/spring-cloud-dataflow-server-local}"/>使用RollingPolicy的logback配置:
<appender name="FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.log</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- daily rolling -->
<fileNamePattern>${LOG_FILE}.${LOG_FILE_ROLLING_FILE_NAME_PATTERN:-%d{yyyy-MM-dd}}.%i.gz</fileNamePattern>
<maxFileSize>${LOG_FILE_MAX_SIZE:-100MB}</maxFileSize>
<maxHistory>${LOG_FILE_MAX_HISTORY:-30}</maxHistory>
<totalSizeCap>${LOG_FILE_TOTAL_SIZE_CAP:-500MB}</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
要检查当前Spring Cloud Data Flow服务器local服务器的java.io.tmpdir,
jinfo <pid> | grep "java.io.tmpdir"如果您想更改或覆盖任何属性LOG_FILE,LOG_PATH,LOG_TEMP,LOG_FILE_MAX_SIZE,LOG_FILE_MAX_HISTORY和LOG_FILE_TOTAL_SIZE_CAP,请将它们设置为系统属性。
23.船长
要使用Stream更新和回滚等功能,Data Flow Server会委托Skipper服务器来管理Stream的生命周期。将配置属性spring.cloud.skipper.client.serverUri设置为Skipper的位置,例如
+
$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --spring.cloud.skipper.client.serverUri=http://192.51.100.1:7577/api --spring.cloud.dataflow.features.skipper-enabled=true24.安全
默认情况下,数据流服务器是不安全的,并在未加密的HTTP连接上运行。您可以通过启用HTTPS并要求客户端使用以下任一方法进行身份验证来保护您的REST端点以及数据流仪表板:
-
传统认证(包括基本认证)
下图显示了Spring Cloud Data Flow服务器的身份验证选项:

选择传统身份验证时,Spring Cloud Data Flow服务器是主要身份验证点,使用Spring Security。选择此选项后,用户需要通过选择所需的身份验证后备存储来进一步定义其首选身份验证机制,该存储可以是以下选项之一:
在传统身份验证或OAuth2之间进行选择时,请记住这两个选项是互斥的。有关更详细的讨论,请参阅以下部分。
|
默认情况下,REST端点(管理,管理和运行状况)以及仪表板UI不需要经过身份验证的访问。 |
24.1.启用HTTPS
默认情况下,仪表板,管理和运行状况端点使用HTTP作为传输。您可以通过在application.yml中为配置添加证书来切换到HTTPS,如以下示例所示:
server:
port: 8443 (1)
ssl:
key-alias: yourKeyAlias (2)
key-store: path/to/keystore (3)
key-store-password: yourKeyStorePassword (4)
key-password: yourKeyPassword (5)
trust-store: path/to/trust-store (6)
trust-store-password: yourTrustStorePassword (7)| 1 | 由于默认端口为9393,您可以选择将端口更改为更常见的HTTPs典型端口。 |
| 2 | 密钥存储在密钥库中的别名(或名称)。 |
| 3 | 密钥库文件的路径。也可以使用类路径前缀指定类路径资源 - 例如:classpath:path/to/keystore。 |
| 4 | 密钥库的密码。 |
| 5 | 密钥的密码。 |
| 6 | 信任库文件的路径。也可以使用类路径前缀指定类路径资源 - 例如:classpath:path/to/trust-store |
| 7 | 信任存储的密码。 |
| 如果启用了HTTPS,它将完全替换HTTP作为REST端点和数据流仪表板交互的协议。普通HTTP请求将失败。因此,请确保相应地配置Shell。 |
24.1.1.使用自签名证书
出于测试目的或在开发期间,创建自签名证书可能会很方便。要开始,请执行以下命令以创建证书:
$ keytool -genkey -alias dataflow -keyalg RSA -keystore dataflow.keystore \
-validity 3650 -storetype JKS \
-dname "CN=localhost, OU=Spring, O=Pivotal, L=Kailua-Kona, ST=HI, C=US" (1)
-keypass dataflow -storepass dataflow| 1 | CN是这里的重要参数。它应该与您尝试访问的域匹配 - 例如,localhost。 |
然后将以下行添加到application.yml文件中:
server:
port: 8443
ssl:
enabled: true
key-alias: dataflow
key-store: "/your/path/to/dataflow.keystore"
key-store-type: jks
key-store-password: dataflow
key-password: dataflow这就是数据流服务器所需的全部内容。启动服务器后,您应该能够在localhost:8443/访问它。由于这是一个自签名证书,您应该在浏览器中发出警告,您需要忽略该警告。
24.1.2.自签证书和壳牌
默认情况下,自签名证书是shell的问题,并且必须执行其他步骤才能使shell使用自签名证书。有两种选择:
-
将自签名证书添加到JVM信任库。
-
跳过证书验证。
将自签名证书添加到JVM信任库
为了使用JVM信任库选项,我们需要从密钥库导出以前创建的证书,如下所示:
$ keytool -export -alias dataflow -keystore dataflow.keystore -file dataflow_cert -storepass dataflow接下来,我们需要创建一个shell可以使用的信任库,如下所示:
$ keytool -importcert -keystore dataflow.truststore -alias dataflow -storepass dataflow -file dataflow_cert -noprompt现在,您已准备好使用以下JVM参数启动数据流Shell:
$ java -Djavax.net.ssl.trustStorePassword=dataflow \
-Djavax.net.ssl.trustStore=/path/to/dataflow.truststore \
-Djavax.net.ssl.trustStoreType=jks \
-jar spring-cloud-dataflow-shell-1.7.3.RELEASE.jar|
如果您在通过SSL建立连接时遇到问题,可以通过使用 |
不要忘记使用以下内容定位数据流服务器:
dataflow:> dataflow config server https://localhost:8443/跳过证书验证
或者,您也可以通过提供可选的命令行参数--dataflow.skip-ssl-validation=true来绕过认证验证。
如果设置此命令行参数,则shell将接受任何(自签名)SSL证书。
|
如果可能,您应该避免使用此选项。禁用信任管理器会破坏SSL的目的,使您容易受到中间人攻击。 |
24.2.传统认证
使用传统身份验证时,Spring Cloud Data Flow是唯一的身份验证提供程序。在这种情况下,Data Flow REST API用户将使用 基本身份验证 来访问端点。
使用该选项时,用户可以选择三个后备存储来获取身份验证详细信息:
-
通过设置Spring Boot属性进行单用户身份验证
-
使用Yaml文件为多个用户进行基于文件的身份验证
-
Ldap身份验证
24.2.1.单用户身份验证
这是最简单的选项,可模拟默认Spring Boot用户体验的行为。可以通过设置环境变量或将以下内容添加到application.yml来启用它:
security:
basic:
enabled: true (1)
realm: Spring Cloud Data Flow (2)| 1 | 启用基本身份验证。必须设置为true才能启用安全性。 |
| 2 | (可选)基本身份验证的领域。如果没有明确设置,则默认为Spring。 |
| 当前版本的Chrome不显示该领域。有关更多信息,请参阅以下 Chromium问题单。 |
在此用例中,底层Spring Boot使用自动生成的密码自动创建名为user的用户,该密码在启动时打印到控制台。
使用此设置,生成的用户将分配所有主要角色,如下所示:
-
视图
-
创建
-
管理
下图显示了控制台中显示的默认Spring Boot用户凭据。

您可以通过设置以下属性来自定义用户:
security.user.name=user # Default user name.
security.user.password= # Password for the default user name. A random password is logged on startup by default.
security.user.role=VIEW,CREATE,MANAGE # Granted roles for the default user name.| 请注意基本身份验证和注销的固有问题:浏览器缓存凭据,只需浏览到应用程序页面即可重新登录。 |
当然,您也可以通过设置系统属性,环境变量或命令行参数来传递凭据,因为这是标准的Spring Boot行为。例如,在以下示例中,命令行参数用于指定用户凭据:
$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar\
--security.basic.enabled=true \
--security.user.name=test \
--security.user.password=pass \
--security.user.role=VIEW如果您需要定义多个基于文件的用户帐户,请查看基于文件的身份验证。
24.2.2.基于文件的身份验证
默认情况下,Spring Boot允许您仅指定一个用户。Spring Cloud数据流还支持在配置文件中列出多个用户。必须为每个用户分配密码和一个或多个角色。以下示例显示了其他用户的创建:
security:
basic:
enabled: true
realm: Spring Cloud Data Flow
spring:
cloud:
dataflow:
security:
authentication:
file:
enabled: true (1)
users: (2)
bob: bobspassword, ROLE_MANAGE (3)
alice: alicepwd, ROLE_VIEW, ROLE_CREATE| 1 | 启用基于文件的身份验证。 |
| 2 | 这是用户名到密码的yaml地图。 |
| 3 | 每个映射value由相应的密码和角色组成,以逗号分隔。 |
24.2.3.LDAP身份验证
Spring Cloud Data Flow还支持对LDAP(轻量级目录访问协议)服务器的身份验证,为以下模式提供支持:
-
直接绑定
-
搜索并绑定
激活LDAP身份验证选项后,将关闭默认的单用户模式。
在直接绑定模式下,使用用户名的占位符为用户的可分辨名称(DN)定义模式。身份验证过程通过替换占位符并使用它来针对LDAP服务器对用户进行身份验证以及提供的密码来派生用户的可分辨名称。您可以按如下方式设置LDAP直接绑定:
security:
basic:
enabled: true
realm: Spring Cloud Data Flow
spring:
cloud:
dataflow:
security:
authentication:
ldap:
enabled: true (1)
url: ldap://ldap.example.com:3309 (2)
userDnPattern: uid={0},ou=people,dc=example,dc=com (3)| 1 | 启用LDAP身份验证 |
| 2 | LDAP服务器的URL |
| 3 | 用于对服务器进行身份验证的可分辨名称(DN)模式 |
搜索和绑定模式涉及以匿名方式或使用固定帐户连接到LDAP服务器,根据用户名搜索身份验证用户的可分辨名称,然后使用结果值和提供的密码绑定到LDAP服务器。此选项配置如下:
security:
basic:
enabled: true
realm: Spring Cloud Data Flow
spring:
cloud:
dataflow:
security:
authentication:
ldap:
enabled: true (1)
url: ldap://localhost:10389 (2)
managerDn: uid=admin,ou=system (3)
managerPassword: secret (4)
userSearchBase: ou=otherpeople,dc=example,dc=com (5)
userSearchFilter: uid={0} (6)| 1 | 启用LDAP集成 |
| 2 | LDAP服务器的URL |
| 3 | 如果不支持匿名搜索,则对LDAP服务器进行身份验证的DN(可选,需要与下一个选项一起使用) |
| 4 | 如果不支持匿名搜索,则为LDAP服务器进行身份验证的密码(可选,与先前选项一起使用) |
| 5 | 搜索身份验证用户DN的基础(用于限制搜索范围) |
| 6 | 验证用户的DN的搜索过滤器 |
| 有关详细信息,另请参阅 Spring Security参考指南的 LDAP身份验证章节。 |
LDAP角色映射
默认情况下,从Ldap检索的角色名称需要与Spring Cloud Data Flow中角色的名称匹配。但是,也可以显式提供LDAP角色和Spring Cloud Data Flow角色之间的映射。
security:
basic:
enabled: true
realm: Spring Cloud Data Flow
spring:
cloud:
dataflow:
security:
authentication:
ldap:
enabled: true
url: ldap://localhost:10389
managerDn: uid=admin,ou=system
managerPassword: secret
userSearchBase: ou=otherpeople,dc=example,dc=com
userSearchFilter: uid={0}
roleMappings: (1)
ROLE_MANAGE: foo-manage (2)
ROLE_VIEW: bar-view
ROLE_CREATE: foo-manage| 1 | 启用显式角色映射支持 |
| 2 | 启用角色映射支持后,必须为所有3个Spring Cloud Data Flow角色ROLE_MANAGE,ROLE_VIEW,ROLE_CREATE提供映射。 |
LDAP传输安全性
连接到LDAP服务器时,通常(在LDAP世界中)有两个选项可以安全地建立与LDAP服务器的连接:
-
LDAP over SSL(LDAPs)
-
启动传输层安全性(启动TLS在RFC2830中定义)
从Spring Cloud Data Flow 1.1.0开始,只支持开箱即用的LDAP。使用官方证书时,无需通过LDAP连接LDAP服务器进行特殊配置。您只需将url格式更改为ldaps - 例如:ldaps://localhost:636。
对于自签名证书,Spring Cloud Data Flow服务器的设置会稍微复杂一些。该设置与使用自签名证书非常相似 (请先阅读),Spring Cloud Data Flow需要引用trustStore才能使用自签名证书。
| 虽然在开发和测试期间很有用,但永远不要在生产中使用自签名证书! |
最终,您必须提供一组系统属性,以便在启动服务器时引用trustStore及其凭据,如下所示:
$ java -Djavax.net.ssl.trustStorePassword=dataflow \
-Djavax.net.ssl.trustStore=/path/to/dataflow.truststore \
-Djavax.net.ssl.trustStoreType=jks \
-jar spring-cloud-starter-dataflow-server-local-1.7.3.RELEASE.jar如前所述,安全连接到LDAP服务器的另一个选项是Start TLS。在LDAP世界中,技术上甚至认为LDAP不赞成使用Start TLS。但是,Spring Cloud Data Flow目前不支持此选项。
请按照以下问题跟踪器票据来跟踪其实施情况。您可能还需要查看有关自定义DirContext身份验证处理的Spring LDAP参考文档章节以 获取更多详细信息。
24.2.4.Shell身份验证
使用传统身份验证与数据流Shell时,通常使用命令行参数提供用户名和密码,如以下示例所示:
$ java -jar target/spring-cloud-dataflow-shell-1.7.3.RELEASE.jar \
--dataflow.username=myuser \ (1)
--dataflow.password=mysecret (2)| 1 | 如果启用了身份验证,则必须提供用户名。 |
| 2 | 如果未提供密码,则shell会提示输入密码。 |
或者,您也可以从shell中定位数据流服务器,如下所示:
server-unknown:>dataflow config server
--uri http://localhost:9393 \ (1)
--username myuser \ (2)
--password mysecret \ (3)
--skip-ssl-validation true \ (4)| 1 | 可选,默认为localhost:9393。 |
| 2 | 如果启用安全性,则必须提供。 |
| 3 | 如果启用了安全性,并且未提供密码,则会提示用户输入密码。 |
| 4 | 可选,忽略证书错误(使用自签名证书时)。谨慎使用! |
下图显示了连接和验证数据流服务器的典型shell命令:

24.2.5.自定义授权
前面的内容涉及身份验证 - 即如何评估用户的身份。无论选择何种选项,您还可以自定义授权 - 即谁可以做什么。
默认方案使用三个角色来保护 Spring Cloud Data Flow公开的REST端点:
-
ROLE_VIEW用于检索状态的任何内容
-
任何涉及创建,删除或改变系统状态的ROLE_CREATE
-
ROLE_MANAGE用于启动管理端点
所有这些默认值都在dataflow-server-defaults.yml中指定,它是Spring Cloud Data Flow核心模块的一部分。尽管如此,如果需要,您可以覆盖它们 - 例如,在application.yml中。配置采用YAML列表的形式(因为某些规则可能优先于其他规则)。因此,您需要复制并粘贴整个列表并根据您的需要进行定制(因为无法合并列表)。
请始终参考您的application.yml版本,因为以下代码段可能已过时。
|
默认规则如下:
spring:
cloud:
dataflow:
security:
authorization:
enabled: true
rules:
# Metrics
- GET /metrics/streams => hasRole('ROLE_VIEW')
# About
- GET /about => hasRole('ROLE_VIEW')
# Metrics
- GET /metrics/** => hasRole('ROLE_VIEW')
- DELETE /metrics/** => hasRole('ROLE_CREATE')
# Boot Endpoints
- GET /management/** => hasRole('ROLE_MANAGE')
# Apps
- GET /apps => hasRole('ROLE_VIEW')
- GET /apps/** => hasRole('ROLE_VIEW')
- DELETE /apps/** => hasRole('ROLE_CREATE')
- POST /apps => hasRole('ROLE_CREATE')
- POST /apps/** => hasRole('ROLE_CREATE')
# Completions
- GET /completions/** => hasRole('ROLE_CREATE')
# Job Executions & Batch Job Execution Steps && Job Step Execution Progress
- GET /jobs/executions => hasRole('ROLE_VIEW')
- PUT /jobs/executions/** => hasRole('ROLE_CREATE')
- GET /jobs/executions/** => hasRole('ROLE_VIEW')
# Batch Job Instances
- GET /jobs/instances => hasRole('ROLE_VIEW')
- GET /jobs/instances/* => hasRole('ROLE_VIEW')
# Running Applications
- GET /runtime/apps => hasRole('ROLE_VIEW')
- GET /runtime/apps/** => hasRole('ROLE_VIEW')
# Stream Definitions
- GET /streams/definitions => hasRole('ROLE_VIEW')
- GET /streams/definitions/* => hasRole('ROLE_VIEW')
- GET /streams/definitions/*/related => hasRole('ROLE_VIEW')
- POST /streams/definitions => hasRole('ROLE_CREATE')
- DELETE /streams/definitions/* => hasRole('ROLE_CREATE')
- DELETE /streams/definitions => hasRole('ROLE_CREATE')
# Stream Deployments
- DELETE /streams/deployments/* => hasRole('ROLE_CREATE')
- DELETE /streams/deployments => hasRole('ROLE_CREATE')
- POST /streams/deployments/* => hasRole('ROLE_CREATE')
# Stream Validations
- GET /streams/validation/ => hasRole('ROLE_VIEW')
- GET /streams/validation/* => hasRole('ROLE_VIEW')
# Task Definitions
- POST /tasks/definitions => hasRole('ROLE_CREATE')
- DELETE /tasks/definitions/* => hasRole('ROLE_CREATE')
- GET /tasks/definitions => hasRole('ROLE_VIEW')
- GET /tasks/definitions/* => hasRole('ROLE_VIEW')
# Task Executions
- GET /tasks/executions => hasRole('ROLE_VIEW')
- GET /tasks/executions/* => hasRole('ROLE_VIEW')
- POST /tasks/executions => hasRole('ROLE_CREATE')
- DELETE /tasks/executions/* => hasRole('ROLE_CREATE')
# Task Schedules
- GET /tasks/schedules => hasRole('ROLE_VIEW')
- GET /tasks/schedules/* => hasRole('ROLE_VIEW')
- POST /tasks/schedules => hasRole('ROLE_CREATE')
- DELETE /tasks/schedules/* => hasRole('ROLE_CREATE')
# Task Validations
- GET /tasks/validation/ => hasRole('ROLE_VIEW')
- GET /tasks/validation/* => hasRole('ROLE_VIEW')
# Tools
- POST /tools/** => hasRole('ROLE_CREATE')每行的格式如下:
HTTP_METHOD URL_PATTERN '=>' SECURITY_ATTRIBUTE
哪里
-
HTTP_METHOD是一种http方法,大写情况
-
URL_PATTERN是一种Ant样式的URL模式
-
SECURITY_ATTRIBUTE是一个SpEL表达式。请参阅基于表达式的访问控制。
-
每个由一个或几个空白字符(空格,制表符等)分隔的字符串
请注意,上面确实是一个YAML列表,而不是一个映射(因此在每行的开头使用' - '破折号),它位于spring.cloud.dataflow.security.authorization.rules键下。
|
如果您只对身份验证感兴趣而不是授权(例如,每个用户都可以访问所有端点),那么您也可以设置 |
如果通过设置安全性属性来使用基本安全性配置,则为用户设置角色很重要,如以下示例所示:
java -jar spring-cloud-dataflow-server-local/target/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar \
--security.basic.enabled=true \
--security.user.name=test \
--security.user.password=pass \
--security.user.role=VIEW24.2.6.授权 - Shell和Dashboard行为
启用授权后,仪表板和shell将具有角色感知功能,这意味着,根据分配的角色,并非所有功能都可见。
例如,用户没有必要角色的shell命令被标记为不可用。
|
目前,shell的 |
同样,对于仪表板,UI不显示未授权用户的页面或页面元素。
24.2.7.使用LDAP授权
配置LDAP进行身份验证时,您还可以将group-role-attribute与group-search-base和group-search-filter一起指定。
组角色属性包含角色的名称。如果未指定,则默认填充ROLE_MANAGE角色。
有关详细信息,请参阅Spring Security参考指南中的配置LDAP服务器。
24.3.OAuth 2.0
OAuth 2.0允许您将Spring Cloud数据流集成到单点登录(SSO)环境中。使用以下OAuth2授权类型:
-
授权码:用于GUI(浏览器)集成。访问者将重定向到您的OAuth服务以进行身份验证
-
密码:由shell(以及REST集成)使用,因此访问者可以使用用户名和密码登录
-
客户端凭据:直接从OAuth提供程序检索访问令牌,并使用Authorization HTTP标头将其传递到数据流服务器
可以通过两种方式访问REST端点:
-
基本身份验证,使用封面下的密码授予类型对您的OAuth2服务进行身份验证
-
访问令牌,使用封面下的客户端凭据授予类型
| 设置身份验证时,强烈建议您也启用HTTPS,尤其是在生产环境中。 |
您可以通过将以下内容添加到application.yml或通过设置环境变量来启用OAuth2身份验证:
security:
oauth2:
client:
client-id: myclient (1)
client-secret: mysecret
access-token-uri: http://127.0.0.1:9999/oauth/token
user-authorization-uri: http://127.0.0.1:9999/oauth/authorize
resource:
user-info-uri: http://127.0.0.1:9999/me| 1 | 在OAuth配置部分中提供客户端ID可激活OAuth2安全性 |
您可以使用curl验证基本身份验证是否正常工作,如下所示:
$ curl -u myusername:mypassword http://localhost:9393/ -H 'Accept: application/json'因此,您应该看到可用REST端点的列表。
请注意,使用web浏览器访问根URL并启用安全性时,您将被重定向到仪表板UI。要查看REST端点列表,请指定application/json。另外,请务必使用Postman(Chrome)或RESTClient(Firefox)等工具添加Accept标头。
|
除基本身份验证外,您还可以提供访问令牌以访问REST Api。为了实现这一点,您首先要从OAuth2提供程序检索OAuth2访问令牌,然后使用Authorization Http标头将该访问令牌传递给REST Api :
$ curl -H "Authorization: Bearer <ACCESS_TOKEN>" http://localhost:9393/ -H 'Accept: application/json'24.3.1.OAuth REST端点授权
OAuth2身份验证选项使用与传统身份验证选项相同的授权规则 。
|
授权规则在 |
由于安全角色的确定是特定于环境的,因此默认情况下,Spring Cloud Data Flow会使用DefaultDataflowAuthoritiesExtractor类将所有角色分配给经过身份验证的OAuth2用户。
您可以通过提供扩展Spring Security OAuth的AuthoritiesExtractor接口的自己的Spring bean定义来自定义该行为。在这种情况下,自定义bean定义优先于Spring Cloud Data Flow提供的默认定义。
24.3.2.使用Spring Cloud Data Flow Shell进行OAuth身份验证
使用命令行管理程序时,可以通过用户名和密码或通过指定credentials-provider命令来提供凭据。
如果您的OAuth2提供程序支持密码授予类型,则可以使用以下命令启动 数据流Shell:
$ java -jar spring-cloud-dataflow-shell-1.7.3.RELEASE.jar \
--dataflow.uri=http://localhost:9393 \
--dataflow.username=my_username --dataflow.password=my_password| 请记住,启用Spring Cloud Data Flow身份验证后,如果要通过用户名/密码身份验证使用命令行管理程序,则底层OAuth2提供程序必须支持密码 OAuth2授权类型。 |
在数据流Shell中,您还可以使用以下命令提供凭据:
dataflow config server --uri http://localhost:9393 --username my_username --password my_password成功定位后,您应该看到以下输出:
dataflow:>dataflow config info
dataflow config info
╔═══════════╤═══════════════════════════════════════╗
║Credentials│[username='my_username, password=****']║
╠═══════════╪═══════════════════════════════════════╣
║Result │ ║
║Target │http://localhost:9393 ║
╚═══════════╧═══════════════════════════════════════╝或者,您可以指定credentials-provider命令以直接传入承载令牌,而不是提供用户名和密码。这可以在shell中运行,也可以在启动Shell时提供--dataflow.credentials-provider-command命令行参数。
|
使用credentials-provider命令时,请注意您的指定命令必须返回Bearer令牌(以Bearer为前缀的访问令牌)。例如,在Unix环境中,可以使用以下简单命令: |
24.3.3.OAuth2身份验证示例
本节提供以下身份验证示例:
本地OAuth2服务器
使用Spring Security OAuth,您可以使用以下简单注释轻松创建自己的OAuth2服务器:
-
@EnableResourceServer -
@EnableAuthorizationServer
可以在以下位置找到工作示例应用程序:
克隆项目并使用相应的客户端ID和客户端密钥配置Spring Cloud数据流。然后构建并启动项目。
使用GitHub进行身份验证
如果您想使用现有的OAuth2提供程序,以下是GitHub的示例。首先,您需要在GitHub帐户下注册一个新的应用程序:
在本地运行默认版本的Spring Cloud Data Flow时,您的GitHub配置应如下图所示:
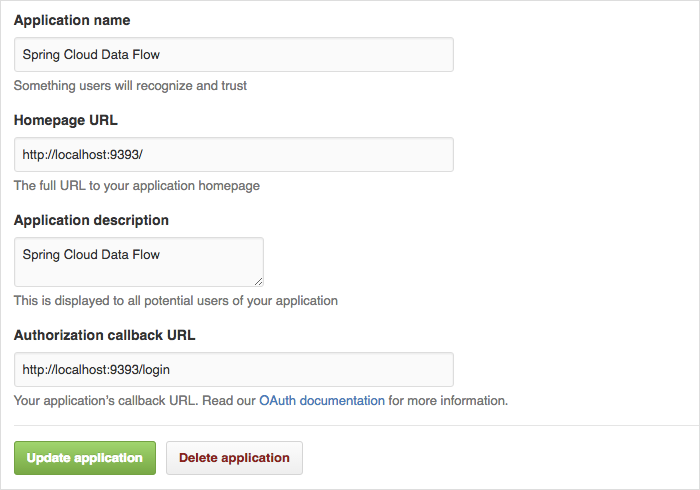
对于授权回调URL,请输入Spring Cloud Data Flow的登录URL - 例如,localhost:9393/login。
|
使用GitHub相关的客户端ID和密钥配置Spring Cloud Data Flow,如下所示:
security:
oauth2:
client:
client-id: your-github-client-id
client-secret: your-github-client-secret
access-token-uri: https://github.com/login/oauth/access_token
user-authorization-uri: https://github.com/login/oauth/authorize
resource:
user-info-uri: https://api.github.com/user| GitHub不支持OAuth2密码授予类型。因此,您不能将Spring Cloud Data Flow Shell与GitHub结合使用。 |
24.4.保护Spring Boot管理端点
启用安全性时,还请确保Spring Boot HTTP管理端点
也是安全的。您可以通过将以下内容添加到application.yml来为管理端点启用安全性:
management:
contextPath: /management
security:
enabled: true
如果未明确启用管理端点的安全性,则最终可能会有不安全的REST端点,尽管security.basic.enabled设置为true。
|
25.监测和管理
Spring Cloud Data Flow服务器是Spring Boot 1.5应用程序,包括Actuator库,它添加了几个生产就绪功能,以帮助您监视和管理您的应用程序。
Actuator库在上下文路径/management下添加HTTP端点,这是可用管理端点的发现页面。例如,有一个显示应用程序运行状况信息的health端点和一个列出Spring ConfigurableEnvironment属性的env。默认情况下,只能访问运行状况和应用程序信息端点。其他端点被认为是敏感的,需要通过配置明确启用。如果启用敏感端点,则还应保护数据流服务器的端点,以便不会无意中向未经身份验证的用户公开信息。默认情况下,本地数据流服务器已禁用安全性,因此所有执行器端点均可用。
数据流服务器需要关系数据库,如果启用了分析功能切换,则还需要Redis服务器。如果需要,数据流服务器会自动配置DataSourceHealthIndicator和RedisHealthIndicator。这两个服务的运行状况通过health端点合并到服务器的整体运行状况。
25.1.监控已部署的流应用程序
Spring Cloud Data Flow部署的流应用程序可以基于Spring Boot 1.5或Spring Boot 2.0。两个版本都包含几个用于监视生产中的应用程序的功能 但是,Spring Boot 1.x和2.x以及Spring Cloud Stream 1.x和2.x在实施监控方面存在差异。由于Spring Cloud Data Flow支持部署1.x和2.x应用程序,因此我们将单独介绍这两种情况。
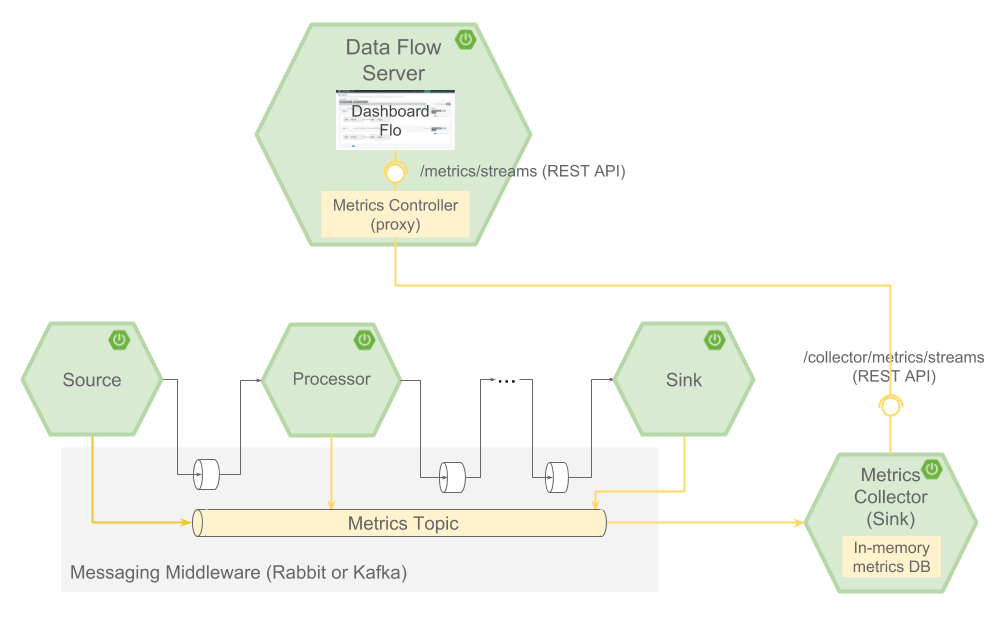
1.x和2.x应用程序的共同点是Spring Cloud Stream应用程序可以配置为将度量标准发布到消息传递中间件目标。的Spring Cloud Data Flow度量收集器所预订到该目标并聚集度量成基于流的图。Metrics Collector 2.0服务器支持从仅包含Boot 1.x或2.x应用程序的流以及包含Boot版本混合的流中收集度量标准。数据流UI通过HTTP查询Metrics收集器,以显示每个已部署应用程序旁边的消息速率。
下图显示了使用Spring Cloud Stream度量标准发布者,度量标准收集器和数据流服务器时的体系结构:
25.1.1.使用Metrics Collector
Metrics Collector有两个版本,一个基于Spring Boot 1.0的1.0版本,它了解如何聚合来自Spring Boot 1.x应用程序的指标和基于Spring Boot 2.0的2.0版本,它们了解如何聚合来自Spring Boot 1.x和2.x的指标。Rabbit和Kafka有一个Metrics Collector服务器。您可以在其项目页面上找到有关下载和运行Metrics Collector的更多信息。
数据流服务器属性:spring.cloud.dataflow.metrics.collector.uri引用Metrics Collector的URI。例如,如果在端口8080上本地运行Metrics Collector,则启动本地数据流服务器以引用Metrics Collector。
$ java -jar spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --spring.cloud.dataflow.metrics.collector.uri=http://localhost:8080可以使用需要用户名和密码的“基本”身份验证来保护Metrics Collector。要设置用户名和密码,请在启动数据流服务器时使用属性spring.cloud.dataflow.metrics.collector.username和spring.cloud.dataflow.metrics.collector.password。
设置属性spring.cloud.stream.bindings.applicationMetrics.destination时,将发布每个应用程序的度量标准。使用目标名称metrics是一个不错的选择,因为Metrics Collector默认订阅该名称。
由于希望Data Flow部署的所有流应用程序都能发出指标,因此设置属性非常普遍:
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.bindings.applicationMetrics.destination=metrics在Data Flow服务器上,您可以在一个中心位置配置对度量标准发布的支持。
使用目标名称metrics是一个不错的选择,因为Metrics Collector默认订阅该名称,当然,可以根据需要将其覆盖为与默认值不同。
配置度量目标的下一个最常用方法是使用部署属性。以下示例显示了使用App Starters time和log应用程序的ticktock流:
app register --name time --type source --uri maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE
app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.0.RELEASE
stream create --name foostream --definition "time | log"
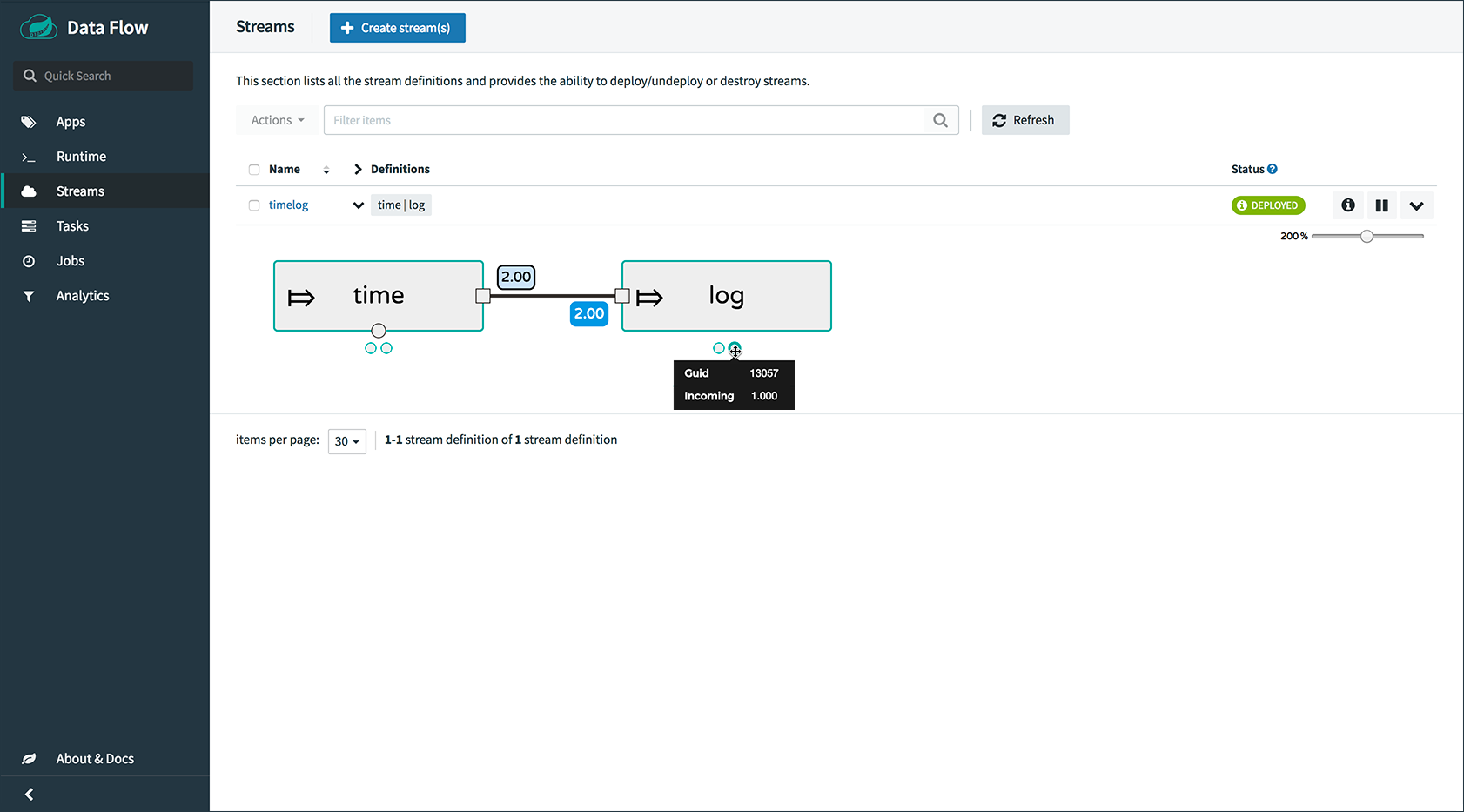
stream deploy --name foostream --properties "app.*.spring.cloud.stream.bindings.applicationMetrics.destination=metrics"Metrics Collector以JSON格式公开HTTP端点/collector/metrics下的聚合度量标准。数据流服务器以两种不同的方式访问此端点。第一种是通过公开/metrics/streams HTTP端点作为Metrics Collector端点的代理。当在SCDF的Flo上覆盖消息速率时,UI可以访问它,它是流媒体管道的可视化表示。还可以通过带有消息速率的runtime apps命令来访问Runtime选项卡和shell中公开的数据流/runtime/apps端点。
下图显示了在UI的Streams选项卡中显示的消息速率:
部署应用程序时,数据流设置spring.cloud.stream.metrics.properties属性,如以下示例所示:
spring.cloud.stream.metrics.properties=spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*这些键的值用作执行聚合的标记。对于2.x应用程序,这些键值直接映射到Micrometer库中的标签。属性spring.cloud.application.guid可用于跟踪生成度量标准的特定应用程序实例。guid值取决于平台。
数据流还设置用于控制导出哪些度量标准值的应用程序属性。对于1.x应用程序,属性为spring.metrics.export.triggers.application.includes,默认值如下所示:
spring.metrics.export.triggers.application.includes=integration**对于2.x应用程序,属性为spring.cloud.stream.metrics.meter-filter且没有默认值,因此将导出所有度量标准。
请注意,数据流UI仅显示瞬时输入和输出通道消息速率。数据流不提供自己的实现来存储和可视化历史指标数据,而是与现有的监控系统集成。对于Boot 1.x,支持将度量标准发送到应用程序日志和Datadog。对于Boot 2.x,指标由Micrometer库提供支持,Micrometer库提供各种监控系统。
25.1.2.Spring Boot 2.x
我们开发了一个示例应用程序,展示如何使用千分尺库修改time和log应用程序并将指标导出到InfluxDB。还提供Grafana前端。这是一个WIP,因此请查看Spring Cloud Data Flow Samples Repository以获取最新状态。
25.1.3.Spring Boot 1.x
每个部署的应用程序都包含web端点,用于监视流和任务应用程序并与之交互。
特别是,/metrics 端点包含HTTP请求的计数器和计量器,系统度量标准,如JVM统计信息,数据源度量标准和消息通道度量标准。Spring Boot允许您通过注册PublicMetrics接口的实现或通过与Dropwizard的集成将您自己的度量添加到/metrics端点。
Spring Boot接口MetricWriter和Exporter用于将度量数据发送到可以显示和分析它们的位置。Spring Boot中有实现将指标导出到Redis,Open TSDB,Statsd和JMX。
一些额外的Spring项目支持将度量数据发送到外部系统:
-
Spring Cloud Data Flow Metrics提供写入日志的
LogMetricWriter。 -
Spring Cloud Data Flow Metrics Datadog Metrics提供写入Datadog的
DatadogMetricWriter。
要使用此功能,您需要构建Stream应用程序,并使用您要使用的MetricWriter实现的附加pom依赖项。要自定义“开箱即用”流应用程序,请使用Spring Cloud Stream Initializr生成项目,然后修改pom。Data Flow Metrics项目页面上的文档提供了入门所需的其他信息。
26.关于配置
Spring Cloud Data Flow关于Restful API结果包含显示名称,版本,以及(如果指定)包含Spring Cloud Data Flow的每个主要依赖项的URL。结果(如果已启用)还包含shell依赖项的sha1和/或sha256校验和值。通过设置以下属性,可以配置为每个依赖项返回的信息:
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.name:用于核心的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.version:用于核心的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.name:用于仪表板的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.version:用于仪表板的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.name:用于实现的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.version:用于实现的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.name:用于shell的名称。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.version:用于shell的版本。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.url:用于下载shell依赖项的URL。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1:与shell依赖关系信息一起返回的sha1校验和值。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256:与shell依赖关系信息一起返回的sha256校验和值。
-
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1-url:如果未指定
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1,SCDF将使用此URL指定的文件内容作为校验和。 -
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256-url:如果未指定
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256,则SCDF使用此URL指定的文件内容作为校验和。
26.1.启用Shell Checksum值
默认情况下,不会显示shell依赖项的校验和值。如果需要启用此功能,请将spring.cloud.dataflow.version-info.dependency-fetch.enabled属性设置为true。
26.2.URL的保留值
您可以在URL中插入保留值(用花括号括起来),以确保链接是最新的:
-
存储库:如果使用数据流的构建快照,里程碑或候选发布版,则存储库引用repo-spring-io存储库。否则,它指的是Maven Central。
-
version:插入jar / pom的版本。
例如,如果您使用的是Spring Cloud Data Flow Shell的1.2.3.RELEASE版本,则myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/{version}/spring-cloud-dataflow-shell-{version}.jar会生成myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/1.2.3.RELEASE/spring-cloud-dataflow-shell-1.2.3.RELEASE.jar
Shell
本节介绍了启动shell的选项以及与shell如何处理SpEL表达式的空格,引号和解释相关的更高级功能。Stream DSL和Composed Task DSL的入门章节 是最常见的shell命令使用的好地方。
27. Shell选项
shell建立在Spring Shell项目之上。有Spring Shell通用的命令行选项和一些特定于数据流的命令行选项。shell采用以下命令行选项
unix:>java -jar spring-cloud-dataflow-shell-1.7.3.RELEASE.jar --help
Data Flow Options:
--dataflow.uri= Address of the Data Flow Server [default: http://localhost:9393].
--dataflow.username= Username of the Data Flow Server [no default].
--dataflow.password= Password of the Data Flow Server [no default].
--dataflow.credentials-provider-command= Accept any SSL certificate (even self-signed) [default: no].
--dataflow.proxy.uri= Address of an optional proxy server to use [no default].
--dataflow.proxy.username= Username of the proxy server (if required by proxy server) [no default].
--dataflow.proxy.password= Password of the proxy server (if required by proxy server) [no default].
--spring.shell.historySize= Default size of the shell log file [default: 3000].
--spring.shell.commandFile= Data Flow Shell executes commands read from the file(s) and then exits.
--help This message. spring.shell.commandFile选项可用于指向包含所有shell命令的现有文件,以部署一个或多个相关的流和任务。
还支持多个文件执行,它们应该以逗号分隔的字符串传递:
--spring.shell.commandFile=file1.txt,file2.txt
在创建一些脚本以帮助自动部署时,这非常有用。
此外,以下shell命令有助于将复杂脚本模块化为多个独立文件:
dataflow:>script --file <YOUR_AWESOME_SCRIPT>
28.列出可用命令
在命令提示符下键入help会列出所有可用命令。大多数命令都用于数据流功能,但有一些是通用的。
! - Allows execution of operating system (OS) commands
clear - Clears the console
cls - Clears the console
date - Displays the local date and time
exit - Exits the shell
http get - Make GET request to http endpoint
http post - POST data to http endpoint
quit - Exits the shell
system properties - Shows the shell's properties
version - Displays shell version将命令的名称添加到help会显示有关如何调用命令的其他信息。
dataflow:>help stream create
Keyword: stream create
Description: Create a new stream definition
Keyword: ** default **
Keyword: name
Help: the name to give to the stream
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: definition
Help: a stream definition, using the DSL (e.g. "http --port=9000 | hdfs")
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: deploy
Help: whether to deploy the stream immediately
Mandatory: false
Default if specified: 'true'
Default if unspecified: 'false'29.标签完成
通过在前导--后按TAB键,可以在shell中完成shell命令选项。例如,在stream create --之后按TAB会导致
dataflow:>stream create --
stream create --definition stream create --name如果您键入--de然后点击制表符,则会展开--definition。
对于应用程序或任务属性,还可以在流或组合任务DSL表达式中使用选项卡完成。您还可以使用TAB获取流DSL表达式中的提示,以获取可用的源,处理器或接收器。
30.白色空间和报价规则
如果参数值包含空格或|字符,则只需引用它们。以下示例将SpEL表达式(应用于它遇到的任何数据)传递给转换处理器:
transform --expression='new StringBuilder(payload).reverse()'
如果参数值需要嵌入单引号,请使用两个单引号,如下所示:
scan --query='Select * from /Customers where name=''Smith'''30.1.行情和逃避
有一个Spring基于Shell的客户端与数据流服务器通信,负责解析 DSL。反过来,应用程序可能具有依赖于嵌入式语言的应用程序属性,例如Spring表达式语言。
shell,Data Flow DSL解析器和SpEL有关于它们如何处理引号以及语法转义如何工作的规则。当组合在一起时,可能会出现混淆。本节介绍适用的规则,并提供在涉及所有三个组件时可能遇到的最复杂情况的示例。
|
它并不总是那么复杂
如果不使用数据流shell(例如,直接使用REST API)或者应用程序属性不是SpEL表达式,则转义规则更简单。 |
30.1.1.壳牌规则
可以说,引用时最复杂的组件是shell。但规则可以非常简单地列出:
-
shell命令由键(
--something)和相应的值组成。但是,有一种特殊的无键映射,稍后将对此进行描述。 -
值通常不能包含空格,因为空格是命令的默认分隔符。
-
通过用引号(单个(
')或双(")引号)包围值,可以添加空格。 -
不应再次引用在部署属性(例如
deployment <stream-name> --properties " …")内传递的值。 -
如果用引号括起来,则值可以通过在其前面添加反斜杠(
\)来嵌入相同类型的文字引号。 -
可以使用其他转义,例如
\t,\n,\r,\f和\uxxxx形式的unicode转义。 -
无密钥映射以特殊方式处理,因此它不需要引用来包含空格。
例如,shell支持!命令来执行本机shell命令。!接受单个无密钥参数。这就是以下工作的原因:
dataflow:>! rm something
这里的参数是整个rm something字符串,它按原样传递给底层shell。
作为另一个示例,以下命令严格等效,参数值为something(不带引号):
dataflow:>stream destroy something dataflow:>stream destroy --name something dataflow:>stream destroy "something" dataflow:>stream destroy --name "something"
30.1.2.属性文件规则
从文件加载属性时放宽规则。*需要转义属性文件(Java和YAML)中使用的特殊字符。例如\应替换为\\,'/ t`替换为\\t等等。*对于Java属性文件(--propertiesFile <FILE_PATH> .properties),属性值不应该用引号括起来!即使它们包含空格也不需要它。
filter.expression=payload > 5
-
但是,对于YAML属性文件(
--propertiesFile<FILE_PATH> .yaml),值必须用双引号括起来。
app:
filter:
filter:
expression: "payload > 5"
30.1.3.DSL解析规则
在解析器级别(即,在流或任务定义的主体内),规则如下:
-
通常会解析选项值,直到第一个空格字符。
-
它们可以由文字字符串组成,但用单引号或双引号括起来。
-
要嵌入这样的引用,请使用所需类型的两个连续引号。
因此,在以下示例中,过滤器应用程序的--expression选项的值在语义上是等效的:
filter --expression=payload>5 filter --expression="payload>5" filter --expression='payload>5' filter --expression='payload > 5'
可以说,最后一个更具可读性。这得益于周围的报价。实际表达式为payload > 5(不带引号)。
现在,假设我们想要测试字符串消息。如果我们想要将有效负载与SpEL文字字符串"something"进行比较,我们可以使用以下内容:
filter --expression=payload=='something' (1) filter --expression='payload == ''something''' (2) filter --expression='payload == "something"' (3)
| 1 | 这是有效的,因为没有空格。但是,它不是很清晰。 |
| 2 | 这使用单引号来保护整个参数。因此,实际的单引号需要加倍。 |
| 3 | SpEL使用单引号或双引号识别字符串文字,因此最后一种方法可以说是最具可读性的。 |
请注意,前面的示例将在shell之外考虑(例如,直接调用REST API时)。当在shell中输入时,很可能整个流定义本身都在双引号内,需要对其进行转义。然后整个例子变成如下:
dataflow:>stream create something --definition "http | filter --expression=payload='something' | log" dataflow:>stream create something --definition "http | filter --expression='payload == ''something''' | log" dataflow:>stream create something --definition "http | filter --expression='payload == \"something\"' | log"
30.1.4.SpEL语法和SpEL文字
拼图的最后一部分是关于SpEL表达式。许多应用程序接受将被解释为SpEL表达式的选项,并且如上所述,字符串文字也以特殊方式处理。规则如下:
-
文字可以用单引号或双引号括起来。
-
引号需要加倍才能嵌入字面引用。双引号内的单引号不需要特殊处理,反之亦然。
作为最后一个示例,假设您要使用转换处理器。此处理器接受expression选项,该选项是SpEL表达式。它将根据传入消息进行评估,默认值为payload(它不会触发消息有效负载)。
重要的是要理解以下陈述是等效的:
transform --expression=payload transform --expression='payload'
但是,它们与以下内容不同(以及它们的变体):
transform --expression="'payload'" transform --expression='''payload'''
第一个系列评估消息有效负载,而后面的示例评估为文字字符串payload,(同样,没有引号)。
30.1.5.把它放在一起
作为最后一个完整的示例,考虑如何通过在数据流shell的上下文中创建流来强制将所有消息转换为字符串文字hello world:
dataflow:>stream create something --definition "http | transform --expression='''hello world''' | log" (1) dataflow:>stream create something --definition "http | transform --expression='\"hello world\"' | log" (2) dataflow:>stream create something --definition "http | transform --expression=\"'hello world'\" | log" (2)
| 1 | 在第一行中,字符串周围有单引号(在数据流解析器级别),但它们需要加倍,因为它们在字符串文字内(由等号后面的第一个单引号启动)。 |
| 2 | 第二行和第三行分别使用单引号和双引号来包含数据流解析器级别的整个字符串。因此,可以在字符串内使用其他类型的引用。但是整个事情都在shell的--definition参数内,它使用双引号。因此,双引号被转义(在shell级别) |
流
本节详细介绍了如何创建Streams,它们是Spring Cloud Stream应用程序的集合 。它涵盖了创建和部署Streams等主题。
如果您刚开始使用Spring Cloud Data Flow,则在深入了解本节之前,您应该阅读“ 入门指南”。
31.简介
Stream是一组长期存在的Spring Cloud Stream应用程序,它们通过消息传递中间件相互通信。基于文本的DSL定义了应用程序之间的配置和数据流。虽然为您提供了许多应用程序来实现常见用例,但您通常会创建一个自定义Spring Cloud Stream应用程序来实现自定义业务逻辑。
Stream的一般生命周期是:
-
注册申请。
-
创建流定义。
-
部署流。
-
取消部署或销毁流。
-
流中的升级或Rollack应用程序。
如果使用Skipper,则可以在Stream中升级或回滚应用程序。
部署流有两种选择:
-
使用部署到单个平台的Data Flow Server实现。
-
配置数据流服务器以将部署委派给名为Skipper的Spring Cloud生态系统中的新服务器。
使用第一个选项时,您可以使用本地数据流服务器将流部署到本地计算机,Cloud Foundry的数据流服务器将流部署到Cloud Foundry上的单个组织和空间。同样,您可以使用Kuberenetes的数据流服务器将流部署到Kubernetes集群上的单个命名空间。有关数据流服务器实现的列表,请参见Spring Cloud Data Flow项目页面。
使用第二个选项时,您可以配置Skipper将应用程序部署到一个或多个Cloud Foundry组织和空间,Kubernetes集群上的一个或多个名称空间或本地计算机。使用Skipper在数据流中部署流时,您可以指定在部署时使用哪个平台。Skipper还为数据流提供了对已部署流进行更新的能力。可以通过多种方式更新流中的应用程序,但最常见的示例之一是使用新的自定义业务逻辑升级处理器应用程序,同时仅保留现有的源和接收器应用程序。
31.1.流管道DSL
使用基于unix的Pipeline语法定义流。语法使用竖线,也称为“管道”来连接多个命令。Unix中的命令ls -l | grep key | less获取ls -l进程的输出并将其传递给grep key进程的输入。grep的输出又被发送到less进程的输入。每个|符号将左侧命令的标准输出连接到右侧命令的标准输入。数据从左到右流过管道。
在数据流中,Unix命令由Spring Cloud Stream应用程序替换,每个管道符号表示通过消息中间件(例如RabbitMQ或Apache Kafka)连接应用程序的输入和输出。
每个Spring Cloud Stream应用程序都以简单名称注册。注册过程指定可以获取应用程序的位置(例如,在Maven Repository或Docker注册表中)。您可以在本节中找到有关如何注册Spring Cloud Stream应用程序的更多信息。在数据流中,我们将Spring Cloud Stream应用程序分类为源,处理器或接收器。
举一个简单的例子,考虑从HTTP Source写入文件接收器的数据集合。使用DSL,流描述是:
http | file
涉及某些处理的流将表示为:
http | filter | transform | file
可以使用shell的stream create命令创建流定义,如以下示例所示:
dataflow:> stream create --name httpIngest --definition "http | file"
Stream DSL传入--definition命令选项。
流定义的部署是通过shell的stream deploy命令完成的。
dataflow:> stream deploy --name ticktock
“ 入门”部分介绍了如何启动服务器以及如何启动和使用Spring Cloud Data Flow shell。
请注意,shell调用数据流服务器的REST API。有关直接向服务器发出HTTP请求的更多信息,请参阅REST API指南。
31.2.流应用程序DSL
上一节中描述的Stream Pipeline DSL自动设置每个Spring Cloud Stream应用程序的输入和输出绑定属性。这可以完成,因为Spring Cloud Stream应用程序中只有一个输入和/或输出目标,它使用Source,Processor或Sink提供的绑定接口。但是,Spring Cloud Stream应用程序可以定义自定义绑定接口,如下所示
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}或者在创建Kafka Streams应用程序时很常见,
interface KStreamKTableBinding {
@Input
KStream<?, ?> inputStream();
@Input
KTable<?, ?> inputTable();
}在具有多个输入和输出绑定的这些情况下,数据流无法对从一个应用程序到另一个应用程序的数据流做出任何假设。因此,开发人员需要将绑定属性设置为“连接”应用程序。该流应用DSL使用double pipe,而不是pipe symbol,以表明数据流不应该配置应用程序的结合特性。将||视为'并行'的含义。例如:
dataflow:> stream create --definition "orderGeneratorApp || baristaApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" --name myCafeStream
打破变革!SCDF Local,Cloud Foundry 1.7.0到1.7.2和SCDF Kubernetes 1.7.0到1.7.1的版本使用comma字符作为应用程序之间的分隔符。这导致了传统Stream DSL的重大变化。虽然不理想,但改变分隔符特性被认为是对现有用户影响最小的最佳解决方案。
|
此流中有四个应用程序。baristaApp有两个输出目标,hotDrinks和coldDrinks分别由hotDrinkDeliveryApp和coldDrinkDeliveryApp使用。部署此流时,您需要设置绑定属性,以便baristaApp将热饮消息发送到hotDrinkDeliveryApp目的地,并将冷饮消息发送到coldDrinkDeliveryApp目的地。例如
app.baristaApp.spring.cloud.stream.bindings.hotDrinks.destination=hotDrinksDest
app.baristaApp.spring.cloud.stream.bindings.coldDrinks.destination=coldDrinksDest
app.hotDrinkDeliveryApp.spring.cloud.stream.bindings.input.destination=hotDrinksDest
app.coldDrinkDeliveryApp.spring.cloud.stream.bindings.input.destination=coldDrinksDest如果要使用使用者组,则需要分别在生产者和使用者应用程序上设置Spring Cloud Stream应用程序属性spring.cloud.stream.bindings.<channelName>.producer.requiredGroups和spring.cloud.stream.bindings.<channelName>.group。
Stream Application DSL的另一个常见用例是部署一个http网关应用程序,该应用程序向Kafka或RabbitMQ应用程序发送同步请求/回复消息。在这种情况下,http网关应用程序和Kafka或RabbitMQ应用程序都可以是不使用Spring Cloud Stream库的Spring Integration应用程序。
也可以使用Stream应用程序DSL部署单个应用程序。
31.3.应用属性
每个应用程序都使用属性来定制其行为。例如,http源模块公开port设置,允许从默认值更改数据提取端口。
dataflow:> stream create --definition "http --port=8090 | log" --name myhttpstream
此port属性实际上与标准Spring Boot server.port属性相同。数据流添加了使用简写形式port而不是server.port的功能。也可以指定longhand版本,如以下示例所示:
dataflow:> stream create --definition "http --server.port=8000 | log" --name myhttpstream
有关白名单应用程序属性的部分将更详细地讨论此简写行为。如果已注册应用程序属性元数据,则可以在键入--后使用shell中的选项卡完成来获取候选属性名称列表。
shell为应用程序属性提供了Tab键完成。shell命令app info --name <appName> --type <appType>为所有支持的属性提供了附加文档。
支持的流<appType>可能性包括:源,处理器和接收器。
|
32.流生命周期
在“经典”模式下,流的生命周期经历以下阶段:
32.1.注册流应用程序
您可以使用Spring Cloud Data Flow Shell app register命令在App Registry中注册Stream App。您必须提供唯一的名称,应用程序类型和可以解析为应用程序工件的URI。对于类型,请指定source,processor,sink或app。以下是source,processor和sink的一些示例:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1-SNAPSHOT
dataflow:>app register --name myprocessor --type processor --uri file:///Users/example/myprocessor-1.2.3.jar
dataflow:>app register --name mysink --type sink --uri http://example.com/mysink-2.0.1.jar提供带有maven方案的URI时,格式应符合以下条件:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>例如,如果您要注册使用RabbitMQ绑定器构建的http和log应用程序的快照版本,则可以执行以下操作:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOT如果您想一次注册多个应用程序,可以将它们存储在属性文件中,其中键的格式为<type>.<name>,值为URI。
例如,如果您要注册使用RabbitMQ绑定器构建的http和log应用程序的快照版本,则可以在属性文件中包含以下内容(例如,stream-apps.properties ):
source.http=maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
sink.log=maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOT然后要批量导入应用程序,请使用app import命令并使用--uri开关提供属性文件的位置,如下所示:
dataflow:>app import --uri file:///<YOUR_FILE_LOCATION>/stream-apps.properties使用--type app注册应用程序与注册source,processor或sink相同。类型app的应用程序仅允许在Stream Application DSL中使用,它使用逗号而不是DSL中的管道符号,并指示数据流不配置应用程序的Spring Cloud Stream绑定属性。使用--type app注册的应用程序不必是Spring Cloud Stream应用程序,它可以是任何Spring Boot应用程序。有关使用此应用程序类型的更多信息,请参阅Stream Application DSL简介。
32.1.1.注册支持的应用和任务
为方便起见,我们为所有现成的流和任务/批处理应用程序启动程序提供了带有application-URI(适用于maven和docker)的静态文件。您可以指向此文件并批量导入所有应用程序URI。否则,如前所述,您可以单独注册它们,也可以拥有自己的自定义属性文件,其中只包含所需的应用程序URI。但是,建议在自定义属性文件中包含所需应用程序URI的“聚焦”列表。
下表列出了基于Spring Boot 1.5.x的可用流应用程序启动器的bit.ly链接:
| 神器类型 | 稳定释放 | SNAPSHOT发布 |
|---|---|---|
RabbitMQ + Maven |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-rabbit-maven |
|
RabbitMQ + Docker |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-rabbit-docker |
|
Kafka 0.10 + Maven |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-kafka-10-maven |
|
Kafka 0.10 + Docker |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-kafka-10-docker |
下表列出了基于Spring Boot 2.0.x的可用流应用程序启动器的bit.ly链接:
App Starter执行器端点默认是安全的。您可以通过使用属性app.*.spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.security.servlet.SecurityAutoConfiguration部署流来禁用安全性。在Kubernetes上,请参阅Liveness和 readyiness 探针部分,以配置执行器端点的安全性。
|
| 神器类型 | 稳定释放 | SNAPSHOT发布 |
|---|---|---|
RabbitMQ + Maven |
bit.ly/Darwin-BUILD-SNAPSHOT-stream-applications-rabbit-maven |
|
RabbitMQ + Docker |
bit.ly/Darwin-BUILD-SNAPSHOT-stream-applications-rabbit-docker |
|
Kafka 0.11 and above + Maven |
bit.ly/Darwin-BUILD-SNAPSHOT-stream-applications-kafka-maven |
|
Kafka 0.11 and above + Docker |
bit.ly/Darwin-BUILD-SNAPSHOT-stream-applications-kafka-docker |
下表列出了可用的任务应用程序启动器:
| 神器类型 | 稳定释放 | SNAPSHOT发布 |
|---|---|---|
Maven |
||
Docker |
您可以在Task App Starters Project页面和相关参考文档中找到有关可用任务启动器的更多信息。有关可用流启动器的更多信息,请查看Stream App Starters项目页面 和相关参考文档。
例如,如果您想要批量注册使用Kafka活页夹构建的所有现成的流应用程序,可以使用以下命令:
$ dataflow:>app import --uri http://bit.ly/Darwin-SR3-stream-applications-kafka-maven或者,您可以使用Rabbit绑定器注册所有流应用程序,如下所示:
$ dataflow:>app import --uri http://bit.ly/Darwin-SR3-stream-applications-rabbit-maven您还可以传递--local选项(默认为true)以指示是否应在shell进程本身内解析属性文件位置。如果应从数据流服务器进程解析位置,请指定--local false。
|
使用 但是,请注意,一旦下载,应用程序可以根据资源位置在数据流服务器上本地缓存。如果资源位置没有改变(即使实际资源字节可能不同),则不会重新下载。另一方面,当使用 此外,如果已经部署了流并使用某个版本的已注册应用程序,那么(强制)重新注册其他应用程序将无效,直到再次部署该流。 |
| 在某些情况下,资源在服务器端解析。在其他情况下,URI将传递到解析它的运行时容器实例。有关更多详细信息,请参阅每个数据流服务器的特定文档。 |
32.1.2.白名单应用程序属性
流和任务应用程序是Spring Boot应用程序,它们知道许多Common Application Properties,例如server.port,但也有一些属性系列,例如前缀为spring.jmx和logging的属性。在创建自己的应用程序时,您应该将属性列入白名单,以便在通过TAB完成或在下拉框中显示选项时,shell和UI可以首先将它们显示为主要属性。
要将应用程序属性列入白名单,请在META-INF资源目录中创建名为spring-configuration-metadata-whitelist.properties的文件。可以在此文件中使用两个属性键。第一个键名为configuration-properties.classes。该值是以逗号分隔的完全限定的@ConfigurationProperty类名列表。第二个键是configuration-properties.names,其值是以逗号分隔的属性名称列表。这可以包含属性的全名,例如server.port,或部分名称,以将属性名称列入白名单,例如spring.jmx。
该Spring Cloud Stream应用程序启动器是寻找使用示例的好地方。以下示例来自文件接收器的spring-configuration-metadata-whitelist.properties文件:
configuration-properties.classes=org.springframework.cloud.stream.app.file.sink.FileSinkProperties如果我们还要将server.port添加为白名单,它将成为以下行:
configuration-properties.classes=org.springframework.cloud.stream.app.file.sink.FileSinkProperties
configuration-properties.names=server.port|
确保添加“spring-boot-configuration-processor”作为可选依赖项,以生成属性的配置元数据文件。 |
32.1.3.创建和使用专用元数据工件
通过创建元数据伴随工件,您可以更进一步描述流或任务应用程序支持的主要属性。此jar文件仅包含有关配置属性元数据的Spring引导JSON文件和上一节中描述的白名单文件。
以下示例显示了规范log接收器的此类工件的内容:
$ jar tvf log-sink-rabbit-1.2.1.BUILD-SNAPSHOT-metadata.jar
373848 META-INF/spring-configuration-metadata.json
174 META-INF/spring-configuration-metadata-whitelist.properties请注意,spring-configuration-metadata.json文件非常大。这是因为它包含运行时可用于log接收器的所有属性的串联(其中一些来自spring-boot-actuator.jar,其中一些来自spring-boot-autoconfigure.jar,更多来自spring-cloud-starter-stream-sink-log.jar }, 等等)。数据流总是依赖于所有这些属性,即使伴随工件不可用,但这里所有属性都已合并到一个文件中。
为了帮助你(你不想尝试手工制作这个巨大的JSON文件),你可以在你的构建中使用以下插件:
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-app-starter-metadata-maven-plugin</artifactId>
<executions>
<execution>
<id>aggregate-metadata</id>
<phase>compile</phase>
<goals>
<goal>aggregate-metadata</goal>
</goals>
</execution>
</executions>
</plugin>
此插件除了创建单个JSON文件的spring-boot-configuration-processor之外。一定要配置两者。
|
配套工件的好处包括:
-
更轻松。(伴随工件通常为几千字节,而不是实际应用程序的兆字节。)因此,它们下载速度更快,允许在使用时提供更快的反馈,例如
app info或仪表板UI。 -
由于更轻,因此当元数据是所需的唯一信息时,它们可用于资源受限的环境(例如PaaS)。
-
对于不直接处理Spring Boot uber jar的环境(例如,基于Docker的运行时,如Kubernetes或Cloud Foundry),这是提供有关应用程序支持的属性的元数据的唯一方法。
但请记住,在处理超级罐时,这完全是可选的。超级jar本身也包含其中的元数据。
32.1.4.使用Companion Artifact
一旦掌握了伴随工件,就需要让系统了解它,以便可以使用它。
使用app register注册单个应用程序时,可以在shell中使用可选的--metadata-uri选项,如下所示:
dataflow:>app register --name log --type sink
--uri maven://org.springframework.cloud.stream.app:log-sink-kafka-10:1.2.1.BUILD-SNAPSHOT
--metadata-uri maven://org.springframework.cloud.stream.app:log-sink-kafka-10:jar:metadata:1.2.1.BUILD-SNAPSHOT使用app import命令注册多个文件时,除了每个<type>.<name>行之外,该文件还应包含<type>.<name>.metadata行。严格来说,这样做是可选的(如果有些应用程序有,但有些应用程序没有,它可以工作),但这是最好的做法。
以下示例显示了一个Dockerized应用程序,其中元数据工件托管在Maven存储库中(通过http://或file://检索它同样可行)。
...
source.http=docker:springcloudstream/http-source-rabbit:latest
source.http.metadata=maven://org.springframework.cloud.stream.app:http-source-rabbit:jar:metadata:1.2.1.BUILD-SNAPSHOT
...32.1.5.创建定制应用程序
虽然可以使用开箱即用的源,处理器,接收器应用程序,但您可以扩展这些应用程序或编写自定义Spring Cloud Stream应用程序。
使用Spring Initializr创建Spring Cloud Stream应用程序的过程在Spring Cloud Stream 文档中有详细说明。可以将多个绑定器包括到应用程序中。如果这样做,请参阅传递Spring Cloud Stream属性中的说明以了解如何配置它们。
为了支持属性白名单,在Spring Cloud Data Flow中运行的Spring Cloud Stream应用程序可能包含Spring Boot configuration-processor作为可选依赖项,如以下示例所示:
<dependencies>
<!-- other dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>|
确保POM中包含 |
32.2.创建流
Spring Cloud Data Flow服务器公开了一个完整的RESTful API来管理流定义的生命周期,但最简单的方法是通过Spring Cloud Data Flow shell。按照“ 入门”部分中的说明启动shell 。
在流定义的帮助下创建新流。定义是从简单的DSL构建的。例如,考虑如果我们执行以下shell命令会发生什么:
dataflow:> stream create --definition "time | log" --name ticktock这定义了一个名为ticktock的流,它基于DSL表达式time | log。DSL使用“管道”符号(|)将源连接到接收器。
32.2.1.申请Properties
应用程序属性是与流中的每个应用程序关联的属性。部署应用程序时,应用程序属性将通过命令行参数或环境变量应用于应用程序,具体取决于基础部署实现。
以下流可以在创建流时定义应用程序属性:
dataflow:> stream create --definition "time | log" --name ticktock以下清单显示了time应用的white_listed属性:
dataflow:> app info --name time --type source
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║trigger.time-unit │The TimeUnit to apply to delay│<none> │java.util.concurrent.TimeUnit ║
║ │values. │ │ ║
║trigger.fixed-delay │Fixed delay for periodic │1 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.cron │Cron expression value for the │<none> │java.lang.String ║
║ │Cron Trigger. │ │ ║
║trigger.initial-delay │Initial delay for periodic │0 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.max-messages │Maximum messages per poll, -1 │1 │java.lang.Long ║
║ │means infinity. │ │ ║
║trigger.date-format │Format for the date value. │<none> │java.lang.String ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝以下清单显示了log应用的白名单属性:
dataflow:> app info --name log --type sink
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║log.name │The name of the logger to use.│<none> │java.lang.String ║
║log.level │The level at which to log │<none> │org.springframework.integratio║
║ │messages. │ │n.handler.LoggingHandler$Level║
║log.expression │A SpEL expression (against the│payload │java.lang.String ║
║ │incoming message) to evaluate │ │ ║
║ │as the logged message. │ │ ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝time和log应用程序的应用程序属性可以在创建stream时指定,如下所示:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktock请注意,在前面的示例中,为应用time和log定义的fixed-delay和level属性是shell完成提供的“'short-form'”属性名称。这些“'短格式'”属性名称仅适用于列入白名单的属性。在所有其他情况下,只应使用完全限定的属性名称。
32.2.2.共同申请Properties
除了通过DSL进行配置之外,Spring Cloud Data Flow还提供了一种机制,用于为其启动的所有流应用程序设置公共属性。这可以通过在启动服务器时添加前缀为spring.cloud.dataflow.applicationProperties.stream的属性来完成。执行此操作时,服务器将所有不带前缀的属性传递给它启动的实例。
例如,通过使用以下选项启动数据流服务器,可以将所有已启动的应用程序配置为使用特定的Kafka代理:
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=192.168.1.100:9092
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=192.168.1.100:2181这样做会导致属性spring.cloud.stream.kafka.binder.brokers和spring.cloud.stream.kafka.binder.zkNodes传递给所有已启动的应用程序。
使用此机制配置的Properties优先级低于流部署属性。如果在流部署时指定具有相同键的属性(例如,app.http.spring.cloud.stream.kafka.binder.brokers覆盖公共属性),则会覆盖它们。
|
32.3.部署流
本节介绍在Spring Cloud Data Flow服务器负责部署流时如何部署流。以下部分“ Stream Lifecycle with Skipper ”涵盖了Spring Cloud Data Flow服务器委派给Skipper进行流部署时的新部署和升级功能。部署属性如何应用于Stream部署的两种方法的描述。
给出ticktock流定义:
dataflow:> stream create --definition "time | log" --name ticktock
要部署流,请使用以下shell命令:
dataflow:> stream deploy --name ticktock
数据流服务器将time和log解析为maven坐标,并使用它们启动流的time和log应用程序,如下面的清单所示:
2016-06-01 09:41:21.728 INFO 79016 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app ticktock.log instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log
2016-06-01 09:41:21.914 INFO 79016 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app ticktock.time instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481910/ticktock.time在前面的示例中,时间源每秒将当前时间作为消息发送,并且日志接收器使用日志记录框架输出它。您可以尾随stdout日志(后缀为<instance>)。日志文件位于数据流服务器日志输出中显示的目录中,如下面的清单所示:
$ tail -f /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log/stdout_0.log
2016-06-01 09:45:11.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:11
2016-06-01 09:45:12.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:12
2016-06-01 09:45:13.251 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:13您还可以通过在创建流时传递--deploy标志来一步创建和部署流,如下所示:
dataflow:> stream create --definition "time | log" --name ticktock --deploy但是,在实际用例中,一步创建和部署流并不常见。原因是当您使用stream deploy命令时,您可以传入定义如何将应用程序映射到平台的属性(例如,要使用的容器的内存大小,每个应用程序的数量到运行,以及是否启用数据分区功能)。Properties还可以覆盖在创建流时设置的应用程序属性。接下来的部分将详细介绍此功能。
32.3.1.部署Properties
部署流时,您可以指定属于两个组的属性:
-
Properties控制应用程序如何部署到目标平台。这些属性使用
deployer前缀,称为deployer属性。 -
Properties设置应用程序属性或覆盖在流创建期间设置的应用程序属性,并称为
application属性。
deployer属性的语法是deployer.<app-name>.<short-property-name>=<value>,application属性app.<app-name>.<property-name>=<value>的语法。通过shell传递部署属性时使用此语法。您也可以在YAML文件中指定它们,本文稍后将对此进行讨论。
下表显示了在部署应用程序时设置deployer和application属性之间的行为差异。
| 申请Properties | 部署员Properties | |
|---|---|---|
Example Syntax |
|
|
What the application "sees" |
|
Nothing |
What the deployer "sees" |
Nothing |
|
Typical usage |
Passing/Overriding application properties, passing Spring Cloud Stream binder or partitioning properties |
Setting the number of instances, memory, disk, and others |
传递实例计数
如果您希望在流中有多个应用程序实例,则可以使用deploy命令包含名为count的部署程序属性:
dataflow:> stream deploy --name ticktock --properties "deployer.time.count=3"请注意,count是底层部署者使用的保留属性名称。因此,如果应用程序还具有名为count的自定义属性,则在流部署期间以“短格式”形式指定时不支持该属性,因为它可能与实例count deployer属性冲突。相反,作为自定义应用程序属性的count可以在流部署期间以其完全限定的形式(例如,app.something.somethingelse.count)指定,或者可以使用“短格式”或完全限定的表单来指定在流创建期间,它作为app属性处理。
| 请参阅在流中使用标签。 |
内联与基于文件的Properties
使用Spring Cloud Data Flow Shell时,有两种方法可以提供部署属性:内联或通过文件引用。这两种方式都是排他性的。
内联属性使用--properties shell选项和列表属性作为逗号分隔的键=值对列表,如以下示例所示:
stream deploy foo
--properties "deployer.transform.count=2,app.transform.producer.partitionKeyExpression=payload"文件引用使用--propertiesFile选项并将其指向本地.properties,.yaml或.yml文件(即,驻留在运行shell的计算机的文件系统中的文件)。作为.properties文件读取,正常规则适用(ISO 8859-1编码,=,<space>或:分隔符等),但我们建议使用=作为键值对分隔符,用于一致性。以下示例显示了使用--propertiesFile选项的stream deploy命令:
stream deploy something --propertiesFile myprops.properties假设myprops.properties包含以下属性:
deployer.transform.count=2
app.transform.producer.partitionKeyExpression=payload这两个属性都作为something流的部署属性传递。
如果使用YAML作为部署属性的格式,请在部署流时使用.yaml或.yml文件扩展,如以下示例所示:
stream deploy foo --propertiesFile myprops.yaml在这种情况下,myprops.yaml文件可能包含以下内容:
deployer:
transform:
count: 2
app:
transform:
producer:
partitionKeyExpression: payload传递应用程序属性
部署流时也可以指定应用程序属性。在部署期间指定时,可以将这些应用程序属性指定为“短格式”属性名称(适用于列入白名单的属性)或完全限定的属性名称。应用程序属性应具有前缀app.<appName/label>。
例如,请考虑以下stream命令:
dataflow:> stream create --definition "time | log" --name ticktock通过使用“短格式”属性名称,还可以使用应用程序属性部署precedig示例中的流,如以下示例所示:
dataflow:>stream deploy ticktock --properties "app.time.fixed-delay=5,app.log.level=ERROR"请考虑以下示例:
stream create ticktock --definition "a: time | b: log"使用app标签时,应用程序属性可以定义如下:
stream deploy ticktock --properties "app.a.fixed-delay=4,app.b.level=ERROR"传递Spring Cloud Stream属性
Spring Cloud Data Flow为流中的应用程序设置required Spring Cloud Stream属性。最重要的是,spring.cloud.stream.bindings.<input/output>.destination是内部设置的应用程序绑定。
如果要覆盖任何Spring Cloud Stream属性,可以使用部署属性进行设置。
例如,请考虑以下流定义:
dataflow:> stream create --definition "http | transform --expression=payload.getValue('hello').toUpperCase() | log" --name ticktock如果每个应用程序的类路径中有多个可用的绑定器,并且为每个部署选择了绑定器,则可以使用特定的Spring Cloud Stream属性部署流,如下所示:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.bindings.output.binder=kafka,app.transform.spring.cloud.stream.bindings.input.binder=kafka,app.transform.spring.cloud.stream.bindings.output.binder=rabbit,app.log.spring.cloud.stream.bindings.input.binder=rabbit"| 建议不要覆盖目标名称,因为Spring Cloud Data Flow内部负责设置此属性。 |
传递每个绑定生产者和消费者Properties
Spring Cloud Stream应用程序可以基于per-binding设置生产者和消费者属性。虽然Spring Cloud Data Flow支持为每个绑定生成器属性指定简写符号,例如partitionKeyExpression和partitionKeyExtractorClass(如传递流分区Properties中所述),但所有受支持的Spring Cloud Stream生成器/消费者属性也可以直接设置为应用的Spring Cloud Stream属性。
可以为inbound通道名称设置消费者属性,前缀为app.[app/label name].spring.cloud.stream.bindings.<channelName>.consumer.。可以为outbound通道名称设置生产者属性,前缀为app.[app/label name].spring.cloud.stream.bindings.<channelName>.producer.。请考虑以下示例:
dataflow:> stream create --definition "time | log" --name ticktock可以使用producer和consumer属性部署流,如下所示:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.bindings.output.producer.requiredGroups=myGroup,app.time.spring.cloud.stream.bindings.output.producer.headerMode=raw,app.log.spring.cloud.stream.bindings.input.consumer.concurrency=3,app.log.spring.cloud.stream.bindings.input.consumer.maxAttempts=5"特定于binder的生产者和消费者属性也可以以类似的方式指定,如以下示例所示:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.rabbit.bindings.output.producer.autoBindDlq=true,app.log.spring.cloud.stream.rabbit.bindings.input.consumer.transacted=true"通过流分区Properties
流处理中的一种常见模式是在数据流传输时对数据进行分区。这需要部署消息应用程序的多个实例并使用基于内容的路由,以便具有给定键(在运行时确定)的消息始终路由到同一个应用程序实例。您可以在流部署期间传递分区属性,以声明方式配置分区策略,以将每条消息路由到特定的使用者实例。
以下列表显示了部署分区流的变体:
-
app。[app / label name] .producer.partitionKeyExtractorClass:
PartitionKeyExtractorStrategy的类名(默认值:null) -
app。[app / label name] .producer.partitionKeyExpression:根据消息评估的SpEL表达式,用于确定分区键。仅在
partitionKeyExtractorClass为空时适用。如果两者都为null,则不对应用程序进行分区(默认值:null) -
app。[app / label name] .producer.partitionSelectorClass:
PartitionSelectorStrategy的类名(默认值:null) -
app。[app / label name] .producer.partitionSelectorExpression:根据分区键计算的SpEL表达式,用于确定消息路由到的分区索引。最终分区索引是模数
[nextModule].count的返回值(整数)。如果类和表达式都为null,则底层绑定器的默认值PartitionSelectorStrategy将应用于键(默认值:null)
总之,如果应用程序的计数> 1且前一个应用程序的partitionKeyExtractorClass或partitionKeyExpression(partitionKeyExtractorClass优先),则会对其进行分区。提取分区键时,通过调用partitionSelectorClass(如果存在)或partitionSelectorExpression % partitionCount来确定分区的应用程序实例。对于RabbitMQ,partitionCount是应用程序计数,或者在Kafka的情况下,是主题的基础分区计数。
如果既不存在partitionSelectorClass也不存在partitionSelectorExpression,则结果为key.hashCode() % partitionCount。
传递应用程序内容类型属性
在流定义中,您可以指定必须将应用程序的输入或输出转换为其他类型。您可以使用inputType和outputType属性分别指定传入数据和传出数据的内容类型。
例如,请考虑以下流:
dataflow:>stream create tuple --definition "http | filter --inputType=application/x-spring-tuple
--expression=payload.hasFieldName('hello') | transform --expression=payload.getValue('hello').toUpperCase()
| log" --deployhttp应用程序需要以JSON格式发送数据,filter应用程序接收JSON数据并将其作为Spring元组进行处理。为此,我们使用过滤器应用程序上的inputType属性将数据转换为预期的Spring元组格式。transform应用程序处理元组数据并将处理后的数据发送到下游log应用程序。
请考虑以下将一些数据发送到http应用程序的示例:
dataflow:>http post --data {"hello":"world","something":"somethingelse"} --contentType application/json --target http://localhost:<http-port>
在日志应用程序中,您会看到如下内容:
INFO 18745 --- [transform.tuple-1] log.sink : WORLD
根据应用程序的链接方式,内容类型转换可以在上游应用程序中指定为--outputType,也可以在下游应用程序中指定为--inputType。例如,在上面的流中,不是在'transform'应用程序上指定要转换的--inputType,而是也可以在'http'应用程序上指定选项--outputType=application/x-spring-tuple。
有关消息转换和消息转换器的完整列表,请参阅Spring Cloud Stream 文档。
在流部署期间覆盖应用程序Properties
部署期间定义的应用程序属性将覆盖在流创建期间定义的相同属性。
例如,以下流具有在流创建期间定义的应用程序属性:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktock要覆盖这些应用程序属性,可以在部署期间指定新属性值,如下所示:
dataflow:>stream deploy ticktock --properties "app.time.fixed-delay=4,app.log.level=ERROR"32.4.摧毁一条小溪
您可以通过从shell发出stream destroy命令来删除流,如下所示:
dataflow:> stream destroy --name ticktock
如果部署了流,则在删除流定义之前将取消部署它。
32.5.取消部署流
通常,您希望停止流但保留名称和定义以供将来使用。在这种情况下,您可以按名称undeploy输入流。
dataflow:> stream undeploy --name ticktock
dataflow:> stream deploy --name ticktock您可以稍后发出deploy命令以重新启动它。
dataflow:> stream deploy --name ticktock
32.6.验证流
有时,流定义中包含的一个或多个应用程序在其注册中包含无效的URI。这可能是由于在应用注册时输入的URI无效或应用程序已从用于绘制应用程序的存储库中删除而导致的。要验证流中包含的所有应用程序是否可解析,用户可以使用validate命令。例如:
dataflow:>stream validate ticktock
╔═══════════╤═════════════════╗
║Stream Name│Stream Definition║
╠═══════════╪═════════════════╣
║ticktock │time | log ║
╚═══════════╧═════════════════╝
ticktock is a valid stream.
╔═══════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════╪═════════════════╣
║source:time│valid ║
║sink:log │valid ║
╚═══════════╧═════════════════╝在上面的示例中,用户验证了他们的ticktock流。我们看到source:time和sink:log都是有效的。现在让我们看看如果我们有一个带有无效URI的注册应用程序的流定义会发生什么。
dataflow:>stream validate bad-ticktock
╔════════════╤═════════════════╗
║Stream Name │Stream Definition║
╠════════════╪═════════════════╣
║bad-ticktock│bad-time | log ║
╚════════════╧═════════════════╝
bad-ticktock is an invalid stream.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║source:bad-time│invalid ║
║sink:log │valid ║
╚═══════════════╧═════════════════╝在这种情况下,Spring Cloud Data Flow表示流是无效的,因为source:bad-time具有无效的URI。
33.船长生命周期与船长
如果您以“skipper”模式运行,则可以使用Stream的其他生命周期阶段。
Skipper是一种服务器,您可以在多个云平台上发现Spring Boot应用程序并管理其生命周期。
Skipper中的应用程序捆绑为包含应用程序资源位置,应用程序属性和部署属性的包。您可以认为Skipper软件包与apt-get或brew等工具中的软件包类似。
当Data Flow部署Stream时,它将生成一个包并将其上传到Skipper,代表Stream中的应用程序。在Stream中升级或回滚应用程序的后续命令将传递给Skipper。此外,Stream定义是从包中进行反向设计的,Stream的状态也被委托给Skipper。
33.1.注册Versioned Stream应用程序
Skipper扩展了Register a Stream App 生命周期,支持多版本流应用程序。这允许使用部署属性在运行时升级或回滚这些应用程序。
使用app register命令注册版本化的流应用程序。您必须提供可以解析为应用程序工件的唯一名称,应用程序类型和URI。对于类型,请指定“source”,“processor”或“sink”。该版本是从URI解析的。这里有一些例子:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.2
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.1 <│ │ │ ║
║ │mysource-0.0.2 │ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝应用程序URI应符合以下架构格式之一:
-
maven架构
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>
-
http架构
http://<web-path>/<artifactName>-<version>.jar
-
文件架构
file:///<local-path>/<artifactName>-<version>.jar
-
docker schema
docker:<docker-image-path>/<imageName>:<version>
URI <version>部分对于版本化的流应用程序是必需的
|
可以为相同的应用程序注册多个版本(例如,相同的名称和类型),但只能将一个版本设置为默认值。默认版本用于部署Streams。
第一次注册应用程序时,它将被标记为默认值。可以使用app default命令更改默认应用程序版本:
dataflow:>app default --id source:mysource --version 0.0.2
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.1 │ │ │ ║
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝app list --id <type:name>命令列出给定流应用程序的所有版本。
app unregister命令具有可选的--version参数,用于指定要取消注册的应用程序版本。
dataflow:>app unregister --name mysource --type source --version 0.0.1
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝如果未指定--version,则取消注册默认版本。
|
流中的所有应用程序都应为要部署的流设置默认版本。否则,在部署期间,它们将被视为未注册的应用程序。使用 |
app default --id source:mysource --version 0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.2 │ │ │ ║
║ │> mysource-0.0.3 <│ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝stream deploy需要设置默认的应用版本。stream update和stream rollback命令虽然可以使用所有(默认和非默认)注册的应用程序版本。
dataflow:>stream create foo --definition "mysource | log"这将使用默认的mysource版本(0.0.3)创建流。然后我们可以将版本更新为0.0.2,如下所示:
dataflow:>stream update foo --properties version.mysource=0.0.2|
只有预先注册的应用程序可用于 |
尝试将mysource更新为版本0.0.1(未注册)将失败!
33.2.创建和部署流
您可以通过两个步骤使用Skipper创建和部署流:
-
创建流定义。
-
部署流。
以下示例显示了两个步骤:
dataflow:> stream create --name httptest --definition "http --server.port=9000 | log"
dataflow:> stream deploy --name httpteststream info命令显示有关流的有用信息,包括部署属性,如下例所示(及其输出):
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.1.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}stream deploy命令有一个重要的可选命令参数(称为--platformName)。可以将Skipper配置为部署到多个平台。Skipper预先配置了一个名为default的平台,该平台将应用程序部署到运行Skipper的本地计算机。命令行参数--platformName的默认值为default。如果您通常部署到一个平台,则在安装Skipper时,您可以覆盖default平台的配置。否则,将platformName指定为stream platform-list命令返回的值之一。
33.3.更新流
要更新流,请使用命令stream update作为命令参数--properties或--propertiesFile。您可以使用与使用或不使用Skipper部署流时相同的格式将值传递给这些命令参数。使用Skipper时有一个重要的新顶级前缀,即version。如果部署了流http | log,并且在部署时注册的log版本为1.1.0.RELEASE,则以下命令将更新流以使用日志应用程序的1.2.0.RELEASE。在使用特定版本的应用程序更新流之前,我们需要确保该应用程序已使用该版本注册。
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.0.RELEASE
Successfully registered application 'sink:log'dataflow:>stream update --name httptest --properties version.log=1.2.0.RELEASE|
只有预先注册的应用程序版本可用于 |
要验证部署属性和更新的版本,我们可以使用stream info,如下图所示(及其输出):
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.count" : "1",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.2.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}33.4.强制更新流
升级流时,即使没有更改应用程序或部署属性,也可以使用--force选项部署当前部署的应用程序的新实例。当应用程序本身在启动时获取配置信息时,例如从Spring Cloud Config Server获取配置信息时,需要此行为。您可以使用选项--app-names指定要强制升级的应用程序。如果未指定任何应用程序名称,则将强制升级所有应用程序。您可以将--force和--app-names选项与--properties或--propertiesFile选项一起指定。
33.5.流版本
Skipper保留已部署的流的历史记录。更新流后,将有第二个版本的流。您可以使用命令stream history --name <name-of-stream>查询版本的历史记录。
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║2 │Mon Nov 27 22:41:16 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝33.6.流清单
在替换所有值之后,Skipper会保留所有应用程序,其应用程序属性及其部署属性的“清单”。这代表了部署到平台的最终状态。您可以使用以下命令查看Stream的任何版本的清单:
stream manifest --name <name-of-stream> --releaseVersion <optional-version>
如果未指定--releaseVersion,则返回上一版本的清单。
以下示例显示了清单的用法:
dataflow:>stream manifest --name httptest使用该命令会产生以下输出:
# Source: log.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: log
spec:
resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: log
spring.cloud.stream.metrics.key: httptest.log.${spring.cloud.application.guid}
spring.cloud.stream.bindings.input.group: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: sink
spring.cloud.stream.bindings.input.destination: httptest.http
deploymentProperties:
spring.cloud.deployer.indexed: true
spring.cloud.deployer.group: httptest
spring.cloud.deployer.count: 1
---
# Source: http.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: http
spec:
resource: maven://org.springframework.cloud.stream.app:http-source-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: http
spring.cloud.stream.metrics.key: httptest.http.${spring.cloud.application.guid}
spring.cloud.stream.bindings.output.producer.requiredGroups: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
server.port: 9000
spring.cloud.stream.bindings.output.destination: httptest.http
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: source
deploymentProperties:
spring.cloud.deployer.group: httptest大多数部署和应用程序属性由Data Flow设置,以使应用程序能够相互通信并使用标识标签发送应用程序指标。
33.7.回滚流
您可以使用命令stream rollback回滚到以前版本的流。
dataflow:>stream rollback --name httptest可选的--releaseVersion命令参数添加了流的版本。如果未指定,则回滚将转到上一个流版本。
33.8.申请数量
应用程序计数是系统的动态属性。如果由于在运行时进行扩展,要升级的应用程序运行了5个实例,则会部署5个升级后的应用程序实例。
33.9.船长的升级策略
船长有一个简单的“红/黑”升级策略。它使用与当前运行版本一样多的实例来部署新版本的应用程序,并检查应用程序的/health端点。如果新应用程序的运行状况良好,则取消部署先前的应用程序。如果新应用程序的运行状况不佳,则取消部署所有新应用程序,并且认为升级不成功。
升级策略不是滚动升级,因此如果应用程序的五个应用程序正在运行,那么在晴天情况下,五个新应用程序也会在取消部署旧版本之前运行。
34.流DSL
本节介绍Stream DSL简介中未涵盖的Stream DSL的其他功能。
34.1.点按一个流
可以在流中的各个生产者端点处创建抽头。对于如以下示例中定义的流,可以在http,step1和step2的输出处创建抽头:
stream create --definition "http | step1: transform --expression=payload.toUpperCase() | step2: transform --expression=payload+'!' | log" --name mainstream --deploy
要创建充当另一个流上的“点按”的流,需要为点按流指定source destination name。源目标名称的语法如下:
:<streamName>.<label/appName>
要在前面的流中的http输出处创建一个点按,源目标名称为mainstream.http要在上面的流中的第一个转换应用的输出处创建一个点击,源目标名称为mainstream.step1
点击流DSL类似于以下内容:
stream create --definition ":mainstream.http > counter" --name tap_at_http --deploy
stream create --definition ":mainstream.step1 > jdbc" --name tap_at_step1_transformer --deploy请注意目标名称前的冒号(:)前缀。冒号让解析器将其识别为目标名称而不是应用程序名称。
34.2.在流中使用标签
当流由多个具有相同名称的应用组成时,必须使用标签进行限定:stream create --definition "http | firstLabel: transform --expression=payload.toUpperCase() | secondLabel: transform --expression=payload+'!' | log" --name myStreamWithLabels --deploy
34.3.命名目的地
您可以使用命名目标,而不是引用源或接收器应用程序。命名目标对应于中间件代理(Rabbit,Kafka和其他)中的特定目标名称。使用|符号时,应用程序通过数据流服务器创建的消息中间件目标名称相互连接。与Unix类比一致,可以使用小于(<)和大于(>)字符重定向标准输入和输出。要指定目标的名称,请在其前面加冒号(:)。例如,以下流的目标名称位于source位置:
dataflow:>stream create --definition ":myDestination > log" --name ingest_from_broker --deploy
此流从位于代理的名为myDestination的目标接收消息,并将其连接到log应用程序。您还可以创建使用来自同一命名目标的数据的其他流。
以下流的目标名称位于sink位置:
dataflow:>stream create --definition "http > :myDestination" --name ingest_to_broker --deploy
也可以在流中的代理处连接两个不同的目标(source和sink位置),如以下示例所示:
dataflow:>stream create --definition ":destination1 > :destination2" --name bridge_destinations --deploy
在前面的流中,目标(destination1和destination2)都位于代理中。消息通过连接它们的bridge应用程序从源目标流向接收器目标。
35.流Java DSL
您可以使用spring-cloud-dataflow-rest-client模块提供的基于Java的DSL,而不是使用shell来创建和部署流。Java DSL是DataFlowTemplate类的一个方便的包装器,可以以编程方式创建和部署流。
首先,您需要将以下依赖项添加到项目中,如下所示:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>1.7.3.RELEASE</version>
</dependency>| 可以在Spring Cloud Data Flow样本Repository中找到完整的样本。 |
35.1.概观
Java DSL核心的类是StreamBuilder,StreamDefinition,Stream,StreamApplication和DataFlowTemplate。入口点是Stream上的builder方法,它采用DataFlowTemplate的实例。要创建DataFlowTemplate的实例,您需要提供数据流服务器的URI位置。
Spring Boot StreamBuilder和DataFlowTemplate的自动配置也可用。DataFlowClientProperties中的属性可用于配置与数据流服务器的连接。开始使用的共同属性是spring.cloud.dataflow.client.uri
请考虑以下示例,使用definition样式。
URI dataFlowUri = URI.create("http://localhost:9393");
DataFlowOperations dataFlowOperations = new DataFlowTemplate(dataFlowUri);
dataFlowOperations.appRegistryOperations().importFromResource(
"http://bit.ly/Darwin-SR3-stream-applications-rabbit-maven", true);
StreamDefinition streamDefinition = Stream.builder(dataFlowOperations)
.name("ticktock")
.definition("time | log")
.create();create方法返回StreamDefinition的实例,表示已创建但未部署的Stream。这称为definition样式,因为它为流定义采用单个字符串,与shell中的相同。如果尚未在数据流服务器中注册应用程序,则可以使用DataFlowOperations类进行注册。使用StreamDefinition实例,您可以使用deploy或destory流的方法。
Stream stream = streamDefinition.deploy();Stream实例提供getStatus,destroy和undeploy方法来控制和查询流。如果要立即部署流,则无需创建StreamDefinition类型的单独局部变量。您可以将调用链接在一起,如下所示:
Stream stream = Stream.builder(dataFlowOperations)
.name("ticktock")
.definition("time | log")
.create()
.deploy();重载deploy方法以获取java.util.Map部署属性。
StreamApplication类用于'流畅的'Java DSL风格,将在下一节中讨论。StreamBuilder类从方法Stream.builder(dataFlowOperations)返回。在较大的应用程序中,通常将StreamBuilder的单个实例创建为Spring @Bean并在整个应用程序中共享它。
35.2.Java DSL样式
Java DSL提供两种样式来创建Streams。
-
definition样式保留了在shell中使用管道和过滤文本DSL的感觉。在设置流名称后使用definition方法选择此样式 - 例如,Stream.builder(dataFlowOperations).name("ticktock").definition(<definition goes here>)。 -
fluent样式允许您通过传入StreamApplication的实例将源,处理器和接收器链接在一起。在设置流名称后使用source方法选择此样式 - 例如,Stream.builder(dataFlowOperations).name("ticktock").source(<stream application instance goes here>)。然后,将processor()和sink()方法链接在一起以创建流定义。
为了演示这两种样式,我们提供了一个使用这两种方法的简单流。您可以在Spring Cloud Data Flow样本Repository中找到完整的入门示例。
以下示例演示了定义方法:
public void definitionStyle() throws Exception{
Map<String, String> deploymentProperties = createDeploymentProperties();
Stream woodchuck = Stream.builder(dataFlowOperations)
.name("woodchuck")
.definition("http --server.port=9900 | splitter --expression=payload.split(' ') | log")
.create()
.deploy(deploymentProperties);
waitAndDestroy(woodchuck)
}以下示例演示了流畅的方法:
private void fluentStyle(DataFlowOperations dataFlowOperations) throws InterruptedException {
logger.info("Deploying stream.");
Stream woodchuck = builder
.name("woodchuck")
.source(source)
.processor(processor)
.sink(sink)
.create()
.deploy();
waitAndDestroy(woodchuck);
}waitAndDestroy方法使用getStatus方法轮询流的状态,如以下示例所示:
private void waitAndDestroy(Stream stream) throws InterruptedException {
while(!stream.getStatus().equals("deployed")){
System.out.println("Wating for deployment of stream.");
Thread.sleep(5000);
}
System.out.println("Letting the stream run for 2 minutes.");
// Let the stream run for 2 minutes
Thread.sleep(120000);
System.out.println("Destroying stream");
stream.destroy();
}使用定义样式时,部署属性以与使用shell相同的方式指定为java.util.Map。createDeploymentProperties方法定义如下:
private Map<String, String> createDeploymentProperties() {
DeploymentPropertiesBuilder propertiesBuilder = new DeploymentPropertiesBuilder();
propertiesBuilder.memory("log", 512);
propertiesBuilder.count("log",2);
propertiesBuilder.put("app.splitter.producer.partitionKeyExpression", "payload");
return propertiesBuilder.build();
}在这种情况下,除了为日志应用程序设置deployer属性count之外,还会在部署时覆盖应用程序属性。使用流畅样式时,使用方法addDeploymentProperty(例如,new StreamApplication("log").addDeploymentProperty("count", 2))添加部署属性,并且不需要使用deployer.<app_name>为属性添加前缀。
要创建和部署流,您需要确保首先在DataFlow服务器中注册了相应的应用程序。尝试创建或部署包含未知应用程序的流会引发异常。您可以使用DataFlowTemplate注册您的申请,如下所示:
|
dataFlowOperations.appRegistryOperations().importFromResource(
"http://bit.ly/Darwin-SR3-stream-applications-rabbit-maven", true);Stream应用程序也可以是应用程序中的bean,这些bean在其他类中注入以创建Streams。构造Spring应用程序的方法有很多,但一种方法是让@Configuration类定义StreamBuilder和StreamApplications,如下例所示:
@Configuration
public class StreamConfiguration {
@Bean
public StreamBuilder builder() {
return Stream.builder(new DataFlowTemplate(URI.create("http://localhost:9393")));
}
@Bean
public StreamApplication httpSource(){
return new StreamApplication("http");
}
@Bean
public StreamApplication logSink(){
return new StreamApplication("log");
}
}然后在另一个类中,您可以@Autowire这些类并部署流。
@Component
public class MyStreamApps {
@Autowired
private StreamBuilder streamBuilder;
@Autowired
private StreamApplication httpSource;
@Autowired
private StreamApplication logSink;
public void deploySimpleStream() {
Stream simpleStream = streamBuilder.name("simpleStream")
.source(httpSource)
.sink(logSink)
.create()
.deploy();
}
}此样式允许您跨多个Streams共享StreamApplications。
35.3.使用DeploymentPropertiesBuilder
无论您选择何种样式,deploy(Map<String, String> deploymentProperties)方法都可以自定义流的部署方式。我们通过使用构建器样式更容易创建具有属性的映射,以及为某些属性创建静态方法,因此您无需记住此类属性的名称。如果您采用前面的createDeploymentProperties示例,则可以将其重写为:
private Map<String, String> createDeploymentProperties() {
return new DeploymentPropertiesBuilder()
.count("log", 2)
.memory("log", 512)
.put("app.splitter.producer.partitionKeyExpression", "payload")
.build();
}此实用程序类旨在帮助创建Map并添加一些方法来帮助定义预定义的属性。
35.4.使用Skipper进行部署
如果您希望使用Skipper部署流,则需要将某些属性传递给特定于基于Skipper的部署的服务器,例如选择目标平台。SkipperDeploymentPropertiesBuilder为您提供DeploymentPropertiesBuilder中的所有属性,并添加了Skipper所需的属性。
private Map<String, String> createDeploymentProperties() {
return new SkipperDeploymentPropertiesBuilder()
.count("log", 2)
.memory("log", 512)
.put("app.splitter.producer.partitionKeyExpression", "payload")
.platformName("pcf")
.build();
}36.使用多个Binder配置流应用程序
在某些情况下,当流需要连接到不同的消息传递中间件配置时,流可以将其应用程序绑定到多个spring cloud流绑定器。在这些情况下,确保使用其活页夹配置正确配置应用程序非常重要。例如,支持Kafka和Rabbit绑定器的多绑定器转换器是以下流中的处理器:
http | multibindertransform --expression=payload.toUpperCase() | log| 在上面的示例中,您将编写自己的multibindertransform应用程序。 |
在此流中,每个应用程序通过以下方式连接到消息传递中间件:
-
HTTP源将事件发送到RabbitMQ(
rabbit1)。 -
多Binder变换处理器从RabbitMQ(
rabbit1)接收事件,并将处理后的事件发送到Kafka(kafka1)。 -
日志接收器从Kafka(
kafka1)接收事件。
这里,rabbit1和kafka1是spring cloud流应用程序属性中给出的绑定器名称。基于此设置,应用程序在其类路径中具有以下具有适当配置的绑定器:
-
HTTP:Rabbit绑定器
-
变换:Kafka和Rabbit两个绑定器
-
记录:Kafka粘合剂
可以在应用程序本身中设置spring-cloud-stream binder配置属性。如果不是,则在部署流时可以通过deployment属性传递它们,如以下示例所示:
dataflow:>stream create --definition "http | multibindertransform --expression=payload.toUpperCase() | log" --name mystream
dataflow:>stream deploy mystream --properties "app.http.spring.cloud.stream.bindings.output.binder=rabbit1,app.multibindertransform.spring.cloud.stream.bindings.input.binder=rabbit1,
app.multibindertransform.spring.cloud.stream.bindings.output.binder=kafka1,app.log.spring.cloud.stream.bindings.input.binder=kafka1"可以通过部署属性指定任何绑定器配置属性来覆盖它们。
37.例子
本章包括以下示例:
您可以在“ 样本 ”一章中找到更多样本的链接。
37.1.简单的流处理
作为简单处理步骤的示例,我们可以使用以下流定义将HTTP发布数据的有效负载转换为大写:http | transform --expression=payload.toUpperCase() | log
要创建此流,请在shell中输入以下命令
dataflow:> stream create --definition "http --server.port=9000 | transform --expression=payload.toUpperCase() | log" --name mystream --deploy以下示例使用shell命令发布一些数据:
dataflow:> http post --target http://localhost:9000 --data "hello"前面的示例在日志中生成大写的“HELLO”,如下所示:
2016-06-01 09:54:37.749 INFO 80083 --- [ kafka-binder-] log.sink : HELLO
37.2.有状态流处理
为了演示数据分区功能,以下列表部署了一个以Kafka作为绑定器的流:
dataflow:>stream create --name words --definition "http --server.port=9900 | splitter --expression=payload.split(' ') | log"
Created new stream 'words'
dataflow:>stream deploy words --properties "app.splitter.producer.partitionKeyExpression=payload,deployer.log.count=2"
Deployed stream 'words'
dataflow:>http post --target http://localhost:9900 --data "How much wood would a woodchuck chuck if a woodchuck could chuck wood"
> POST (text/plain;Charset=UTF-8) http://localhost:9900 How much wood would a woodchuck chuck if a woodchuck could chuck wood
> 202 ACCEPTED然后,您应该在服务器日志中看到以下内容:
2016-06-05 18:33:24.982 INFO 58039 --- [nio-9393-exec-9] o.s.c.d.spi.local.LocalAppDeployer : deploying app words.log instance 0
Logs will be in /var/folders/c3/ctx7_rns6x30tq7rb76wzqwr0000gp/T/spring-cloud-dataflow-694182453710731989/words-1465176804970/words.log
2016-06-05 18:33:24.988 INFO 58039 --- [nio-9393-exec-9] o.s.c.d.spi.local.LocalAppDeployer : deploying app words.log instance 1
Logs will be in /var/folders/c3/ctx7_rns6x30tq7rb76wzqwr0000gp/T/spring-cloud-dataflow-694182453710731989/words-1465176804970/words.log查看words.log instance 0日志时,您应该看到以下内容:
2016-06-05 18:35:47.047 INFO 58638 --- [ kafka-binder-] log.sink : How
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck查看words.log instance 1日志时,您应该看到以下内容:
2016-06-05 18:35:47.047 INFO 58639 --- [ kafka-binder-] log.sink : much
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : wood
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : would
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : if
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : could
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : wood此示例显示包含相同单词的有效内容拆分将路由到同一应用程序实例。
37.3.其他源和接收器应用程序类型
这个例子显示了一些更复杂的东西:换掉time源代码。另一种受支持的源类型是http,它接受通过HTTP POST提取的数据。请注意,http源接受来自数据流服务器的不同端口上的数据(默认为8080)。默认情况下,端口是随机分配的。
要使用http源创建流但仍使用相同的log接收器,我们会将Simple Stream Processing示例中的原始命令更改为以下内容:
`dataflow:> stream create --definition“http | log”--name myhttpstream --deploy
上述命令从服务器生成以下输出:
2016-06-01 09:47:58.920 INFO 79016 --- [io-9393-exec-10] o.s.c.d.spi.local.LocalAppDeployer : deploying app myhttpstream.log instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/myhttpstream-1464788878747/myhttpstream.log
2016-06-01 09:48:06.396 INFO 79016 --- [io-9393-exec-10] o.s.c.d.spi.local.LocalAppDeployer : deploying app myhttpstream.http instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/myhttpstream-1464788886383/myhttpstream.http请注意,在我们实际发布一些数据之前,我们没有看到任何其他输出(通过使用shell命令)。要查看http源正在侦听的随机分配的端口,请运行以下命令:
dataflow:> runtime apps
您应该看到相应的http源具有url属性,其中包含正在侦听的主机和端口信息。您现在可以发布到该URL,如以下示例所示:
dataflow:> http post --target http://localhost:1234 --data "hello"
dataflow:> http post --target http://localhost:1234 --data "goodbye"然后,流将数据从http源汇集到日志接收器实现的输出日志,产生类似于以下内容的输出:
2016-06-01 09:50:22.121 INFO 79654 --- [ kafka-binder-] log.sink : hello
2016-06-01 09:50:26.810 INFO 79654 --- [ kafka-binder-] log.sink : goodbye我们还可以更改接收器实现。您可以将输出传递给文件(file),hadoop(hdfs)或任何其他可用的接收器应用程序。您还可以定义自己的应用程序。
带船长的流
带有Skipper的Stream Lifecycle部分涵盖了Skipper在Spring Cloud Data Flow中的整体角色。
本节是“ 部署流”的入门部分的延续,并展示了如何使用本地数据流服务器和Skipper更新和回滚Streams。“ 入门 ”一章从部署了Stream httptest开始。本章将继续“入门”一章的结尾。Stream包含两个应用程序,http源和log接收器。如果执行Unix jps命令,则可以看到正在运行的两个java进程,如下面的清单所示:
$ jps | grep rabbit
12643 log-sink-rabbit-1.1.0.RELEASE.jar
12645 http-source-rabbit-1.2.0.RELEASE.jar38.升级
在我们开始将log-sink版本升级到1.2.0.RELEASE之前,我们必须在app注册表中注册该版本。
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.0.RELEASE
Successfully registered application 'sink:log'由于我们使用的是本地服务器,因此我们需要将端口设置为与当前运行的日志接收器的值9000不同的值(9002),以避免冲突。我们在此时,我们将日志级别更新为ERROR。为此,我们创建了一个名为local-log-update.yml的YAML文件,其中包含以下内容:
version:
log: 1.2.0.RELEASE
app:
log:
server.port: 9002
log.level: ERROR现在我们更新Stream,如下所示:
dataflow:> stream update --name httptest --propertiesFile /home/mpollack/local-log-update.yml
Update request has been sent for the stream 'httptest'通过执行Unix jps命令,您可以看到两个java进程正在运行,但现在日志应用程序是版本1.2.0.RELEASE,如下面的清单所示:
$ jps | grep rabbit
22034 http-source-rabbit-1.2.0.RELEASE.jar
22031 log-sink-rabbit-1.1.0.RELEASE.jar现在您可以查看Skipper服务器的日志文件。为此,请使用以下命令:
cd到目录/tmp/spring-cloud-dataflow-5262910238261867964/httptest-1511749222274/httptest.log-v2和tail -f stdout_0.log
您应该看到类似于以下内容的日志条目:
INFO 12591 --- [ StateUpdate-1] o.s.c.d.spi.local.LocalAppDeployer : Deploying app with deploymentId httptest.log-v2 instance 0.
Logs will be in /tmp/spring-cloud-dataflow-5262910238261867964/httptest-1511749222274/httptest.log-v2
INFO 12591 --- [ StateUpdate-1] o.s.c.s.s.d.strategies.HealthCheckStep : Waiting for apps in release httptest-v2 to be healthy.
INFO 12591 --- [ StateUpdate-1] o.s.c.s.s.d.s.HandleHealthCheckStep : Release httptest-v2 has been DEPLOYED
INFO 12591 --- [ StateUpdate-1] o.s.c.s.s.d.s.HandleHealthCheckStep : Apps in release httptest-v2 are healthy.现在,您可以将消息发送到端口9000的http源,如下所示:
dataflow:> http post --target http://localhost:9000 --data "hello world upgraded"现在,日志消息处于错误级别,如以下示例所示:
ERROR 22311 --- [http.httptest-1] log-sink : hello world upgraded如果查询应用程序的/info端点,您还可以看到它的版本为1.2.0.RELEASE,如以下示例所示:
$ curl http://localhost:9002/info
{"app":{"description":"Spring Cloud Stream Log Sink Rabbit Binder Application","name":"log-sink-rabbit","version":"1.2.0.RELEASE"}}38.1.强制升级流
升级流时,即使没有更改应用程序或部署属性, - force选项也可用于部署当前部署的应用程序的新实例。当应用程序本身在启动时获取配置信息时,例如从Spring Cloud Config Server获取配置信息时,需要此行为。您可以使用选项--app-names指定要强制升级的应用程序。如果未指定任何应用程序名称,则将强制升级所有应用程序。您可以将--force和--app-names选项与--properties或--propertiesFile选项一起指定。
38.2.在Stream更新期间覆盖属性
在流更新期间传递的属性将添加到同一流的现有属性之上。
例如,部署流ticktock时没有任何显式属性,如下所示:
dataflow:>stream create --name ticktock --definition "time | log --name=mylogger"
Created new stream 'ticktock'
dataflow:>stream deploy --name ticktock
Deployment request has been sent for stream 'ticktock'dataflow:>stream manifest --name ticktock
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "time"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:time-source-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "time"
"spring.cloud.stream.metrics.key": "ticktock.time.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.output.producer.requiredGroups": "ticktock"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.stream.bindings.output.destination": "ticktock.time"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "source"
"deploymentProperties":
"spring.cloud.deployer.group": "ticktock"
---
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "log"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:log-sink-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "log"
"spring.cloud.stream.metrics.key": "ticktock.log.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.input.group": "ticktock"
"log.name": "mylogger"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "sink"
"spring.cloud.stream.bindings.input.destination": "ticktock.time"
"deploymentProperties":
"spring.cloud.deployer.group": "ticktock"在第二次更新中,我们尝试为log application foo2=bar2添加新属性。
dataflow:>stream update --name ticktock --properties app.log.foo2=bar2
Update request has been sent for the stream 'ticktock'
dataflow:>stream manifest --name ticktock
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "time"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:time-source-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "time"
"spring.cloud.stream.metrics.key": "ticktock.time.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.output.producer.requiredGroups": "ticktock"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.stream.bindings.output.destination": "ticktock.time"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "source"
"deploymentProperties":
"spring.cloud.deployer.group": "ticktock"
---
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "log"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:log-sink-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "log"
"spring.cloud.stream.metrics.key": "ticktock.log.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.input.group": "ticktock"
"log.name": "mylogger"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "sink"
"foo2": "bar2" (1)
"spring.cloud.stream.bindings.input.destination": "ticktock.time"
"deploymentProperties":
"spring.cloud.deployer.count": "1"
"spring.cloud.deployer.group": "ticktock"
dataflow:>stream list
╔═══════════╤══════════════════════════════════════════╤═════════════════════════════════════════╗
║Stream Name│ Stream Definition │ Status ║
╠═══════════╪══════════════════════════════════════════╪═════════════════════════════════════════╣
║ticktock │time | log --log.name=mylogger --foo2=bar2│The stream has been successfully deployed║
╚═══════════╧══════════════════════════════════════════╧═════════════════════════════════════════╝| 1 | 属性foo2=bar2适用于log应用程序。 |
现在,当我们向log应用程序添加另一个属性foo3=bar3时,此新属性将添加到流ticktock的现有属性之上。
dataflow:>stream update --name ticktock --properties app.log.foo3=bar3
Update request has been sent for the stream 'ticktock'
dataflow:>stream manifest --name ticktock
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "time"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:time-source-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "time"
"spring.cloud.stream.metrics.key": "ticktock.time.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.output.producer.requiredGroups": "ticktock"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.stream.bindings.output.destination": "ticktock.time"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "source"
"deploymentProperties":
"spring.cloud.deployer.group": "ticktock"
---
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "log"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:log-sink-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "log"
"spring.cloud.stream.metrics.key": "ticktock.log.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.input.group": "ticktock"
"log.name": "mylogger"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "sink"
"foo2": "bar2" (1)
"spring.cloud.stream.bindings.input.destination": "ticktock.time"
"foo3": "bar3" (1)
"deploymentProperties":
"spring.cloud.deployer.count": "1"
"spring.cloud.deployer.group": "ticktock"| 1 | foo3=bar3与log应用程序的现有foo2=bar2一起添加。 |
我们仍然可以覆盖现有属性,如下所示:
dataflow:>stream update --name ticktock --properties app.log.foo3=bar4
Update request has been sent for the stream 'ticktock'
dataflow:>stream manifest ticktock
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "time"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:time-source-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "time"
"spring.cloud.stream.metrics.key": "ticktock.time.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.output.producer.requiredGroups": "ticktock"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.stream.bindings.output.destination": "ticktock.time"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "source"
"deploymentProperties":
"spring.cloud.deployer.group": "ticktock"
---
"apiVersion": "skipper.spring.io/v1"
"kind": "SpringCloudDeployerApplication"
"metadata":
"name": "log"
"spec":
"resource": "maven://org.springframework.cloud.stream.app:log-sink-rabbit"
"resourceMetadata": "maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.3.1.RELEASE"
"version": "1.3.1.RELEASE"
"applicationProperties":
"spring.metrics.export.triggers.application.includes": "integration**"
"spring.cloud.dataflow.stream.app.label": "log"
"spring.cloud.stream.metrics.key": "ticktock.log.${spring.cloud.application.guid}"
"spring.cloud.stream.bindings.input.group": "ticktock"
"log.name": "mylogger"
"spring.cloud.stream.metrics.properties": "spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*"
"spring.cloud.dataflow.stream.name": "ticktock"
"spring.cloud.dataflow.stream.app.type": "sink"
"foo2": "bar2" (1)
"spring.cloud.stream.bindings.input.destination": "ticktock.time"
"foo3": "bar4" (1)
"deploymentProperties":
"spring.cloud.deployer.count": "1"
"spring.cloud.deployer.group": "ticktock"| 1 | 属性foo3被替换为新值`bar4`,现有属性foo2=bar2仍然存在。 |
38.3.流历史
在下面的示例中,可以通过运行stream history命令来查看流的历史记录,如图所示(及其输出):
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║2 │Mon Nov 27 22:41:16 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝38.4.流清单
清单是一个YAML文档,表示部署到平台的最终状态。您可以使用stream manifest --name <name-of-stream> --releaseVersion <optional-version>命令查看任何流版本的清单。如果未指定--releaseVersion,则返回上一版本的清单。以下清单显示了典型的stream manifest命令及其输出:
dataflow:>stream manifest --name httptest
---
# Source: log.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: log
spec:
resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: log
spring.cloud.stream.metrics.key: httptest.log.${spring.cloud.application.guid}
spring.cloud.stream.bindings.input.group: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: sink
spring.cloud.stream.bindings.input.destination: httptest.http
deploymentProperties:
spring.cloud.deployer.indexed: true
spring.cloud.deployer.group: httptest
spring.cloud.deployer.count: 1
---
# Source: http.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: http
spec:
resource: maven://org.springframework.cloud.stream.app:http-source-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: http
spring.cloud.stream.metrics.key: httptest.http.${spring.cloud.application.guid}
spring.cloud.stream.bindings.output.producer.requiredGroups: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
server.port: 9000
spring.cloud.stream.bindings.output.destination: httptest.http
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: source
deploymentProperties:
spring.cloud.deployer.group: httptest大多数部署和应用程序属性都是由Data Flow设置的,以便使应用程序能够相互通信并使用标识标签发送应用程序指标。
如果将此YAML文档与--releaseVersion=1的文档进行比较,您将看到日志应用程序版本的差异。
39.回滚
要返回到先前版本的流,请使用stream rollback命令,如下所示(显示其输出):
dataflow:>stream rollback --name httptest
Rollback request has been sent for the stream 'httptest'通过执行Unix jps命令,您可以看到两个java进程正在运行,但现在日志应用程序又返回到1.1.0.RELEASE。http源进程保持不变。以下清单显示了jps命令和典型输出:
$ jps | grep rabbit
22034 http-source-rabbit-1.2.0.RELEASE.jar
23939 log-sink-rabbit-1.1.0.RELEASE.jar现在使用以下命令查看skipper服务器的日志文件:
cd到目录/tmp/spring-cloud-dataflow-3784227772192239992/httptest-1511755751505/httptest.log-v3和tail -f stdout_0.log
您应该看到类似于以下内容的日志条目:
INFO 21487 --- [ StateUpdate-2] o.s.c.d.spi.local.LocalAppDeployer : Deploying app with deploymentId httptest.log-v3 instance 0.
Logs will be in /tmp/spring-cloud-dataflow-3784227772192239992/httptest-1511755751505/httptest.log-v3
INFO 21487 --- [ StateUpdate-2] o.s.c.s.s.d.strategies.HealthCheckStep : Waiting for apps in release httptest-v3 to be healthy.
INFO 21487 --- [ StateUpdate-2] o.s.c.s.s.d.s.HandleHealthCheckStep : Release httptest-v3 has been DEPLOYED
INFO 21487 --- [ StateUpdate-2] o.s.c.s.s.d.s.HandleHealthCheckStep : Apps in release httptest-v3 are healthy.现在将消息发送到端口9000的http源,如下所示:
dataflow:> http post --target http://localhost:9000 --data "hello world upgraded"日志接收器中的日志消息现在返回到信息错误级别,如以下示例所示:
INFO 23939 --- [http.httptest-1] log-sink : hello world rollbackhistory命令现在显示已部署流的第三个版本,如下所示(及其输出):
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║3 │Mon Nov 27 23:01:13 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║2 │Mon Nov 27 22:41:16 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝如果查看版本3的清单,可以看到它显示了日志接收器的版本1.1.0.RELEASE。
流开发者指南
40.预建应用程序
该Spring Cloud Stream应用启动器项目提供了可以开始使用的时候了很多应用。例如,有一个HTTP源应用程序,它接收发布到HTTP端点的消息,并将数据发布到消息传递中间件。每个现有应用程序有三种变体,每种变体对应支持的每种类型的消息传递中间件。当前支持的消息传递中间件系统是RabbitMQ,Apache Kafka 0.9和Apache Kafka 0.10。所有应用程序都基于Spring Boot和Spring Cloud Stream。
应用程序将作为Maven工件和Docker镜像发布。对于GA版本,Maven工件发布到Maven central和Spring Release Repository。里程碑和快照版本分别发布到Spring里程碑和Spring快照存储库。Docker镜像被推送到Docker Hub。
我们在示例中使用Maven工件。承载预构建应用程序的GA工件的Spring Repository的根位置是repo.spring.io/release/org/springframework/cloud/stream/app/
41.运行预建应用程序
在此示例中,我们使用RabbitMQ作为消息传递中间件。按照rabbitmq.com上的说明为您的平台。然后安装管理插件。
我们将首先使用java -jar将HTTP源应用程序和日志接收器作为独立应用程序运行。这两个应用程序使用RabbitMQ进行通信。
下载每个示例应用程序,如下所示:
wget https://repo.spring.io/libs-release/org/springframework/cloud/stream/app/http-source-rabbit/1.3.1.RELEASE//http-source-rabbit-1.3.1.RELEASE.jar
wget https://repo.spring.io/release/org/springframework/cloud/stream/app/log-sink-rabbit/1.3.1.RELEASE/log-sink-rabbit-1.3.1.RELEASE.jar这些是Spring Boot应用程序,包括Spring Boot Actuator和Spring Security Starter。您可以指定常用的Spring Boot属性来配置每个应用程序。Spring应用程序启动程序的文档中列出了特定于每个应用程序的属性- 例如,HTTP源和日志接收器
现在您可以运行http源应用程序。只是为了好玩,使用系统属性传递一些Boot应用程序选项,如以下示例所示:
java -Dserver.port=8123 -Dhttp.path-pattern=/data -Dspring.cloud.stream.bindings.output.destination=sensorData -jar http-source-rabbit-1.3.1.RELEASE.jarserver.port属性来自Spring Boot Web支持,http.path-pattern属性来自HTTP源应用程序HttpSourceProperties。HTTP源应用程序现在正在路径/data下的端口8123上进行侦听。
spring.cloud.stream.bindings.output.destination属性来自Spring Cloud Stream库,是源和接收器之间共享的消息传递目标的名称。此属性中的字符串sensorData是Spring Integration通道的名称,其内容将发布到消息传递中间件。
现在,您可以运行日志接收器应用程序并将日志记录级别更改为WARN,如下所示:
java -Dlog.level=WARN -Dspring.cloud.stream.bindings.input.destination=sensorData -jar log-sink-rabbit-1.3.1.RELEASE.jarlog.level属性来自日志接收器应用程序LogSinkProperties。
属性spring.cloud.stream.bindings.input.destination的值设置为sensorData,以便源和接收器应用程序可以相互通信。
您可以使用以下curl命令将数据发送到http应用程序:
curl -H "Content-Type: application/json" -X POST -d '{"id":"1","temperature":"100"}' http://localhost:8123/data然后,日志接收器应用程序显示以下输出:
2017-03-17 15:30:17.825 WARN 22710 --- [_qquaYekbQ0nA-1] log-sink : {"id":"1","temperature":"100"}42.定制处理器应用程序
现在,您可以创建并测试对HTTP源的输出执行某些处理的应用程序,然后将数据发送到日志接收器。然后,您可以使用处理器便捷类,该类具有入站通道和出站通道。
为此:
-
访问Spring Initialzr网站。
-
创建一个新的Maven项目,其组名为
io.spring.stream.sample,工件名称为transformer。 -
在“依赖关系”文本框中,键入
stream以选择Spring Cloud Stream依赖关系。 -
在“依赖关系”文本框中,键入
kafka或rabbit并选择要使用的中间件。 -
单击“ 生成项目”按钮
-
-
解压缩项目并将项目带入您喜欢的IDE中。
-
在
io.spring.stream.sample包中创建一个名为Transformer的类,其中包含以下内容:package io.spring.stream.sample; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.annotation.Output; import org.springframework.cloud.stream.annotation.StreamListener; import org.springframework.cloud.stream.messaging.Processor; import org.springframework.messaging.handler.annotation.Payload; import java.util.HashMap; import java.util.Map; @EnableBinding(Processor.class) public class Transformer { @StreamListener(Processor.INPUT) @Output(Processor.OUTPUT) public Map<String, Object> transform(@Payload Map<String, Object> doc) { Map<String, Object> map = new HashMap<>(); map.put("sensor_id", doc.getOrDefault("id", "-1")); map.put("temp_val", doc.getOrDefault("temperature", "-999")); return map; } }此处理器正在执行的所有操作是更改映射中键的名称,并提供默认值(如果不存在)。
-
打开
TransformerApplicationTests类(已经存在)并为Transformer类创建一个简单的单元测试,如以下示例所示:package io.spring.stream.sample; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import java.util.HashMap; import java.util.Map; import static org.assertj.core.api.Assertions.assertThat; import static org.assertj.core.api.Assertions.entry; @RunWith(SpringRunner.class) @SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT) public class TransformerApplicationTests { @Autowired private Transformer transformer; @Test public void simpleTest() { Map<String, Object> resultMap = transformer.transform(createInputData()); assertThat(resultMap).hasSize(2) .contains(entry("sensor_id", "1")) .contains(entry("temp_val", "100")); } private Map<String, Object> createInputData() { HashMap<String, Object> inputData = new HashMap<>(); inputData.put("id", "1"); inputData.put("temperature", "100"); return inputData; } }
在变换器项目的根目录中执行./mvnw clean package会在target目录下生成工件transformer-0.0.1-SNAPSHOT.jar。
现在您可以运行所有三个应用程序,如下面的清单所示:
java -Dserver.port=8123 \
-Dhttp.path-pattern=/data \
-Dspring.cloud.stream.bindings.output.destination=sensorData \
-jar http-source-rabbit-1.3.1.RELEASE.jar
java -Dserver.port=8090 \
-Dspring.cloud.stream.bindings.input.destination=sensorData \
-Dspring.cloud.stream.bindings.output.destination=normalizedSensorData \
-jar transformer-0.0.1-SNAPSHOT.jar
java -Dlog.level=WARN \
-Dspring.cloud.stream.bindings.input.destination=normalizedSensorData \
-jar log-sink-rabbit-1.3.1.RELEASE.jar现在您可以将一些内容发布到http源应用程序,如下所示:
curl -H "Content-Type: application/json" -X POST -d '{"id":"2","temperature":"200"}' http://localhost:8123/data前面的curl命令导致日志接收器显示以下输出:
2017-03-24 16:09:42.726 WARN 7839 --- [Raj4gYSoR_6YA-1] log-sink : {sensor_id=2, temp_val=200}43.提高服务质量
如果没有其他配置,生成数据的RabbitMQ应用程序将创建持久的主题交换。同样,使用数据的RabbitMQ应用程序会创建一个匿名自动删除队列。如果生产者应用程序在使用者应用程序之前启动,则这可能导致生成器不存储和转发消息。即使交换是持久的,也需要有一个绑定到交换的持久队列,以便存储消息以供以后使用。
要预先创建持久队列并将它们绑定到交换,生成器应用程序应设置spring.cloud.stream.bindings.<channelName>.producer.requiredGroups属性。requiredGroups属性接受以逗号分隔的组列表,生产者必须确保消息传递,即使它们在创建后启动也是如此。然后,使用者应用程序应指定要从持久队列中使用的spring.cloud.stream.bindings.<channelName>.group属性。两个属性的逗号分隔的组列表通常应该匹配。
消费者群体也是消费应用程序的多个实例可以参与与同一消费者群体的其他成员的竞争消费者关系的手段。
以下清单显示了共享相同组的多个应用程序:
java -Dserver.port=8123 \
-Dhttp.path-pattern=/data \
-Dspring.cloud.stream.bindings.output.destination=sensorData \
-Dspring.cloud.stream.bindings.output.producer.requiredGroups=sensorDataGroup \
-jar http-source-rabbit-1.3.1.RELEASE.jar
java -Dserver.port=8090 \
-Dspring.cloud.stream.bindings.input.destination=sensorData \
-Dspring.cloud.stream.bindings.input.group=sensorDataGroup \
-Dspring.cloud.stream.bindings.output.destination=normalizedSensorData \
-Dspring.cloud.stream.bindings.output.producer.requiredGroups=normalizedSensorDataGroup \
-jar transformer-0.0.1-SNAPSHOT.jar
java -Dlog.level=WARN \
-Dspring.cloud.stream.bindings.input.destination=normalizedSensorData \
-Dspring.cloud.stream.bindings.input.group=normalizedSensorDataGroup \
-jar log-sink-rabbit-1.3.1.RELEASE.jar和以前一样,将数据发布到http源会在接收器中生成相同的日志消息。
44.将应用程序映射到数据流
Spring Cloud Data Flow(SCDF)通过引入流的概念,提供了一种更高级别的方法来创建这组三个Spring Cloud Stream应用程序。通过使用类Unix管道和过滤DSL来定义流。每个应用程序首先使用简单名称注册,例如http,transformer和log(对于我们在此示例中使用的应用程序)。连接这三个应用程序的流DSL是http | transformer | log。
Spring Cloud Data Flow有服务器和shell组件。通过shell,您可以轻松地在名称下注册应用程序,还可以创建和部署流。您还可以使用JavaDSL执行相同的操作。但是,我们在本章的示例中使用shell。
在shell应用程序中,使用以下命令注册本地计算机上的jar文件。在此示例中,http和log应用程序位于/home/mpollack/temp/dev目录中,transformer应用程序位于/home/mpollack/dev-marketing/transformer/target目录中。
以下命令注册三个应用程序:
dataflow:>app register --type source --name http --uri file://home/mpollack/temp/dev/http-source-rabbit-1.2.0.BUILD-SNAPSHOT.jar
dataflow:>app register --type processor --name transformer --uri file://home/mpollack/dev-marketing/transformer/target/transformer-0.0.1-SNAPSHOT.jar
dataflow:>app register --type sink --name log --uri file://home/mpollack/temp/dev/log-sink-rabbit-1.1.1.RELEASE.jar现在,您可以使用以下命令创建流定义并进行部署:
stream create --name httpIngest --definition "http --server.port=8123 --path-pattern=/data | transformer --server.port=8090 | log --level=WARN" --deploy然后,在shell中,您可以查询流列表,如下所示(带输出):
dataflow:>stream list
╔═══════════╤════════════════════════════════════════════════════════════════════════════════════════════════╤═════════╗
║Stream Name│ Stream Definition │ Status ║
╠═══════════╪════════════════════════════════════════════════════════════════════════════════════════════════╪═════════╣
║httpIngest │http --server.port=8123 --path-pattern=/data | transformer --server.port=8090 | log --level=WARN│Deploying║
╚═══════════╧════════════════════════════════════════════════════════════════════════════════════════════════╧═════════╝最后,您可以看到状态列说Deployed。
在服务器日志中,您可以看到类似于以下内容的输出:
2017-03-24 17:12:44.071 INFO 9829 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app httpIngest.log instance 0 Logs will be in /tmp/spring-cloud-dataflow-4401025649434774446/httpIngest-1490389964038/httpIngest.log 2017-03-24 17:12:44.153 INFO 9829 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app httpIngest.transformer instance 0 Logs will be in /tmp/spring-cloud-dataflow-4401025649434774446/httpIngest-1490389964143/httpIngest.transformer 2017-03-24 17:12:44.285 INFO 9829 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app httpIngest.http instance 0 Logs will be in /tmp/spring-cloud-dataflow-4401025649434774446/httpIngest-1490389964264/httpIngest.http
您可以转到每个目录以查看每个应用程序的日志。在RabbitMQ管理控制台中,您可以看到两个交换和两个持久队列。
SCDF服务器已通过requiredGroups和group属性为每个应用程序配置了输入和输出目标,如前一个示例中明确指出的那样。
现在您可以将一些内容发布到http源应用程序,如下所示:
curl -H "Content-Type: application/json" -X POST -d '{"id":"1","temperature":"100"}' http://localhost:8123/data在日志接收器的stdout_0.log文件上使用tail命令,然后显示类似于以下列表的输出:
2017-03-24 17:29:55.280 WARN 11302 --- [er.httpIngest-1] log-sink : {sensor_id=4, temp_val=400}如果访问应用程序的Boot actuator端点,则可以看到SCDF为目标名称,使用者组和requiredGroups配置属性所做的约定,如下面的清单所示:
# for the http source
"spring.cloud.stream.bindings.output.producer.requiredGroups": "httpIngest",
"spring.cloud.stream.bindings.output.destination": "httpIngest.http",
"spring.cloud.application.group": "httpIngest",
# For the transformer
"spring.cloud.stream.bindings.input.group": "httpIngest",
"spring.cloud.stream.bindings.output.producer.requiredGroups": "httpIngest",
"spring.cloud.stream.bindings.output.destination": "httpIngest.transformer",
"spring.cloud.stream.bindings.input.destination": "httpIngest.http",
"spring.cloud.application.group": "httpIngest",
# for the log sink
"spring.cloud.stream.bindings.input.group": "httpIngest",
"spring.cloud.stream.bindings.input.destination": "httpIngest.transformer",
"spring.cloud.application.group": "httpIngest",任务
本节详细介绍了如何使用Spring Cloud Task。它涵盖了创建和运行任务应用程序等主题。
如果您刚开始使用Spring Cloud Data Flow,则在深入了解本节之前,您应该阅读“ 入门指南 ”。
45.导言
任务按需执行流程。在Spring Cloud Task的情况下,任务是使用@EnableTask注释的Spring Boot应用程序。用户启动执行特定过程的任务,一旦完成,任务就结束。与流定义最多只能有一个部署的流不同,可以同时多次启动单个任务定义。任务的一个示例是Spring Boot应用程序,它将数据从JDBC存储库导出到HDFS实例。任务记录关系数据库中的开始时间和结束时间以及引导退出代码。任务实现基于Spring Cloud Task项目。
45.1.应用属性
每个应用程序都使用属性来定制其行为。例如,timestamp任务format设置建立的输出格式与默认值不同。
dataflow:> task create --definition "timestamp --format=\"yyyy\"" --name printTimeStamp
此timestamp属性实际上与timestamp应用程序指定的timestamp.format属性相同。数据流添加了使用简写形式format而不是timestamp.format的功能。也可以指定longhand版本,如以下示例所示:
dataflow:> task create --definition "timestamp --timestamp.format=\"yyyy\"" --name printTimeStamp
有关白名单应用程序属性的部分将更详细地讨论此简写行为。如果已注册应用程序属性元数据,则可以在键入--后使用shell中的选项卡完成来获取候选属性名称列表。
shell为应用程序属性提供了Tab键完成。shell命令app info --name <appName> --type <appType>为所有支持的属性提供了附加文档。
支持的任务<appType>是任务。
|
46.任务的生命周期
在深入了解创建任务的细节之前,我们需要了解Spring Cloud Data Flow上下文中任务的典型生命周期:
46.1.创建任务应用程序
虽然Spring Cloud Task确实提供了许多开箱即用的应用程序(在spring-cloud-task-app-starters),但大多数任务应用程序都需要自定义开发。要创建自定义任务应用程序:
-
使用Spring初始化程序创建一个新项目,确保选择以下启动器:
-
Cloud Task:这种依赖是spring-cloud-starter-task。 -
JDBC:这种依赖是spring-jdbc的首发。
-
-
在新项目中,创建一个新类作为主类,如下所示:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
使用此类,您的应用程序中需要一个或多个
CommandLineRunner或ApplicationRunner实现。您可以实现自己的,也可以使用Spring Boot提供的那些(例如,有一个用于运行批处理作业)。 -
使用Spring Boot将应用程序打包到超级jar中是通过标准Spring Boot约定完成的。可以如下所述注册和部署打包的应用程序。
46.1.1.任务数据库配置
| 启动任务应用程序时,请确保Spring Cloud Data Flow正在使用的数据库驱动程序也是对任务应用程序的依赖关系。例如,如果您的Spring Cloud Data Flow设置为使用Postgresql,请确保任务应用程序还将Postgresql作为依赖项。 |
| 当您在外部运行任务(即从命令行)并且希望Spring Cloud Data Flow在其UI中显示TaskExecutions时,请确保在两者之间共享公共数据源设置。默认情况下,Spring Cloud Task使用本地H2实例,执行将记录到Spring Cloud Data Flow使用的数据库中。 |
46.2.注册任务应用程序
您可以使用Spring Cloud Data Flow Shell app register命令在App Registry中注册Task App。您必须提供可以解析为应用程序工件的唯一名称和URI。对于类型,请指定“任务”。以下列表显示了三个示例:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri http://example.com/mytask-1.0.2.jar提供带有maven方案的URI时,格式应符合以下条件:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>
如果您想一次注册多个应用程序,可以将它们存储在属性文件中,其中键的格式为<type>.<name>,值为URI。例如,以下列表将是有效的属性文件:
task.foo=file:///tmp/foo-1.2.1.BUILD-SNAPSHOT.jar
task.bar=file:///tmp/bar-1.2.1.BUILD-SNAPSHOT.jar然后,您可以使用app import命令并使用--uri选项提供属性文件的位置,如下所示:
app import --uri file:///tmp/task-apps.properties为方便起见,我们为所有开箱即用的Task app-starters提供了带有application-URI(适用于maven和docker)的静态文件。您可以指向此文件并批量导入所有应用程序URI。否则,如本章前面所述,您可以单独注册它们,也可以拥有自己的自定义属性文件,其中只包含所需的应用程序URI。但是,建议在自定义属性文件中包含所需应用程序URI的“聚焦”列表。
下表列出了可用的静态属性文件:
| 神器类型 | 稳定释放 | SNAPSHOT发布 |
|---|---|---|
Maven |
||
Docker |
例如,如果要批量注册所有现成的任务应用程序,可以使用以下命令执行此操作:
dataflow:>app import --uri http://bit.ly/Clark-GA-task-applications-maven您还可以传递--local选项(默认为TRUE)以指示是否应在shell进程本身内解析属性文件位置。如果应从数据流服务器进程解析位置,请指定--local false。
使用app register或app import时,如果任务应用程序已使用提供的名称注册,则默认情况下不会覆盖它。如果要覆盖预先存在的任务应用程序,请包含--force选项。
| 在某些情况下,资源在服务器端解析。在其他情况下,URI将传递到解析它的运行时容器实例。有关更多详细信息,请参阅每个数据流服务器的特定文档。 |
46.3.创建任务定义
您可以通过提供定义名称以及适用于任务执行的属性,从任务应用程序创建任务定义。可以通过RESTful API或shell来创建任务定义。要使用shell创建任务定义,请使用task create命令创建任务定义,如以下示例所示:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'可以通过RESTful API或shell获取当前任务定义的列表。要使用shell获取任务定义列表,请使用task list命令。
46.4.启动任务
可以通过RESTful API或shell启动adhoc任务。要通过shell启动临时任务,请使用task launch命令,如以下示例所示:
dataflow:>task launch mytask
Launched task 'mytask'启动任务时,可以在启动任务时设置需要作为命令行参数传递给任务应用程序的任何属性,如下所示:
dataflow:>task launch mytask --arguments "--server.port=8080 --custom=value"
参数需要作为space分隔值传递。
|
可以使用--properties选项传入适用于TaskLauncher本身的附加属性。此选项的格式是以逗号分隔的属性字符串,前缀为app.<task definition name>.<property>。Properties作为应用程序属性传递给TaskLauncher。由实现来决定如何将它们传递到实际的任务应用程序中。如果属性的前缀为deployer而不是app,则将其作为部署属性传递给TaskLauncher,其含义可能是TaskLauncher特定于实现。
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"
46.4.1.常见的应用属性
除了通过DSL进行配置外,Spring Cloud Data Flow还提供了一种机制,用于为其启动的所有任务应用程序设置公共属性。这可以通过在启动服务器时添加前缀为spring.cloud.dataflow.applicationProperties.task的属性来完成。执行此操作时,服务器将所有不带前缀的属性传递给它启动的实例。
例如,通过使用以下选项启动数据流服务器,可以将所有已启动的应用程序配置为使用属性prop1和prop2:
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2这会将属性prop1=value1和prop2=value2传递给所有已启动的应用程序。
使用此机制配置的Properties优先级低于任务部署属性。如果在任务启动时指定了具有相同键的属性,则会覆盖它们(例如,app.trigger.prop2会覆盖公共属性)。
|
46.5.限制并发任务启动的数量
Spring Cloud Data Flow允许用户建立最大并发运行任务数,以防止IaaS /硬件资源饱和。可以通过设置spring.cloud.dataflow.task.maximum-concurrent-tasks属性来配置此限制。默认情况下,它设置为20。如果并发运行的任务数等于或大于spring.cloud.dataflow.task.maximum-concurrent-tasks设置的值,则下一个任务启动请求将被拒绝,并且将通过RESTful API,Shell或UI返回警告消息。
46.6.检查任务执行
启动任务后,任务的状态将存储在关系数据库中。该州包括:
-
任务名称
-
开始时间
-
时间结束
-
退出代码
-
退出消息
-
上次更新时间
-
参数
用户可以通过RESTful API或shell检查其任务执行的状态。要通过shell显示最新的任务执行,请使用task execution list命令。
要获取仅一个任务定义的任务执行列表,请添加--name和任务定义名称,例如task execution list --name foo。要检索任务执行的完整详细信息,请使用带有任务执行ID的task execution status命令,例如task execution status --id 549。
46.7.销毁任务定义
销毁任务定义会从定义存储库中删除定义。这可以通过RESTful API或shell来完成。要通过shell销毁任务,请使用task destroy命令,如以下示例所示:
dataflow:>task destroy mytask
Destroyed task 'mytask'先前为定义启动的任务的任务执行信息保留在任务存储库中。
| 这不会停止此定义的任何当前正在执行的任务。相反,它从数据库中删除任务定义。 |
46.8.验证任务
有时,任务定义中包含的一个或多个应用程序在其注册中包含无效的URI。这可能是由于在应用注册时输入的URI无效,或者应用程序已从用于绘制应用程序的存储库中删除。要验证任务中包含的所有应用程序是否可解析,用户可以使用validate命令。例如:
dataflow:>task validate time-stamp
╔══════════╤═══════════════╗
║Task Name │Task Definition║
╠══════════╪═══════════════╣
║time-stamp│timestamp ║
╚══════════╧═══════════════╝
time-stamp is a valid task.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║task:timestamp │valid ║
╚═══════════════╧═════════════════╝在上面的示例中,用户验证了他们的时间戳任务。我们看到task:timestamp app有效。现在让我们看看如果我们有一个带有无效URI的注册应用程序的流定义会发生什么。
dataflow:>task validate bad-timestamp
╔═════════════╤═══════════════╗
║ Task Name │Task Definition║
╠═════════════╪═══════════════╣
║bad-timestamp│badtimestamp ║
╚═════════════╧═══════════════╝
bad-timestamp is an invalid task.
╔══════════════════╤═════════════════╗
║ App Name │Validation Status║
╠══════════════════╪═════════════════╣
║task:badtimestamp │invalid ║
╚══════════════════╧═════════════════╝在这种情况下,Spring Cloud Data Flow表示任务无效,因为task:badtimestamp具有无效的URI。
47.订阅任务/批次Events
您还可以在启动任务时使用各种任务和批处理事件。如果启用任务以生成任务或批处理事件(具有附加依赖项spring-cloud-task-stream,并且在Kafka作为绑定程序spring-cloud-stream-binder-kafka的情况下),则在任务生命周期期间发布这些事件。默认情况下,代理(Rabbit,Kafka和其他)上发布的事件的目标名称是事件名称本身(例如:task-events,job-execution-events等) 。
dataflow:>task create myTask --definition "myBatchJob"
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deploy
dataflow:>task launch myTask您可以通过在启动任务时指定显式名称来控制这些事件的目标名称,如下所示:
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deploy
dataflow:>task launch myTask --properties "app.myBatchJob.spring.cloud.stream.bindings.task-events.destination=myTaskEvents"下表列出了代理上的默认任务和批处理事件和目标名称:
Event |
Destination |
Task events |
|
Job Execution events |
|
Step Execution events |
|
Item Read events |
|
Item Process events |
|
Item Write events |
|
Skip events |
|
48.组成的任务
Spring Cloud Data Flow允许用户创建有向图,其中图的每个节点都是任务应用程序。这是通过使用DSL进行组合任务来完成的。可以通过RESTful API,Spring Cloud Data Flow Shell或Spring Cloud Data Flow UI创建组合任务。
48.1.配置组合任务运行器
组合任务通过名为Composed Task Runner的任务应用程序执行。
48.1.1.注册Composed Task Runner
默认情况下,Composed Task Runner应用程序未注册Spring Cloud Data Flow。因此,要启动组合任务,我们必须首先将Composed Task Runner注册为具有Spring Cloud Data Flow的应用程序,如下所示:
app register --name composed-task-runner --type task --uri maven://org.springframework.cloud.task.app:composedtaskrunner-task:<DESIRED_VERSION>
您还可以配置Spring Cloud Data Flow以使用组合任务运行器的其他任务定义名称。这可以通过将spring.cloud.dataflow.task.composedTaskRunnerName属性设置为您选择的名称来完成。然后,您可以使用您使用该属性设置的名称注册组合任务运行器应用程序。
48.1.2.配置组合任务运行器
Composed Task Runner应用程序具有dataflow.server.uri属性,用于验证和启动子任务。默认为localhost:9393。如果运行分布式Spring Cloud Data Flow服务器,就像在Cloud Foundry,YARN或Kubernetes上部署服务器一样,则需要提供可用于访问服务器的URI。您可以在启动组合任务时为Composed Task Runner应用程序提供此dataflow.server.uri属性,也可以在启动时为Spring Cloud Data Flow服务器提供spring.cloud.dataflow.server.uri属性。对于后一种情况,在启动组合任务时会自动设置dataflow.server.uri Composed Task Runner应用程序属性。
在某些情况下,您可能希望通过Task Launcher接收器执行Composed Task Runner的实例。在这种情况下,您必须配置Composed Task Runner以使用Spring Cloud Data Flow实例正在使用的相同数据源。通过使用commandlineArguments或environmentProperties开关,使用TaskLaunchRequest设置数据源属性。这是因为Composed Task Runner监视task_executions表以检查它正在运行的任务的状态。使用表中的信息,它确定了如何导航图表。
配置选项
ComposedTaskRunner任务具有以下选项:
-
increment-instance-enabled 允许在不更改参数的情况下重新执行单个ComposedTaskRunner实例。默认值为false,这意味着ComposedTaskRunner实例只能使用给定的参数集执行一次,如果为true则可以重新执行。(布尔值,默认值:false)。ComposedTaskRunner使用Spring Batch构建,因此在成功执行时,批处理作业被认为是完成的。要多次启动相同的ComposedTaskRunner定义,必须将
increment-instance-enabled属性设置为true或更改每次启动的定义参数。 -
interval-time-between-checks 在检查数据库以查看任务是否已完成之前,ComposedTaskRunner将等待的时间量(毫秒)。(整数,默认值:10000)。ComposedTaskRunner使用数据存储区来确定每个子任务的状态。此间隔向ComposedTaskRunner指示它应检查其子任务的状态的频率。
-
max-wait-time 在执行Composed任务失败之前,单个步骤可以运行的最大时间(以毫秒为单位)(整数,默认值:0)。确定在CTR终止失败之前允许每个子任务运行的最长时间。默认值
0表示没有超时。 -
split-thread-allow-core-thread-timeout 指定是否允许拆分核心线程超时。默认为false; (Boolean,default:false)设置控制核心线程是否可以超时的策略,如果在保持活动时间内没有任务到达则终止,在新任务到达时根据需要进行替换。
-
split-thread-core-pool-size Split的核心池大小。默认值为1; (整数,默认值:1)拆分中包含的每个子任务都需要一个线程才能执行。因此,例如:
<AAA || BBB || CCC> && <DDD || EEE>这样的定义需要拆分线程 - 核心池大小为3.这是因为最大的拆分包含3个子任务。计数为2表示AAA和BBB并行运行,但CCC会等到AAA或BBB完成才能运行。然后DDD和EEE并行运行。 -
split-thread-keep-alive-seconds Split的线程保持活动秒数。默认值为60.(整数,默认值:60)如果池当前具有多个corePoolSize线程,则多余线程如果空闲时间超过keepAliveTime则终止。
-
split-thread-max-pool-size Split的最大池大小。默认值为{@code Integer.MAX_VALUE}(整数,默认值:<无>)。建立线程池允许的最大线程数。
-
split-thread-queue-capacity Split的BlockingQueue容量。默认值为{@code Integer.MAX_VALUE}。(整数,默认值:<无>)
-
如果运行的corePoolSize线程少于corePoolSize,则Executor总是更喜欢添加新线程而不是排队。
-
如果corePoolSize或更多线程正在运行,则Executor总是更喜欢排队请求而不是添加新线程。
-
如果请求无法排队,则会创建一个新线程,除非它超过maximumPoolSize,在这种情况下,该任务将被拒绝。
-
-
split-thread-wait-for-tasks-to-complete-on-shutdown 是否在关机时等待计划任务完成,不中断正在运行的任务并执行队列中的所有任务。默认为false; (布尔值,默认值:false)
注意当使用上面的选项作为环境变量时,转换为大写,删除短划线字符并替换为下划线字符。例如:increment-instance-enabled将为INCREMENT_INSTANCE_ENABLED。
48.2.组合任务的生命周期
组合任务的生命周期有三个部分:
48.2.1.创建组合任务
通过task create命令创建任务定义时,将使用组合任务的DSL,如以下示例所示:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:<DESIRED_VERSION>
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-task在前面的示例中,我们假设我们的组合任务要使用的应用程序尚未注册。因此,在前两个步骤中,我们注册了两个任务应用程序。然后,我们使用task create命令创建我们的组合任务定义。上例中的组合任务DSL在启动时运行mytaskapp,然后运行时间戳应用程序。
但在我们启动my-composed-task定义之前,我们可以查看为我们生成的Spring Cloud Data Flow。这可以通过执行task list命令来完成,如下图所示(包括其输出):
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝在该示例中,Spring Cloud Data Flow创建了三个任务定义,一个用于构成我们的组合任务(my-composed-task-mytaskapp和my-composed-task-timestamp)的每个应用程序以及组合任务(my-composed-task)定义。我们还看到,子任务的每个生成的名称都由组合任务的名称和应用程序的名称组成,用短划线-分隔(如在my- - composed -task mytaskapp中)。
任务应用参数
组成组合任务定义的任务应用程序也可以包含参数,如以下示例所示:
dataflow:> task create my-composed-task --definition "mytaskapp --displayMessage=hello && timestamp --format=YYYY"
48.2.2.启动组合任务
启动组合任务的方式与启动独立任务的方式相同,如下所示:
task launch my-composed-task
启动任务后,假设所有任务都成功完成,您可以在执行task execution list时看到三个任务执行,如以下示例所示:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝在前面的示例中,我们看到my-compose-task已启动,并且它还按顺序启动了其他任务。所有这些都以Exit Code 0成功执行。
将属性传递给子任务
要在任务启动时在组合任务图中设置子任务的属性,可以使用以下格式app.<composed task definition name>.<child task app name>.<property>。使用以下Composed Task定义作为示例:
dataflow:> task create my-composed-task --definition "mytaskapp && mytimestamp"要让mytaskapp显示“HELLO”并将mytimestamp timestamp格式设置为“YYYY”以进行Composed Task定义,您将使用以下任务启动格式:
task launch my-composed-task --properties "app.my-composed-task.mytaskapp.displayMessage=HELLO,app.my-composed-task.mytimestamp.timestamp.format=YYYY"与应用程序属性类似,也可以使用格式格式deployer.<composed task definition name>.<child task app name>.<deployer-property>为子任务设置deployer属性。
task launch my-composed-task --properties "deployer.my-composed-task.mytaskapp.memory=2048m,app.my-composed-task.mytimestamp.timestamp.format=HH:mm:ss"
Launched task 'a1'将参数传递给组合任务运行器
可以使用--arguments选项传递组合任务运行器的命令行参数。
例如:
dataflow:>task create my-composed-task --definition "<aaa: timestamp || bbb: timestamp>"
Created new task 'my-composed-task'
dataflow:>task launch my-composed-task --arguments "--increment-instance-enabled=true --max-wait-time=50000 --split-thread-core-pool-size=4" --properties "app.my-composed-task.bbb.timestamp.format=dd/MM/yyyy HH:mm:ss"
Launched task 'my-composed-task'退出状态
以下列表显示了如何为每个步骤执行后的组合任务中包含的每个步骤(任务)设置“退出状态”:
-
如果
TaskExecution具有ExitMessage,则用作ExitStatus。 -
如果不存在
ExitMessage并且ExitCode设置为零,则该步骤的ExitStatus为COMPLETED。 -
如果不存在
ExitMessage并且ExitCode设置为任何非零数字,则步骤的ExitStatus为FAILED。
48.2.3.破坏组合任务
用于销毁独立任务的命令与用于销毁组合任务的命令相同。唯一的区别是销毁组合任务也会破坏与之相关的子任务。以下示例显示使用destroy命令之前和之后的任务列表:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝48.2.4.停止组合任务
如果需要停止组合任务执行,您可以通过以下方式执行:
-
RESTful API
-
Spring Cloud Data Flow仪表板
要通过仪表板停止组合任务,请选择“作业”选项卡,然后单击要停止的作业执行旁边的“停止”按钮。
当前正在运行的子任务完成时,将停止组合任务运行。与组合任务停止时运行的子任务关联的步骤标记为STOPPED以及组合任务作业执行。
48.2.5.重新启动组合任务
如果组合任务在执行期间失败并且组合任务的状态为FAILED,则可以重新启动任务。你可以通过以下方式这样做:
-
RESTful API
-
贝壳
-
Spring Cloud Data Flow仪表板
要通过shell重新启动组合任务,请使用相同的参数启动任务。要通过仪表板重新启动组合任务,请选择“作业”选项卡,然后单击要重新启动的作业执行旁边的“重新启动”按钮。
重新启动已停止的组合任务作业(通过Spring Cloud Data Flow仪表板或RESTful API)重新启动STOPPED子任务,然后按指定的顺序启动剩余的(未启动的)子任务。
|
49.组成的任务DSL
组合任务可以通过三种方式运行:
49.1.条件执行
使用双符号符号(&&)表示条件执行。这使得序列中的每个任务仅在前一个任务成功完成时启动,如以下示例所示:
task create my-composed-task --definition "task1 && task2"
当启动名为my-composed-task的组合任务时,它会启动名为task1的任务,如果成功完成,则启动名为task2的任务。如果task1失败,则task2不会启动。
您还可以使用Spring Cloud Data Flow仪表板创建条件执行,方法是使用设计器拖放所需的应用程序并将它们连接在一起以创建有向图,如下图所示:
上图是使用Spring Cloud Data Flow仪表板创建的有向图的屏幕截图。您可以看到图中包含条件执行的四个组件:
-
开始图标:所有有向图都从此符号开始。只有一个。
-
任务图标:表示有向图中的每个任务。
-
结束图标:表示有向图的终止。
-
实线箭头:表示以下各项之间的流条件执行流程:
-
两个应用程序
-
启动控制节点和应用程序。
-
应用程序和结束控制节点。
-
-
结束图标:所有有向图都以此符号结束。
| 通过单击“定义”选项卡上组合任务定义旁边的“详细信息”按钮,可以查看有向图的图表。 |
49.2.过渡执行
DSL支持对有向图执行期间所进行的转换进行细粒度控制。通过基于前一任务的退出状态提供相等的条件来指定转换。任务转换由以下符号->表示。
49.2.1.基本过渡
基本过渡如下所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar 'COMPLETED' -> baz"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。如果foo的退出状态为COMPLETED,则会启动baz。foo返回的所有其他状态均无效,任务将正常终止。
使用Spring Cloud Data Flow仪表板创建相同的“basic transition”将类似于以下图像:
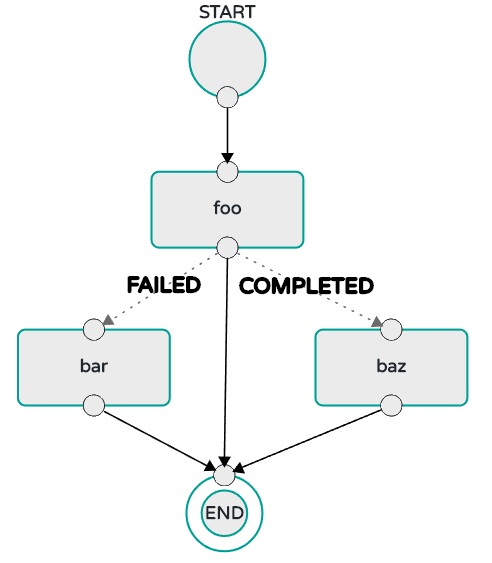
上图是在Spring Cloud Data Flow仪表板中创建的有向图的屏幕截图。请注意,有两种不同类型的连接器:
-
虚线:表示从应用程序到可能的目标应用程序之一的转换。
-
实线:连接条件执行中的应用程序或应用程序与控制节点之间的连接(开始或结束)。
要创建过渡连接器:
-
创建转换时,使用连接器将应用程序链接到每个可能的目标。
-
完成后,转到每个连接并通过单击选择它。
-
出现一个螺栓图标。
-
单击该图标。
-
输入该连接器所需的退出状态。
-
该连接器的实线变为虚线。
49.2.2.转换为通配符
通过DSL支持转换支持通配符,如下所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar '*' -> baz"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。对于除FAILED之外的任何退出状态foo,baz将启动。
使用Spring Cloud Data Flow仪表板创建相同的“带通配符的转换”将类似于以下图像:
49.2.3.通过以下条件执行进行转换
只要不使用通配符,转换后可以进行条件执行,如以下示例所示:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' -> bar 'UNKNOWN' -> baz && qux && quux"在前面的示例中,foo将启动,如果它的退出状态为FAILED,则bar任务将启动。如果foo的退出状态为UNKNOWN,则会启动baz。对于除FAILED或UNKNOWN以外的任何退出状态foo,qux将启动,并且在成功完成后,quux将启动。
使用Spring Cloud Data Flow仪表板创建相同的“条件执行转换”将类似于以下图像:
在此图中,我们看到将foo应用程序连接到目标应用程序的虚线(过渡),但是连接foo,qux和quux之间的条件执行的实线。
|
49.3.拆分执行
拆分允许组合任务中的多个任务并行运行。它通过使用尖括号(<>)来表示要并行运行的任务和流。这些任务和流由双管||符号分隔,如以下示例所示:
task create my-split-task --definition "<foo || bar || baz>"
上面的示例并行启动任务foo,bar和baz。
使用Spring Cloud Data Flow仪表板创建相同的“拆分执行”将类似于以下图像:
使用任务DSL,用户也可以连续执行多个拆分组,如以下示例所示:
`task create my-split-task --definition“<foo || bar || baz> && <qux || quux>”'
在前面的示例中,任务foo,bar和baz并行启动。一旦完成,则任务qux和quux并行启动。完成后,组合任务结束。但是,如果foo,bar或baz失败,则包含qux和quux的拆分不会启动。
使用Spring Cloud Data Flow仪表板创建相同的“具有多个组的拆分”将类似于以下图像:
请注意,在连接两个连续的分割时,设计者会插入一个SYNC控制节点。
拆分中使用的任务不应设置其ExitMessage。设置ExitMessage仅用于过渡。
|
49.3.1.拆分包含条件执行
拆分也可以在尖括号内进行条件执行,如以下示例所示:
task create my-split-task --definition "<foo && bar || baz>"
在前面的示例中,我们看到foo和baz并行启动。但是,bar在foo成功完成之前不会启动。
使用Spring Cloud Data Flow仪表板创建相同的“split containing conditional execution”类似于以下图像:

49.3.2.为拆分建立正确的线程计数
拆分中包含的每个子任务都需要一个线程才能执行。要正确设置此选项,您需要查看图形并计算具有最大子任务数的拆分,这将是您需要使用的线程数。要设置线程计数,请使用split-thread-core-pool-size属性(默认为1)。因此,例如:<AAA || BBB || CCC> && <DDD || EEE>这样的定义需要拆分线程 - 核心池大小为3.这是因为最大的拆分包含3个子任务。计数为2表示AAA和BBB并行运行,但CCC会等到AAA或BBB完成才能运行。然后DDD和EEE并行运行。
50.从流中启动任务
您可以使用其中一个可用的task-launcher接收器从流中启动任务。目前,task-launcher接收器支持的平台是:
task-launcher-local仅用于发展目的。
|
task-launcher接收器需要在其有效负载中包含TaskLaunchRequest对象的消息。从TaskLaunchRequest对象,task-launcher获取要启动的工件的URI,以及任务要使用的环境属性,命令行参数,部署属性和应用程序名称。
可以通过执行app register命令将task-launcher-local添加到可用的接收器中,如下所示(对于Rabbit Binder,在这种情况下):
app register --name task-launcher-local --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-local-sink-rabbit:jar:1.2.0.RELEASE
对于要启动的基于Maven的任务,task-launcher应用程序负责下载工件。您必须使用适当的Maven Properties配置配置task-launcher ,例如--maven.remote-repositories.repo1.url=http://repo.spring.io/libs-milestone"以解决工件(在这种情况下针对里程碑仓库)。请注意,此存储库可能与用于注册task-launcher应用程序本身的存储库不同。
50.1.TriggerTask
使用task-launcher启动任务的一种方法是使用triggertask源。triggertask源会发出一条消息,其中包含TaskLaunchRequest对象,其中包含所需的启动信息。可以通过运行app register命令将triggertask添加到可用的源中,如下所示(对于Rabbit Binder,在这种情况下):
app register --type source --name triggertask --uri maven://org.springframework.cloud.stream.app:triggertask-source-rabbit:1.2.0.RELEASE
例如,要每60秒启动一次时间戳任务,流实现将如下所示:
stream create foo --definition "triggertask --triggertask.uri=maven://org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE --trigger.fixed-delay=60 --triggertask.environment-properties='spring.datasource.url=jdbc:h2:tcp://localhost:19092/mem:dataflow,spring.datasource.username=sa' | task-launcher-local --maven.remote-repositories.repo1.url=http://repo.spring.io/libs-release" --deploy如果运行runtime apps,则可以找到任务启动程序接收器的日志文件。通过在该文件上使用tail命令,可以找到已启动任务的日志文件。设置triggertask.environment-properties将数据流服务器的H2数据库建立为将记录任务执行的数据库。然后,您可以使用shell命令task execution list查看任务执行列表,如下所示,如下所示(及其输出):
dataflow:>task execution list
╔════════════════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID│ Start Time │ End Time │Exit Code║
╠════════════════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task_26176│4 │Tue May 02 12:13:49 EDT 2017│Tue May 02 12:13:49 EDT 2017│0 ║
║timestamp-task_32996│3 │Tue May 02 12:12:49 EDT 2017│Tue May 02 12:12:49 EDT 2017│0 ║
║timestamp-task_58971│2 │Tue May 02 12:11:50 EDT 2017│Tue May 02 12:11:50 EDT 2017│0 ║
║timestamp-task_13467│1 │Tue May 02 12:10:50 EDT 2017│Tue May 02 12:10:50 EDT 2017│0 ║
╚════════════════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝50.2.TaskLaunchRequest变换
使用task-launcher启动任务的另一种方法是使用Tasklaunchrequest-transform处理器将消息有效负载转换为TaskLaunchRequest 来创建流
。
可以通过执行app register命令将tasklaunchrequest-transform添加到可用的处理器中,如下所示(对于Rabbit Binder,在这种情况下):
app register --type processor --name tasklaunchrequest-transform --uri maven://org.springframework.cloud.stream.app:tasklaunchrequest-transform-processor-rabbit:1.2.0.RELEASE
以下示例显示了包含tasklaunchrequest-transform的任务的创建:
stream create task-stream --definition "http --port=9000 | tasklaunchrequest-transform --uri=maven://org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE | task-launcher-local --maven.remote-repositories.repo1.url=http://repo.spring.io/libs-release"
50.3.从流中启动组合任务
可以使用此处讨论的task-launcher接收器之一启动组合任务。由于我们直接使用ComposedTaskRunner,因此我们需要在创建组合任务启动流之前设置它使用的任务定义。假设我们想要创建以下组合任务定义:AAA && BBB。第一步是创建任务定义,如以下示例所示:
task create AAA --definition "timestamp"
task create BBB --definition "timestamp"现在我们已经准备好了组合任务定义所需的任务定义,我们需要创建一个启动ComposedTaskRunner的流。因此,在这种情况下,我们创建一个流
-
每30秒发出一次消息的触发器
-
变压器,为收到的每条消息创建
TaskLaunchRequest -
task-launcher-local接收器在我们的本地机器上启动ComposedTaskRunner
该流应类似于以下内容:
stream create ctr-stream --definition "time --fixed-delay=30 | tasklaunchrequest-transform --uri=maven://org.springframework.cloud.task.app:composedtaskrunner-task:<current release> --command-line-arguments='--graph=AAA&&BBB --increment-instance-enabled=true --spring.datasource.url=...' | task-launcher-local"在前面的示例中,我们看到tasklaunchrequest-transform正在建立两个主要组件:
-
uri:使用的
ComposedTaskRunner的URI -
命令行参数:配置
ComposedTaskRunner
目前,我们专注于启动ComposedTaskRunner所需的配置:
-
graph:这是由
ComposedTaskRunner执行的图表。在这种情况下,它是AAA&&BBB。 -
increment-instance-enabled:这使
ComposedTaskRunner的每次执行都是唯一的。ComposedTaskRunner是使用Spring Batch构建的。因此,我们希望每次发布ComposedTaskRunner时都有一个新的作业实例。为此,我们将increment-instance-enabled设置为true。 -
spring.datasource。*:Spring Cloud数据流使用的数据源,它允许用户跟踪
ComposedTaskRunner启动的任务和作业执行的状态。此外,这使得ComposedTaskRunner可以跟踪它启动的任务的状态并更新其状态。
可在此处找到ComposedTaskRunner的版本
。
|
51.与任务共享Spring Cloud Data Flow的数据存储
正如在任务文档Spring中所讨论的,云数据流允许用户查看Spring Cloud Task应用程序执行。因此,在本节中,我们将讨论Task Application和Spring云数据流共享任务执行信息所需的内容。
51.1.通用DataStore依赖项
Spring Cloud Data Flow支持许多开箱即用的数据库类型,因此所有用户通常要做的是声明spring_datasource_*环境变量以建立需要的数据存储Spring Cloud Data Flow。因此,您决定用于Spring Cloud Data Flow的任何数据库都要确保您的任务还在其pom.xml或gradle.build文件中包含该数据库依赖项。如果任务应用程序中不存在Spring Cloud Data Flow使用的数据库依赖关系,则任务将失败并且不会记录任务执行。
51.2.通用数据存储
Spring Cloud Data Flow并且您的任务应用程序必须访问同一数据存储区实例。这样,任务应用程序记录的任务执行可以由Spring Cloud Data Flow读取,以在Shell和Dashboard视图中列出它们。此外,任务应用程序必须具有Spring Cloud Data Flow使用的任务数据表的读写权限。
鉴于对Task应用程序和Spring Cloud Data Flow之间的Datasource依赖关系的理解,让我们回顾一下如何在各种Task Orchestration场景中应用它们。
51.2.1.简单的任务启动
从Spring Cloud Data Flow启动任务时,数据流将其数据源属性(spring.datasource.url,spring.datasource.driverClassName,spring.datasource.username,spring.datasource.password)添加到正在启动的任务的应用程序属性中。因此,任务应用程序将其任务执行信息记录到Spring Cloud Data Flow存储库。
51.2.2.任务启动器接收器
该任务启动汇允许通过流启动任务,讨论在这里。由于Task Launcher Sink启动的任务可能不希望它们的任务执行记录到与Spring Cloud Data Flow相同的数据存储区 ,因此Task Launcher Sink接收的每个TaskLaunchRequest必须具有作为app属性或命令行参数建立的所需数据源信息。既TaskLaunchRequest-变换 和TriggerTask源是源和一个处理器如何允许用户通过该应用属性或命令行参数设置的数据源属性的例子。
51.2.3.组成的任务运行器
Spring Cloud Data Flow允许用户创建有向图,其中图的每个节点都是任务应用程序,这是通过
Composed Task Runner完成的。在这种情况下,应用于Simple Task Launch
或Task Launcher Sink的规则也适用于组合任务运行器。所有子应用程序还必须能够访问组合任务运行器正在使用的数据存储区。此外,所有子应用程序必须具有与其pom.xml或gradle.build文件中枚举的组合任务运行程序相同的数据库相关性。
52.安排任务
Spring Cloud Data Flow允许用户通过cron表达式安排任务的执行。可以通过RESTful API或Spring Cloud Data Flow UI创建计划。
52.1.调度程序
Spring Cloud Data Flow将通过云平台上可用的调度代理安排其任务的执行。使用Cloud Foundry平台Spring Cloud Data Flow时将使用PCF调度程序。当使用Kubernetes,一个的cronjob将被使用。

52.2.启用计划
默认情况下,Spring Cloud Data Flow会禁用调度功能。要启用计划功能,必须将以下要素属性设置为true:
-
spring.cloud.dataflow.features.schedules-enabled -
spring.cloud.dataflow.features.tasks-enabled
52.3.附表的生命周期
时间表的生命周期有两部分:
52.3.1.安排任务执行
您可以通过以下方式安排任务执行:
-
RESTful API
-
Spring Cloud Data Flow仪表板
要从UI计划任务,请单击屏幕顶部的“任务”选项卡,这将转到“任务定义”屏幕。然后,从要安排的任务定义中,单击与要安排的任务定义关联的“时钟”图标。这将引导您进入Create Schedule(s)屏幕,您将在其中为计划创建唯一名称并输入关联的cron表达式。请记住,您始终可以为单个任务定义创建多个计划。
52.3.2.删除计划
您可以通过以下方式删除计划:
-
RESTful API
-
Spring Cloud Data Flow仪表板
要通过仪表板删除计划,请选择“任务”选项卡下的“计划”选项卡,然后单击要删除的计划旁边的garbage can图标。
| 如果删除计划,则不会停止由计划代理运行的任何当前正在运行的任务。它只能防止将来执行。 |
任务开发者指南
53.预建应用程序
该Spring Cloud Task应用启动器项目提供了可以开始使用的时候了很多应用。例如,有一个时间戳应用程序将时间戳打印到控制台。所有应用程序都基于Spring Boot和Spring Cloud Task。
应用程序将作为Maven工件和Docker镜像发布。对于GA版本,Maven工件发布到Maven central和Spring Release Repository。里程碑和快照版本分别发布到Spring里程碑和Spring快照存储库。Docker镜像被推送到Docker Hub
承载预构建应用程序的GA工件的Spring Repository的根位置是repo.spring.io/release/org/springframework/cloud/task/app/
54.运行预建应用程序
您可以使用java -jar运行时间戳应用程序。
要开始使用,请下载示例应用程序,如下所示:
wget https://repo.spring.io/libs-release/org/springframework/cloud/task/app/timestamp-task/1.3.0.RELEASE/timestamp-task-1.3.0.RELEASE.jar该文件包含Spring Boot个应用程序,其中包含Spring Boot Actuator和Spring Security Starter。您可以指定常用的Spring Boot属性来配置每个应用程序。
现在您可以运行时间戳应用程序,如下所示:
java -jar timestamp-task-1.3.0.RELEASE.jar --logging.level.org.springframework.cloud.task=DEBUG
使用--logging.level.org.springframework.cloud.task=DEBUG选项可以查看无法以其他方式写入控制台的输出。因为Spring Cloud Task使用内存数据库来存储其结果(并且在运行结束时内存数据库被销毁),所以DEBUG选项是查看时间戳任务输出的唯一方法。
|
时间戳应用程序显示以下输出(在其他输出中):
2018-03-12 13:45:14.583 INFO 4810 --- [ main] TimestampTaskConfiguration$TimestampTask : 2018-03-12 13:45:14.583
2018-03-12 13:45:14.609 DEBUG 4810 --- [ main] o.s.c.t.r.support.SimpleTaskRepository : Updating: TaskExecution with executionId=1 with the following {exitCode=0, endTime=Mon Mar 12 13:45:14 CDT 2018, exitMessage='null', errorMessage='null'}第一行显示Timestamp任务生成的时间戳。第二行显示退出代码为0且没有错误。如果发生错误,退出代码将不是0,errorMessage将显示抛出的异常。
如果打开了调试模式,则可以获得更多信息,如下所示(如果打开了调试模式,则会出现在时间戳之前):
2018-03-14 13:47:16.659 DEBUG 78382 --- [ main] o.s.c.t.r.support.SimpleTaskRepository : Creating: TaskExecution{executionId=0, parentExecutionId=null, exitCode=null, taskName='application', startTime=Wed Mar 14 13:47:16 EDT 2018, endTime=null, exitMessage='null', externalExecutionId='null', errorMessage='null', arguments=[]}
55.构建时间戳任务
要构建自己的时间戳任务,请遵循以下每个过程:
56.开发时间戳应用程序
现在我们已经使用了预先构建的时间戳任务应用程序,让我们创建一个自己的应用程序。
56.1.使用Spring Initializr创建Spring任务项目
现在让我们创建并测试一个将当前时间打印到控制台的应用程序。
为此:
-
访问Spring Initialzr网站。
-
创建一个新的Maven或Gradle项目,其组名为
io.spring.task.sample,工件名称为timestamp。 -
在“依赖关系”文本框中,键入
task以选择Cloud Task依赖关系。 -
在“依赖关系”文本框中,键入
jdbc,然后选择JDBC依赖关系。 -
在“依赖关系”文本框中,键入
h2,然后选择H2。(或您最喜欢的数据库) -
单击“ 生成项目”按钮
-
-
解压缩timestamp.zip文件并将项目导入您喜欢的IDE。
56.2.编写代码
要完成我们的应用程序,我们需要使用以下内容修改生成的TimestampApplication代码,以便它将启动任务。
package io.spring.task.sample.timestamp;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.task.configuration.EnableTask;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableTask
public class TimestampApplication {
@Bean
public CommandLineRunner commandLineRunner() {
return new TimestampCommandLineRunner();
}
public static void main(String[] args) {
SpringApplication.run(TimestampApplication.class, args);
}
public static class TimestampCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... strings) throws Exception {
DateFormat dateFormat = new SimpleDateFormat("YYYY-MM-dd HH:ss");
System.out.println(dateFormat.format(new Date()));
}
}
}所述@EnableTask注释设置TaskRepository存储关于任务执行的信息,如任务和退出代码的开始和结束时间。
在我们的演示中,TaskRepository使用嵌入式H2数据库来记录任务的结果。这个H2嵌入式数据库不是生产环境的实用解决方案,因为一旦任务结束,H2数据库就会消失。但是,为了快速入门体验,我们将在我们的示例中使用它,并在日志中回显该存储库中正在更新的内容。
所述CommandLineRunner是Spring Boot接口告诉引导在run方法来执行代码一次。当我们的示例应用程序运行时,Spring Boot启动我们的TimestampCommandLineRunner并将我们的时间戳消息输出到标准输出。
从CommandLineRunner或ApplicationRunner以外的机制(例如,使用InitializingBean#afterPropertiesSet)引导的任何处理都不会被Spring Cloud Task记录。
|
现在让我们打开src/main/resources中的application.properties文件并配置两个属性,即应用程序名称和日志记录。应用程序名称也用作任务的名称。日志记录级别设置为DEBUG,因此我们可以看到有关内部情况的更多信息。
logging.level.org.springframework.cloud.task=DEBUG
spring.application.name=timestamp56.3.运行示例
此时,我们的应用程序应该工作。由于此应用程序基于Spring Boot,因此我们可以从命令行使用来自应用程序根目录的./mvnw spring-boot:run运行它,如下图所示(及其输出):
$ ./mvnw clean spring-boot:run
....... . . .
....... . . . (Maven log output here)
....... . . .
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.0.3.RELEASE)
2018-07-26 12:01:47.236 INFO 93883 --- [ main] i.s.t.s.timestamp.TimestampApplication : Starting TimestampApplication on Glenns-MacBook-Pro-2.local with PID 93883 (/Users/glennrenfro/project/timestamp/target/classes started by glennrenfro in /Users/glennrenfro/project/timestamp)
2018-07-26 12:01:47.241 INFO 93883 --- [ main] i.s.t.s.timestamp.TimestampApplication : No active profile set, falling back to default profiles: default
2018-07-26 12:01:47.280 INFO 93883 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@50b87e67: startup date [Thu Jul 26 12:01:47 EDT 2018]; root of context hierarchy
2018-07-26 12:01:47.989 INFO 93883 --- [ main] o.s.j.d.e.EmbeddedDatabaseFactory : Starting embedded database: url='jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=false', username='sa'
2018-07-26 12:01:48.144 DEBUG 93883 --- [ main] o.s.c.t.c.SimpleTaskConfiguration : Using org.springframework.cloud.task.configuration.DefaultTaskConfigurer TaskConfigurer
2018-07-26 12:01:48.145 DEBUG 93883 --- [ main] o.s.c.t.c.DefaultTaskConfigurer : No EntityManager was found, using DataSourceTransactionManager
2018-07-26 12:01:48.227 DEBUG 93883 --- [ main] o.s.c.t.r.s.TaskRepositoryInitializer : Initializing task schema for h2 database
2018-07-26 12:01:48.229 INFO 93883 --- [ main] o.s.jdbc.datasource.init.ScriptUtils : Executing SQL script from class path resource [org/springframework/cloud/task/schema-h2.sql]
2018-07-26 12:01:48.261 INFO 93883 --- [ main] o.s.jdbc.datasource.init.ScriptUtils : Executed SQL script from class path resource [org/springframework/cloud/task/schema-h2.sql] in 32 ms.
2018-07-26 12:01:48.407 INFO 93883 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2018-07-26 12:01:48.412 INFO 93883 --- [ main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0
2018-07-26 12:01:48.428 DEBUG 93883 --- [ main] o.s.c.t.r.support.SimpleTaskRepository : Creating: TaskExecution{executionId=0, parentExecutionId=null, exitCode=null, taskName='timestamp', startTime=Thu Jul 26 12:01:48 EDT 2018, endTime=null, exitMessage='null', externalExecutionId='null', errorMessage='null', arguments=[]}
2018-07-26 12:01:48.439 INFO 93883 --- [ main] i.s.t.s.timestamp.TimestampApplication : Started TimestampApplication in 1.464 seconds (JVM running for 4.233)
2018-07-26 12:48
2018-07-26 12:01:48.457 DEBUG 93883 --- [ main] o.s.c.t.r.support.SimpleTaskRepository : Updating: TaskExecution with executionId=1 with the following {exitCode=0, endTime=Thu Jul 26 12:01:48 EDT 2018, exitMessage='null', errorMessage='null'}前面的输出有三条我们感兴趣的行:
-
SimpleTaskRepository记录了TaskRepository中条目的创建。 -
我们的
CommandLineRunner的执行,由时间戳输出演示。 -
SimpleTaskRepository记录TaskRepository中任务的完成情况。
56.4.录制错误
现在我们有了一个工作任务,我们可以故意创建一个错误,以显示Spring Cloud Task如何处理错误。为此:
-
打开
src/main/java/io/spring/task/sample/timestamp/TimestampApplication.java并将以下行插入run方法:throw new IllegalStateException("No Task For You!"); -
从命令行运行
./mvnw clean spring-boot:run -DskipTests。我们必须添加 -DskipTests,因为测试会捕获我们添加的Exception并阻止我们看到它。现在我们可以看到我们在输出中添加的异常,作为带有堆栈跟踪的异常。任务现在已捕获此异常并将其记录到数据库中。这可以在控制台中看到,如下所示:
Updating: TaskExecution with executionId=1 with the following {exitCode=1, endTime=Wed Jul 25 12:42:15 EDT 2018, exitMessage='null', errorMessage='java.lang.IllegalStateException: Failed to execute CommandLineRunner ... -
删除或注释掉异常,以便下一课可以正常工作。
56.5.添加预处理和后处理
Spring Cloud Task包括在任务之前和之后运行其他处理的能力。要将这两个功能添加到当前示例应用程序:
-
打开
src/main/java/io/spring/TimestampApplication.java并将以下代码添加到TimestampCommandLineRunner:@BeforeTask public void beforeTask(TaskExecution taskExecution) { System. out.println("Before TASK"); } @AfterTask public void afterTask(TaskExecution taskExecution) { System. out.println("After TASK"); } -
从命令行运行
./mvnw clean spring-boot:run。现在输出包括打印
BEFORE TASK和AFTER TASK的行。
56.6.添加MySQL数据库
几乎总是,真实世界Spring Cloud Task需要使用持久性(而不是内存中)数据库。在这个例子中,我们展示了如何将MySQL数据库(MariaDB)添加到我们的Task中。为此:
-
打开
pom.xml文件。 -
添加以下依赖项:
<dependency> <groupId>org.mariadb.jdbc</groupId> <artifactId>mariadb-java-client</artifactId> </dependency> -
例如,从命令行设置MySql的数据库连接属性
export spring_datasource_url=jdbc:mysql://localhost:3306/practice export spring_datasource_username=root export spring_datasource_password=password export spring_datasource_driverClassName=org.mariadb.jdbc.Driver -
从命令行运行
./mvnw clean spring-boot:run。如果检查数据库的内容,现在应该在
TASK_EXECUTION表中看到该任务。
57.使用数据流添加和启动Spring Cloud任务
本指南介绍了注册和启动Spring Cloud Task应用程序。它包括以下程序:
57.1.注册并启动您的第一个任务
运行Spring Cloud Data Flow Server和Shell后,可以使用以下过程创建第一个任务:
-
通过Spring Cloud Data Flow Shell使用以下命令导入注册,注册一组基本任务:
app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:1.3.0.RELEASE此示例显示如何从Maven存储库注册任务。 -
通过在Spring Cloud Data Flow Shell中运行以下命令来验证时间戳任务应用程序是否已注册:
app list应显示以下输出:

-
使用Spring Cloud Data Flow Shell中的以下命令创建使用时间戳任务的任务定义:
task create --name myStamp --definition "timestamp"您应该看到一条消息“创建新任务'myStamp'”。
-
使用以下命令启动新任务:
task launch myStamp您应该看到一条消息“启动任务`myStamp`”。
-
通过在Spring Cloud Data Flow Shell中运行以下命令来验证您的任务是否已成功运行:
task execution list您应该看到类似于以下内容的输出:

退出代码0告诉我们该任务运行没有错误。
57.2.注册并启动您的第一个Spring Batch - 任务
实质上,Batch-Task是一个包含@EnableTask注释的Spring Batch应用程序,用作Spring Batch应用程序使用Spring Cloud Task的指示符。Spring Boot照顾我们的其余部分。
注册您的第一个Spring Batch任务:
-
在Spring Cloud Data Flow Shell中,使用以下命令注册Spring Batch任务应用程序:
app register --name batch-events --type task --uri maven://org.springframework.cloud.task.app:timestamp-batch-task:2.0.0.RELEASE -
要验证您的应用程序是否已注册,请在Spring Cloud Data Flow Shell中运行以下命令:
app list您应该看到类似于以下内容的输出:
-
通过运行以下命令,创建使用批处理事件任务的任务定义:
task create --name myBatchTask --definition "batch-events"您应该看到一条消息“创建新任务'myBatchTask'”。
-
通过运行以下命令启动批处理任务:
task launch myBatchTask您应该看到一条消息“启动任务`myBatchTask`”。
-
验证任务是否已运行,运行以下命令:
task execution list您应该看到类似于以下内容的输出:
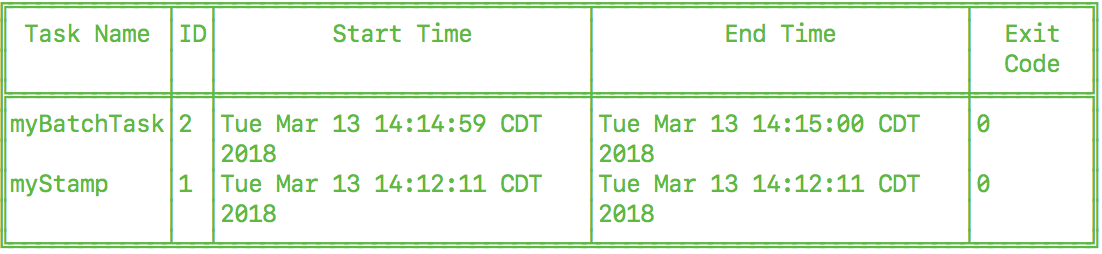
我们现在可以验证该任务是否作为批处理作业。在接下来的章节将介绍如何做到这一点。
57.2.1.验证您的任务是批处理
创建并运行Batch-Task时,它既是Spring Cloud Task实例又是Spring Batch实例。在上一节中,我们了解了如何验证您的第一个批处理任务是否作为一项任务。本节逐步介绍如何验证它是否也作为批处理工作。为此:
-
运行以下命令以查看已运行的作业列表:
job execution list您应该看到类似于以下内容的输出:
-
请注意ID列中的作业ID(在本例中,我们要查看
2)。 -
要获取作业执行的详细信息,我们可以在以下命令中使用作业ID:
job execution display --id 1您应该看到类似于以下内容的输出:
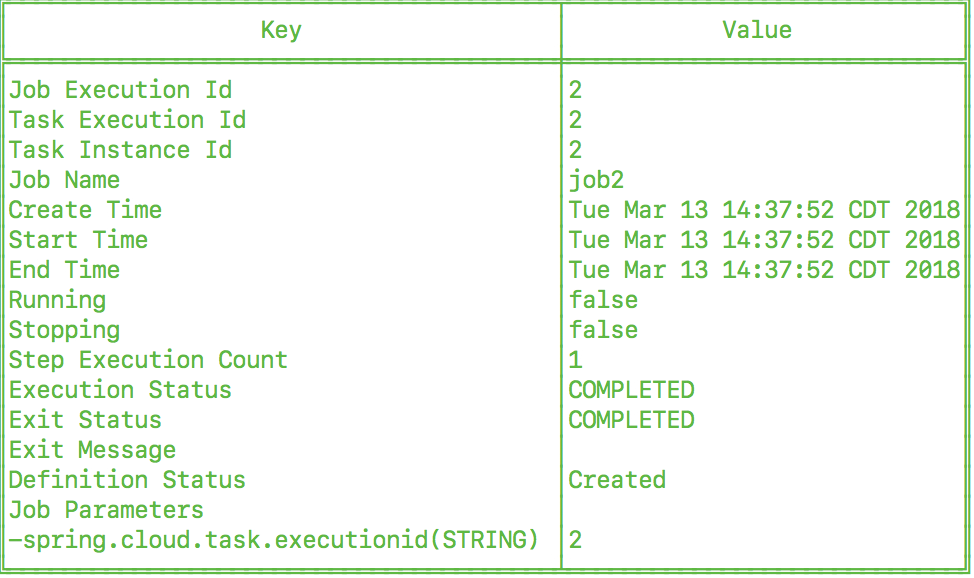
58.在Spring Cloud Data Flow中运行任务的数据库要求
如前所述,Spring Cloud Task记录了每个任务执行到关系数据库的状态。因此,当用户请求任务或批处理作业执行信息时,Spring Cloud Data Flow使用此记录的信息。此外,Spring Batch和Spring Cloud Task提供允许Spring Cloud Data Flow传达某些开始或停止行为的功能。一个示例是当用户使用Spring Cloud Data Flow UI停止Spring Batch应用程序执行时。
仪表板
本节介绍如何使用Spring Cloud Data Flow的仪表板。
59.简介
Spring Cloud Data Flow提供了一个基于浏览器的GUI,称为仪表板,用于管理以下信息:
-
应用程序:“应用程序”选项卡列出所有可用的应用程序,并提供注册/取消注册它们的控件。
-
运行时:“运行时”选项卡提供所有正在运行的应用程序的列表。
-
Streams:Streams选项卡允许您列出,设计,创建,部署和销毁流定义。
-
任务:“任务”选项卡允许您列出,创建,启动,计划和销毁任务定义。
-
作业:“作业”选项卡允许您执行批处理作业相关的功能。
-
分析:“分析”选项卡允许您为各种分析应用程序创建数据可视化。
在启动Spring Cloud Data Flow时,仪表板可在以下位置获得:
例如,如果Spring Cloud Data Flow在本地运行,则仪表板在http://localhost:9393/dashboard处可用。
如果您已启用https,则仪表板将位于https://localhost:9393/dashboard。如果您已启用安全性,则可在http://localhost:9393/dashboard/#/login处获得登录表单。
默认的仪表板服务器端口为9393。
|
下图显示了Spring Cloud Data Flow仪表板的开始页面:
60.应用程序
仪表板的“应用程序”部分列出了所有可用的应用程序,并提供了注册和取消注册它们的控件(如果适用)。可以使用批量导入应用程序操作一次导入多个应用程序。
下图显示了仪表板中可用应用程序的典型列表:
60.1.批量导入应用程序
批量导入应用程序页面提供了许多用于一次定义和导入一组应用程序的选项。对于批量导入,应用程序定义应以属性样式表示,如下所示:
<type>.<name> = <coordinates>
以下示例显示了典型的应用程序定义:
task.timestamp=maven://org.springframework.cloud.task.app:timestamp-task:1.2.0.RELEASE
processor.transform=maven://org.springframework.cloud.stream.app:transform-processor-rabbit:1.2.0.RELEASE在批量导入页面的顶部,可以指定一个指向存储在别处的属性文件的URI,它应该包含如上例所示格式化的属性。或者,通过使用标记为“Apps as Properties”的文本框,您可以直接列出每个属性字符串。最后,如果属性存储在本地文件中,则“选择Properties文件”选项将打开本地文件浏览器以选择文件。通过其中一个路径设置定义后,单击“导入”。
下图显示了批量导入应用程序页面:
61.运行时
Dashboard应用程序的Runtime部分显示所有正在运行的应用程序的列表。对于每个运行时应用程序,将显示部署状态和已部署实例的数量。单击App Id可以使用已使用的部署属性列表。
下图显示了正在使用的运行时选项卡的示例:
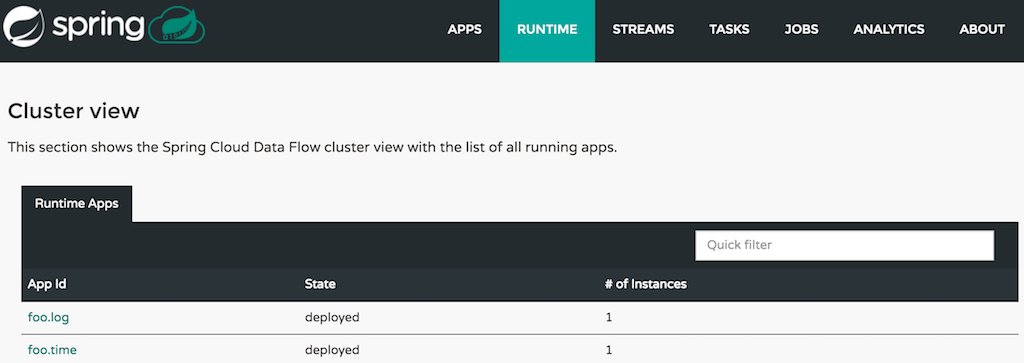
62.流
Streams选项卡有两个子选项卡:Definitions和Create Stream。以下主题描述了如何使用每个主题:
62.1.使用流定义
仪表板的Streams部分包含Definitions选项卡,该选项卡提供Stream定义列表。您可以选择部署或取消部署这些流定义。此外,您可以通过单击Destroy删除定义。每行包含左侧的箭头,您可以单击该箭头以查看定义的直观表示。将鼠标悬停在可视化表示中的框上会显示有关应用程序的更多详细信息,包括传递给它们的任何选项。
在以下屏幕截图中,timer流已展开以显示可视化表示:
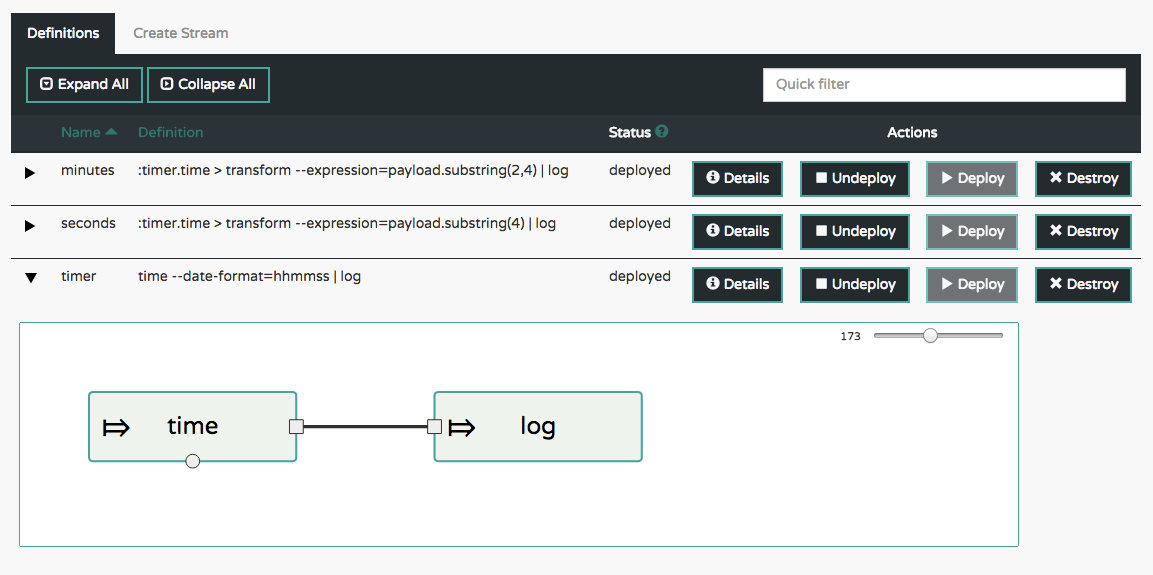
如果单击详细信息按钮,视图将更改为显示该流和任何相关流的可视化表示。在前面的示例中,如果单击timer流的详细信息,则视图将更改为以下视图,该视图清楚地显示三个流之间的关系(其中两个流正在点击timer流):
62.2.创建流
仪表板的Streams部分包括Create Stream选项卡,该选项卡使Spring Flo设计器可用:一个画布应用程序,它提供用于创建数据管道的交互式图形界面。
在此选项卡中,您可以:
-
使用DSL,图形画布或两者创建,管理和可视化流管道
-
通过DSL编写管道,内容辅助和自动完成
-
在GUI中使用自动调整和网格布局功能,以实现更简单和交互式的管道组织
下图显示了正在使用的Flo设计器:
62.3.部署流
流部署页面包括选项卡,这些选项卡提供了设置部署属性和部署流的不同方法。以下屏幕截图显示了foobar(time | log)的流部署页面。
您可以使用以下命令定义部署属性:
-
表单构建器选项卡:一个帮助您定义部署属性的构建器(部署程序,应用程序属性......)
-
自由文本选项卡:免费textarea(键/值对)
您可以在两个视图之间切换,表单构建器提供更强大的输入验证。
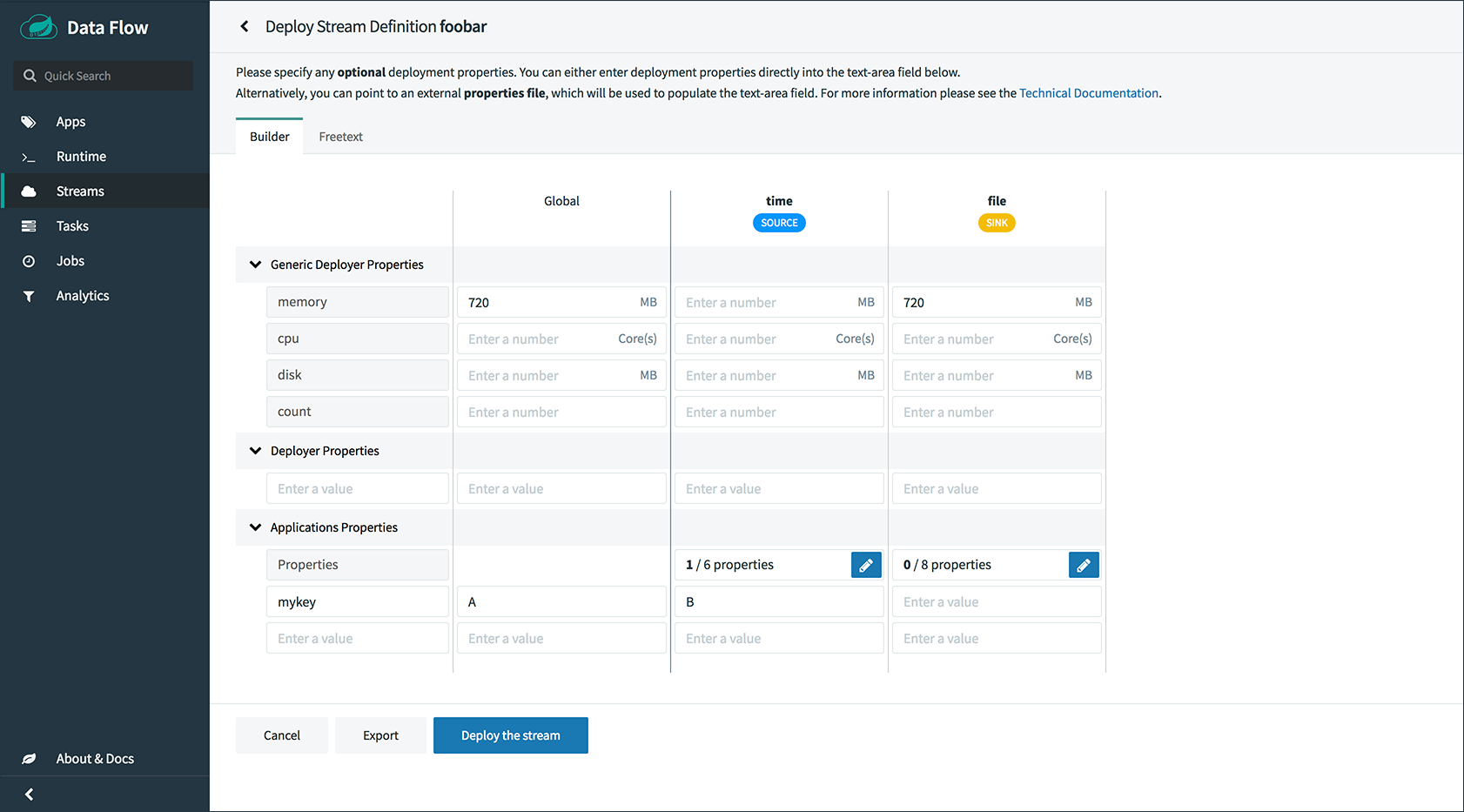
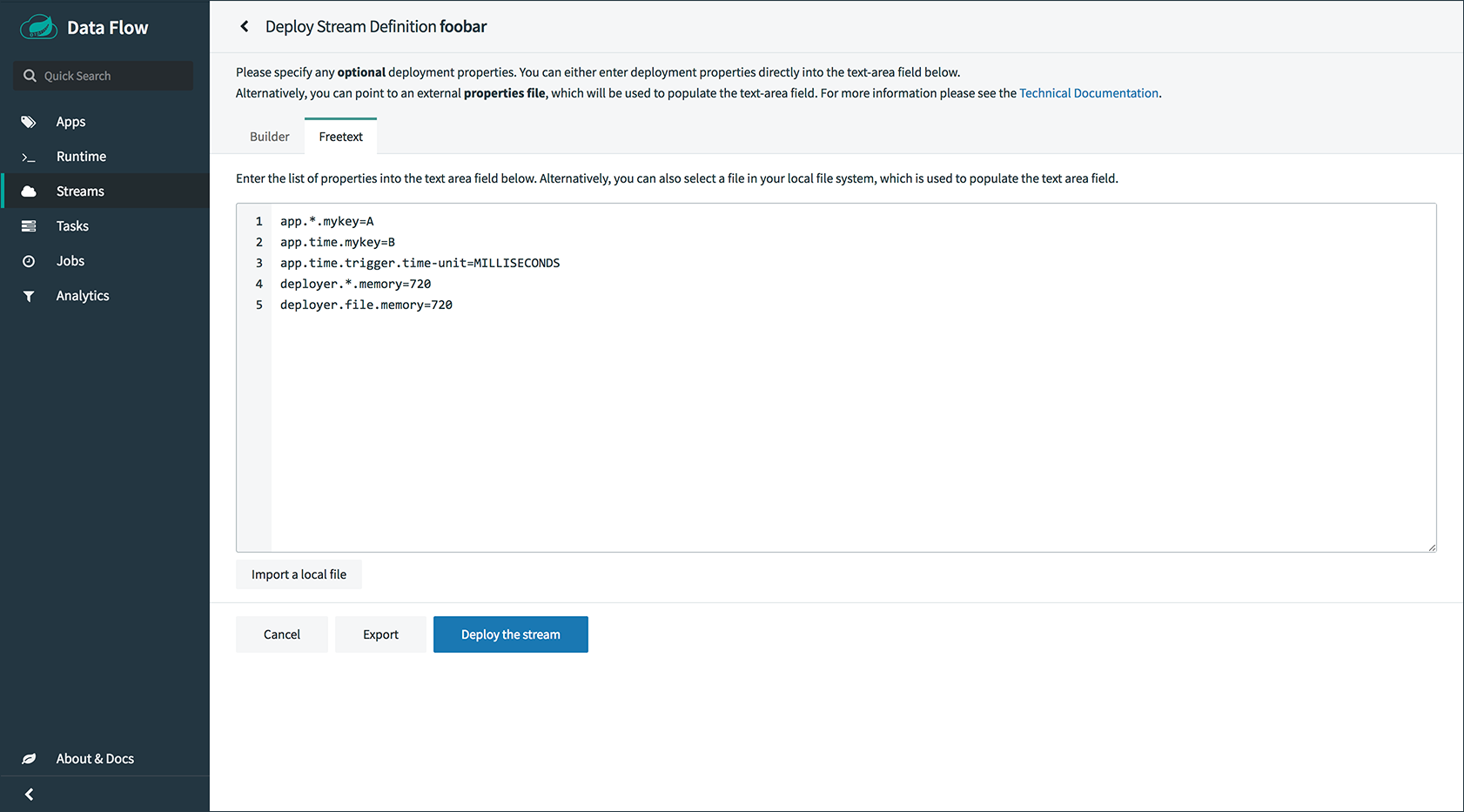
62.4.创建扇入/扇出流
在Fan-in和Fan-out章节中,您了解了我们如何使用命名目标支持扇入和扇出用例。UI还为命名目标提供专用支持:
在此示例中,我们将来自HTTP Source和JDBC Source的数据发送到sharedData通道,该 通道代表Fan-in用例。另一方面,我们有一个Cassandra Sink和一个订阅了sharedData通道的File Sink,它代表了一个扇出用例。
62.5.创建点按流
使用仪表板创建水龙头非常简单。假设您有一个由HTTP Source和File Sink组成的流,您希望利用该流来将数据发送到JDBC Sink。为了创建tap流,只需将HTTP Source的输出连接器连接到JDBC Sink。连接将显示为虚线,表示您创建了一个点按流。
如果您没有为流提供名称,将自动命名主流(HTTP Source to File Sink)。创建抽头流时,必须始终明确命名主流。在上图中,主流名为HTTP_INGEST。
使用仪表板,您还可以将主流切换为辅助点按流。
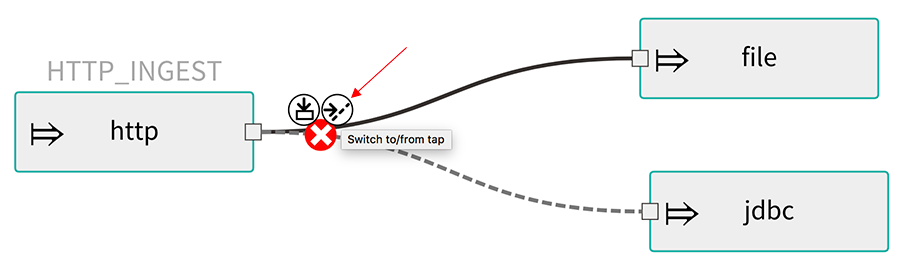
只需将鼠标悬停在现有的主流上,即HTTP Source和File Sink之间的界限。将出现几个控制图标,通过单击标记为切换到/从中点击的图标,可以将主流更改为点按流。对点击流执行相同操作并将其切换到主流。
| 当直接与命名目的地交互时,可以有“n”组合(输入/输出)。这允许您创建涉及各种数据源和目标的复杂拓扑。 |
63.任务
仪表板的“任务”部分目前有三个选项卡:
63.1.应用
每个应用程序都将一个工作单元封装到一个可重用的组件中。在数据流运行时环境中,应用程序允许用户为流和任务创建定义。因此,“任务”部分中的“应用”选项卡允许用户创建任务定义。
| 您还可以使用此选项卡创建批处理作业。 |
下图显示了典型的任务应用列表:
在此屏幕上,您可以执行以下操作:
-
查看详细信息,例如任务应用程序选项。
-
从相应的应用程序创建任务定义。
63.1.1.查看任务应用详情
在此页面上,您可以查看所选任务应用程序的详细信息,包括该应用程序的可用选项(属性)列表。
63.1.2.创建任务定义
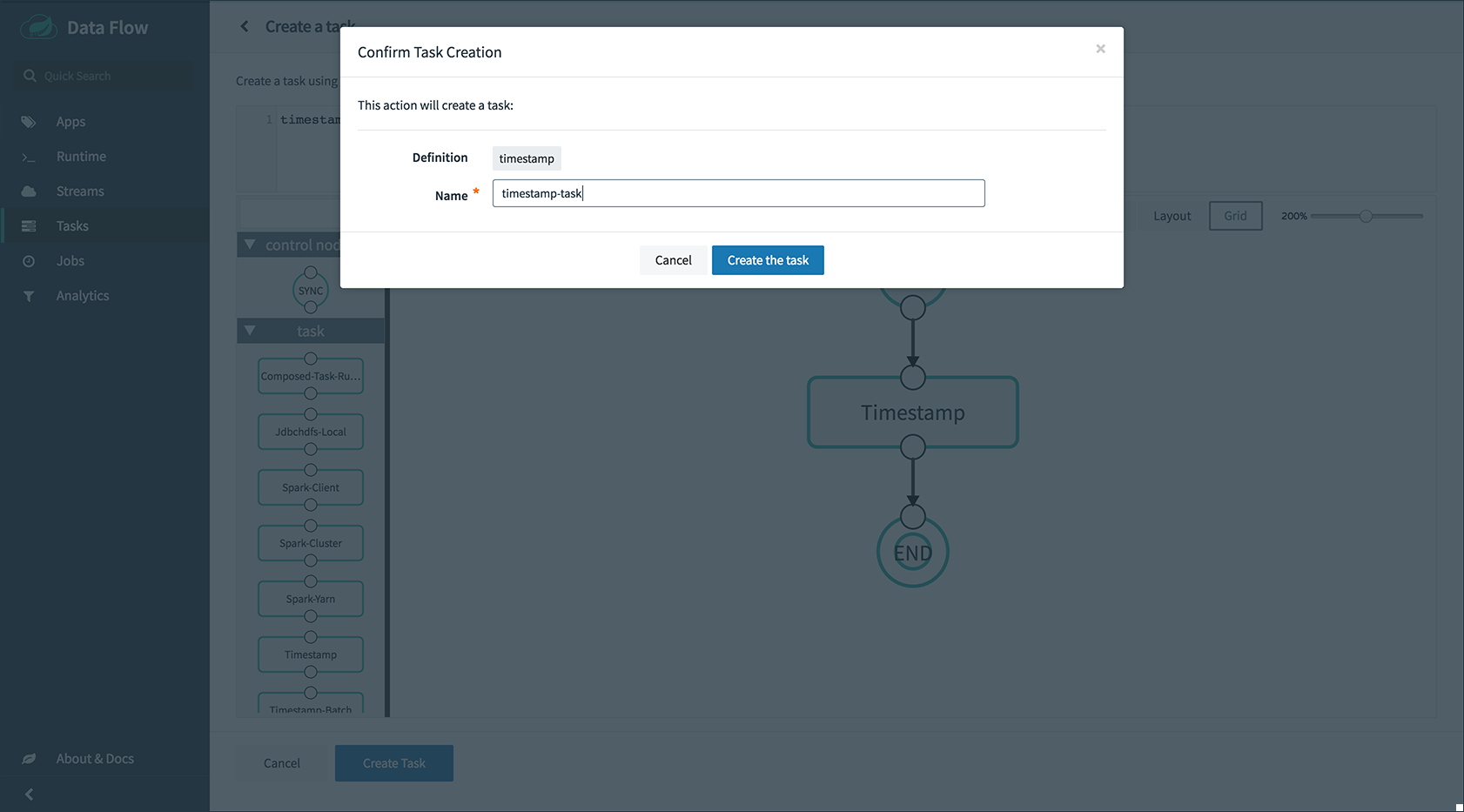
您必须至少为新定义提供名称。您还可以选择指定在部署应用程序期间使用的各种属性。
| 仅当选中“包含”复选框时,才会包含每个参数。 |
63.2.定义
此页面列出了数据流任务定义,并提供了启动或销毁这些任务的操作。它还提供了一个快捷操作,用于通过简单文本输入定义一个或多个任务,由批量定义任务按钮指示。
下图显示了“定义”页面:
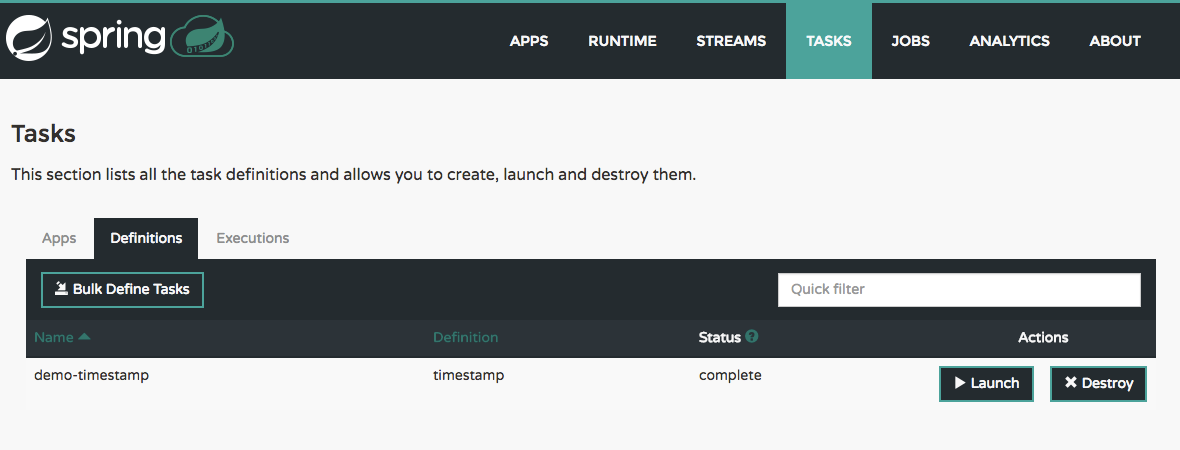
63.2.1.创建组合任务定义
仪表板包括“创建组合任务”选项卡,该选项卡提供用于创建组合任务的交互式图形界面。
在此选项卡中,您可以:
-
使用DSL,图形画布或两者创建和可视化组合任务。
-
使用GUI中的自动调整和网格布局功能,可以更轻松地组织任务组织。
在“创建组合任务”屏幕上,您可以通过输入参数键和参数值来定义一个或多个任务参数。
| 未键入任务参数。 |
下图显示了组合任务设计器:
63.2.2.启动任务
创建任务定义后,可以通过仪表板启动任务。为此,请单击“定义”选项卡,然后按Launch选择要启动的任务。
63.3.处决
Executions选项卡显示当前正在运行和已完成的任务。
下图显示了Executions选项卡:
63.4.执行细节
对于Executions页面上的每个任务执行,用户可以通过单击位于任务执行右侧的信息图标来检索有关特定执行的详细信息。
在此屏幕上,用户不仅可以查看“任务执行”页面中的信息,还可以查看:
-
任务参数
-
外部执行ID
-
批处理作业指示符(指示任务执行是否包含Spring Batch个作业。)
-
作业执行ID链接(单击作业执行ID将转到该作业执行ID的作业执行详细信息。)
-
任务执行持续时间
-
任务执行退出消息
64.工作
仪表板的“作业”部分允许您检查批处理作业。屏幕的主要部分提供了作业执行列表。批处理作业是每个执行一个或多个批处理作业的任务。每个作业执行都有对任务执行ID的引用(在Task Id列中)。
作业执行列表还显示基础作业定义的状态。因此,如果已删除基础定义,则“状态”列中将显示“未找到定义”。
您可以为每个作业采取以下操作:
-
重启(适用于失败的作业)。
-
停止(用于运行作业)。
-
查看执行细节。
注意:单击停止按钮实际上会向正在运行的作业发送停止请求,该请求可能不会立即停止。
下图显示了Jobs页面:
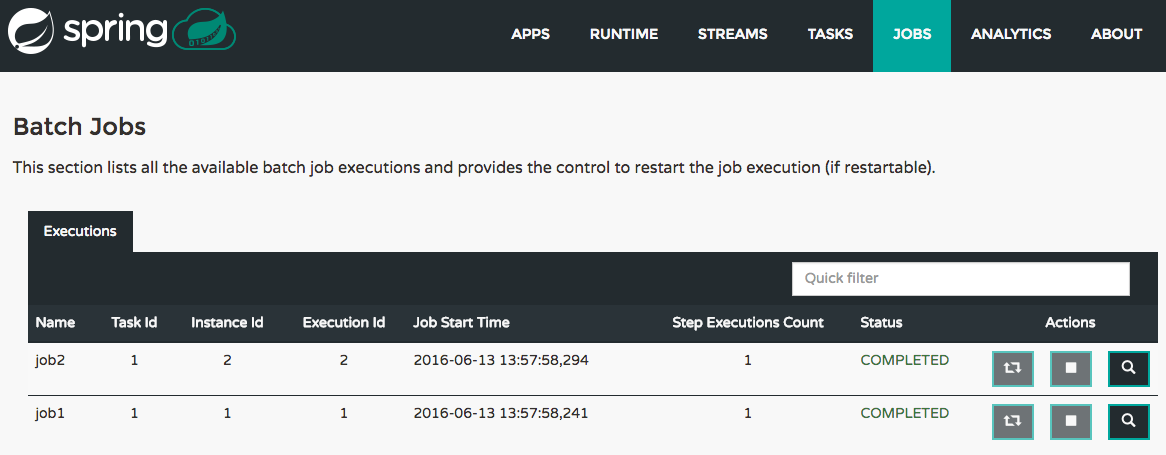
64.1.工作执行细节
启动批处理作业后,“作业执行详细信息”页面将显示有关该作业的信息。
下图显示了“作业执行详细信息”页面:
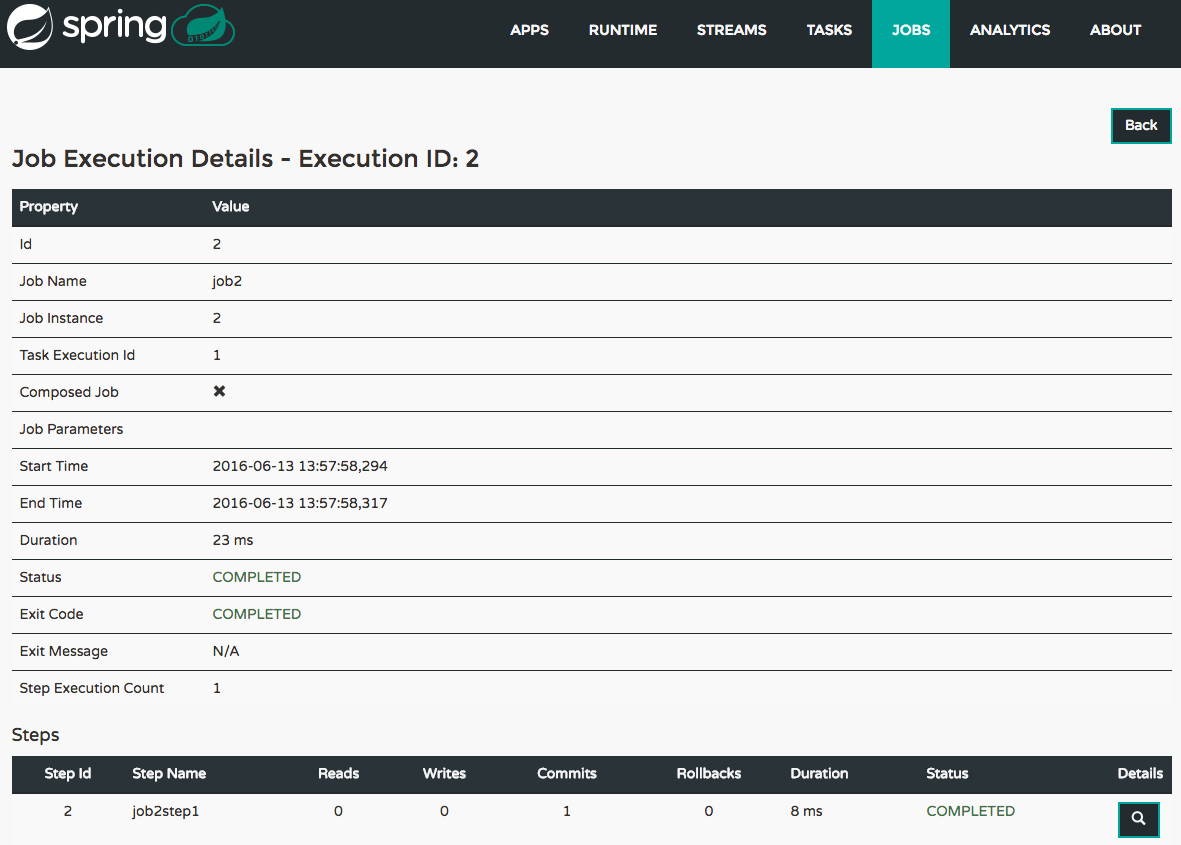
“作业执行详细信息”页面包含已执行步骤的列表。您可以通过单击放大镜图标进一步深入了解每个步骤的执行细节。
64.2.步骤执行细节
“步骤执行详细信息”页面提供有关作业中单个步骤的信息。
下图显示了“步骤执行详细信息”页面:
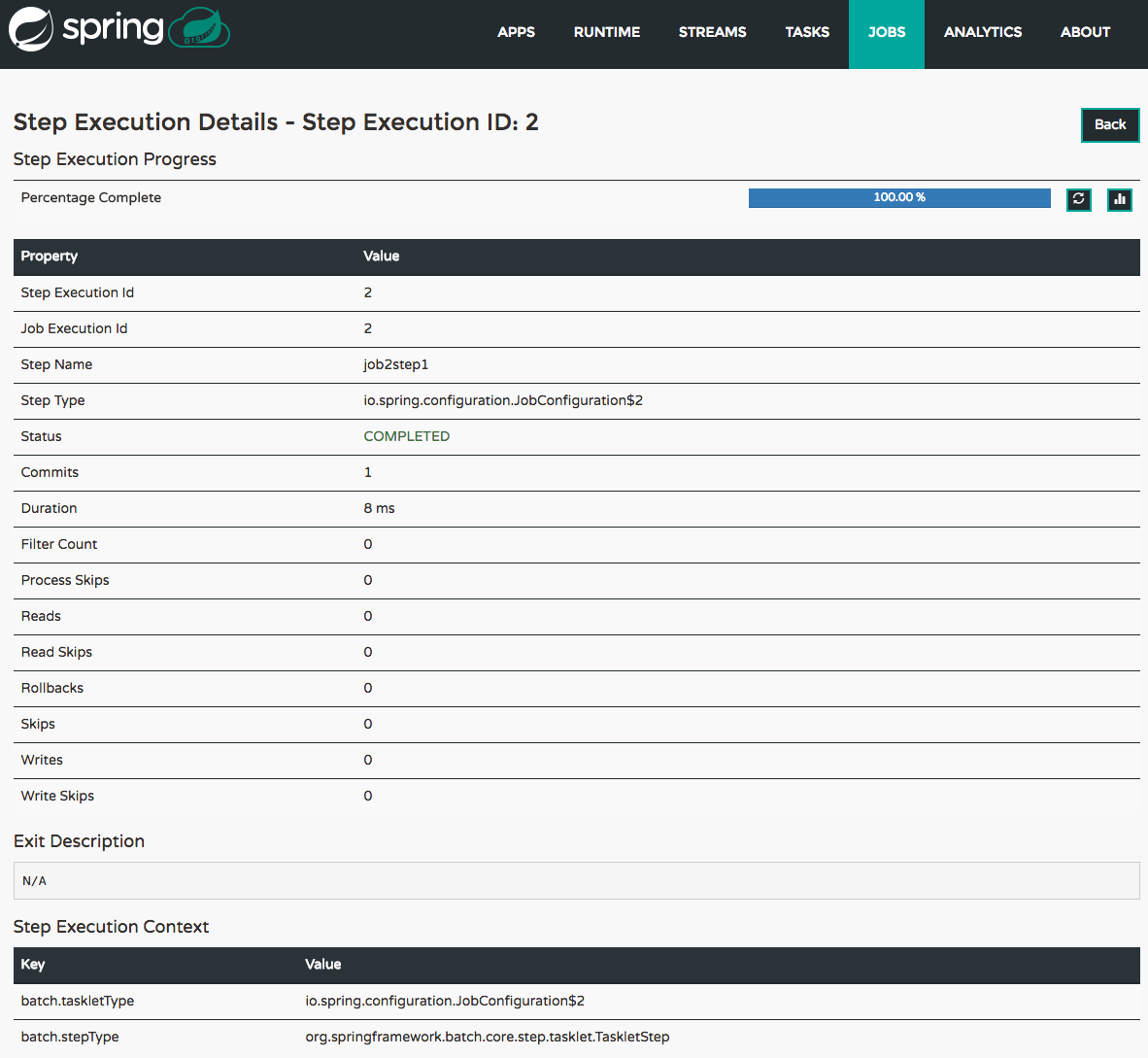
在页面顶部,您可以看到相应步骤的进度指示器,并可选择刷新指示器。提供链接以查看步骤执行历史。
“步骤执行详细信息”屏幕提供所有步骤执行上下文键/值对的完整列表。
| 对于例外,“退出描述”字段包含其他错误信息。但是,此字段最多可包含2500个字符。因此,在长异常堆栈跟踪的情况下,可能会发生错误消息的修整。发生这种情况时,请参阅服务器日志文件以获取更多详细信息。 |
64.3.步骤执行进度
在此屏幕上,您可以看到有关当前步骤执行的进度条指示器。在“步骤执行历史记录”下,您还可以查看与所选步骤关联的各种度量标准,例如持续时间,读取计数,写入计数等。
65.安排
65.1.从“任务定义”页面创建或删除计划
在“任务定义”页面中,用户可以创建或删除特定任务定义的计划。
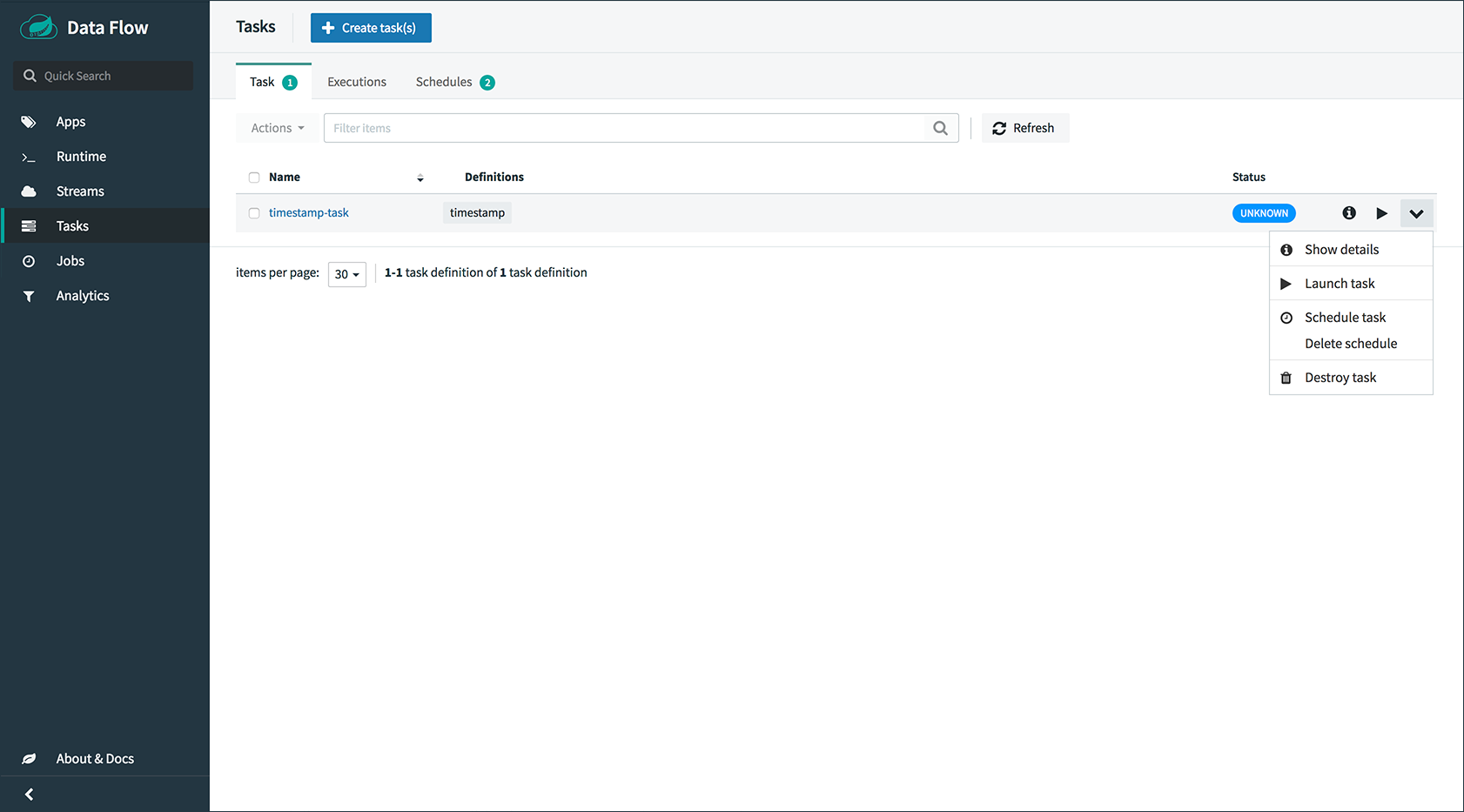
在此屏幕上,您可以执行以下操作:
-
用户可以单击时钟图标,这将带您进入“计划创建”屏幕。
-
用户可以单击右上方带有
x的时钟图标来删除与任务定义关联的计划。
65.2.创建计划
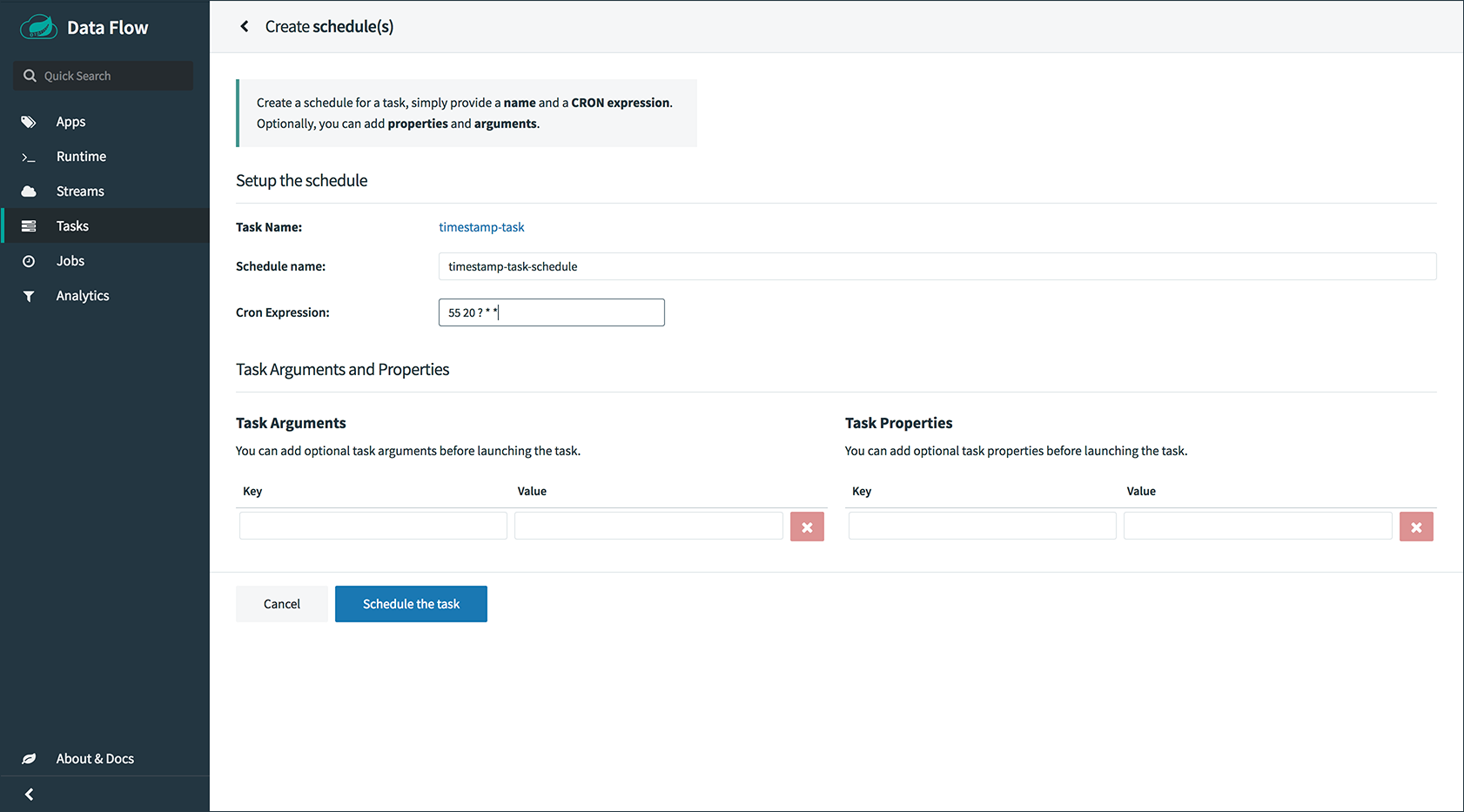
用户单击“任务定义”屏幕上的时钟图标后,Spring Cloud Data Flow将使用户进入“计划创建”屏幕。在此屏幕上,用户可以建立计划名称,cron表达式以及建立在此计划启动任务时要使用的属性和参数。
65.3.列出可用的计划
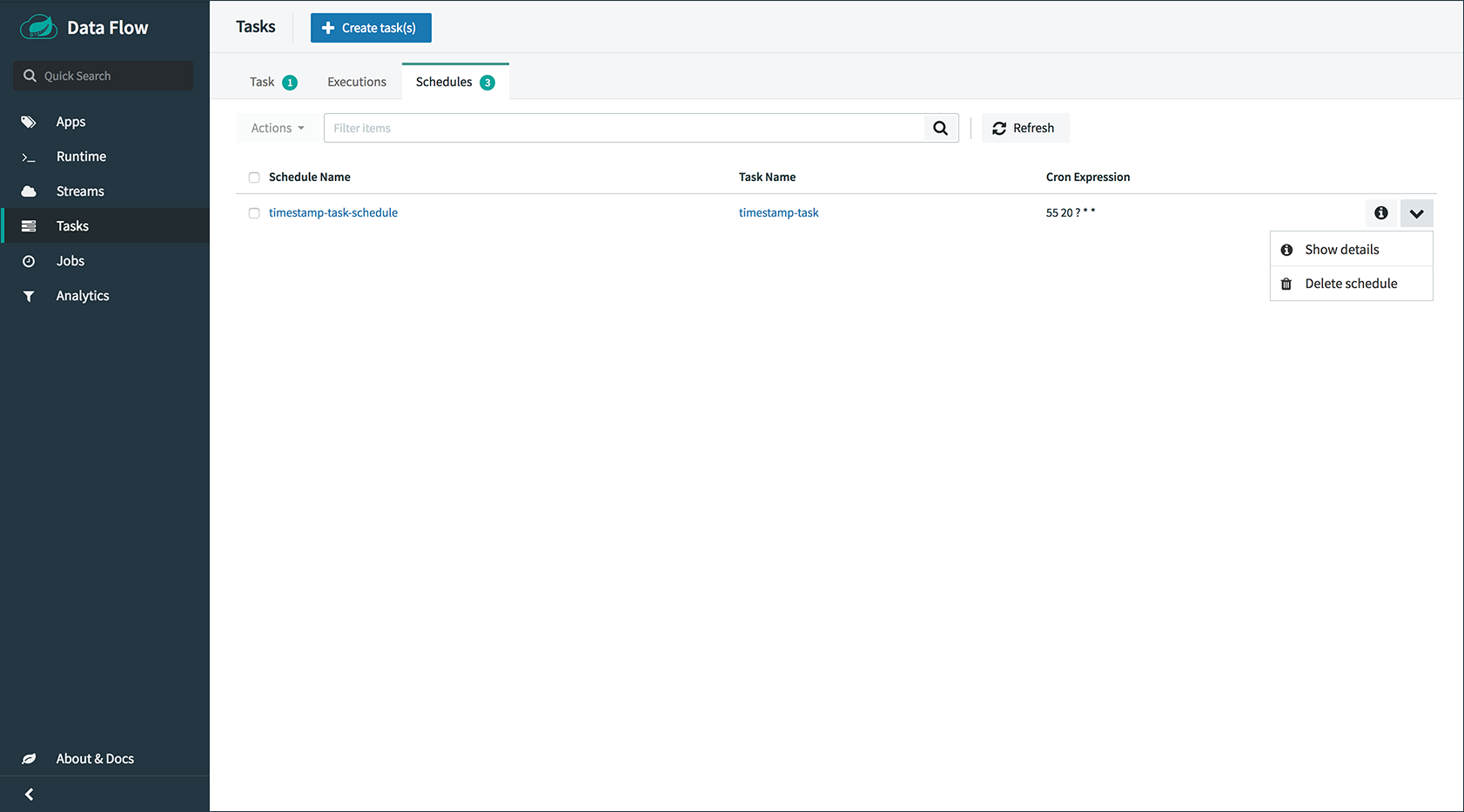
在此屏幕上,您可以执行以下操作:
-
删除计划
-
获取时间表的详细信息
66.分析
仪表板的“分析”页面为Spring Cloud Data Flow中提供的各种分析应用程序提供了以下数据可视化功能:
-
计数器
-
场值计数器
-
总计数器
例如,如果使用“ 计数器”应用程序创建流,则可以从“仪表板”选项卡中创建相应的图形。为此:
-
在
Metric Type下,从选择框中选择Counters。 -
在
Stream下,选择tweetcount。 -
在
Visualization下,选择所需的图表选项Bar Chart。
使用右侧的图标,您可以向仪表板添加其他图表,重新排列已创建仪表板的顺序或删除数据可视化。
67.审计
仪表板的“审核”页面使您可以访问记录的审核事件。目前的审计事件记录为:
-
流
-
创建
-
删除
-
部署
-
取消部署
-
-
任务
-
创建
-
删除
-
发射
-
-
任务调度
-
创建计划
-
删除计划
-
通过单击“ 显示详细信息”图标,您可以获得有关审核详细信息的更多详细信息:
通常,审计提供以下信息:
-
创建记录的时间是?
-
触发审核事件的用户名(如果启用了安全性)
-
审计操作(时间表,Stresm,任务)
-
执行的操作(创建,删除,部署,回滚,取消部署,更新)
-
相关ID,例如流/任务名称
-
审计数据
审计数据属性的书面值取决于执行的审计操作和ActionType。例如,在创建计划时,任务定义的名称,任务定义属性,部署属性以及命令行参数将写入持久性存储。
在以尽力服务的方式保存审计记录之前,对敏感信息进行清理。正在检测以下任何键并且其敏感值被屏蔽:
-
密码
-
秘密
-
键
-
代币
-
。*证书。*
-
VCAP_SERVICES
样品
本节显示可用的样本。
68.链接
REST API指南
本节介绍Spring Cloud Data Flow REST API。
69.概述
Spring Cloud Data Flow提供了一个REST API,允许您访问服务器的所有方面。事实上,Spring Cloud Data Flow shell是该API的一流消费者。
如果计划将REST API与Java一起使用,则应考虑使用提供的内部使用REST API的Java客户端(DataflowTemplate)。
|
69.1.HTTP动词
Spring Cloud Data Flow尝试在使用HTTP谓词时尽可能地遵守标准HTTP和REST约定,如下表所述:
| 动词 | 用法 |
|---|---|
|
Used to retrieve a resource |
|
Used to create a new resource |
|
Used to update an existing resource, including partial updates. Also used for
resources that imply the concept of |
|
Used to delete an existing resource. |
69.2.HTTP状态代码
Spring Cloud Data Flow尝试在使用HTTP状态代码时尽可能地遵守标准HTTP和REST约定,如下表所示:
| 状态代码 | 用法 |
|---|---|
|
The request completed successfully. |
|
A new resource has been created successfully. The resource’s URI is available from the response’s |
|
An update to an existing resource has been applied successfully. |
|
The request was malformed. The response body includes an error description that provides further information. |
|
The requested resource did not exist. |
|
The requested resource already exists. For example, the task already exists or the stream was already being deployed |
|
Returned in cases where the Job Execution cannot be stopped or restarted. |
69.3.头
每个响应都有以下标题:
| 名称 | 描述 |
|---|---|
|
有效负载的Content-Type,例如 |
69.4.错误
| 路径 | 类型 | 描述 |
|---|---|---|
|
|
发生的HTTP错误,例如 |
|
|
错误原因的描述 |
|
|
请求的路径 |
|
|
HTTP状态代码,例如 |
|
|
发生错误的时间(以毫秒为单位) |
69.5.超媒体
Spring Cloud Data Flow使用超媒体,资源包括其响应中其他资源的链接。响应在超文本应用程序中,从资源到资源语言(HAL)格式。链接可以在_links键下找到。API的用户不应自己创建URI。代替。他们应该使用上述链接进行导航。
70.资源
API包括以下资源:
70.1.指数
索引提供了进入Spring Cloud Data Flow的REST API的入口点。以下主题提供了更多详细信息:
70.1.1.访问索引
使用GET请求访问索引。
请求结构
GET / HTTP/1.1
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/' -i响应结构
| 路径 | 类型 | 描述 |
|---|---|---|
|
|
与其他资源的链接 |
|
|
每次在此REST API中实施更改时都会增加 |
示例响应
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 4669
{
"_links" : {
"dashboard" : {
"href" : "http://localhost:9393/dashboard"
},
"audit-records" : {
"href" : "http://localhost:9393/audit-records"
},
"streams/definitions" : {
"href" : "http://localhost:9393/streams/definitions"
},
"streams/definitions/definition" : {
"href" : "http://localhost:9393/streams/definitions/{name}",
"templated" : true
},
"streams/validation" : {
"href" : "http://localhost:9393/streams/validation/{name}",
"templated" : true
},
"runtime/apps" : {
"href" : "http://localhost:9393/runtime/apps"
},
"runtime/apps/app" : {
"href" : "http://localhost:9393/runtime/apps/{appId}",
"templated" : true
},
"runtime/apps/instances" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances",
"templated" : true
},
"metrics/streams" : {
"href" : "http://localhost:9393/metrics/streams"
},
"streams/deployments" : {
"href" : "http://localhost:9393/streams/deployments"
},
"streams/deployments/deployment" : {
"href" : "http://localhost:9393/streams/deployments/{name}",
"templated" : true
},
"tasks/definitions" : {
"href" : "http://localhost:9393/tasks/definitions"
},
"tasks/definitions/definition" : {
"href" : "http://localhost:9393/tasks/definitions/{name}",
"templated" : true
},
"tasks/executions" : {
"href" : "http://localhost:9393/tasks/executions"
},
"tasks/executions/name" : {
"href" : "http://localhost:9393/tasks/executions{?name}",
"templated" : true
},
"tasks/executions/current" : {
"href" : "http://localhost:9393/tasks/executions/current"
},
"tasks/executions/execution" : {
"href" : "http://localhost:9393/tasks/executions/{id}",
"templated" : true
},
"tasks/validation" : {
"href" : "http://localhost:9393/tasks/validation/{name}",
"templated" : true
},
"tasks/schedules" : {
"href" : "http://localhost:9393/tasks/schedules"
},
"tasks/schedules/instances" : {
"href" : "http://localhost:9393/tasks/schedules/instances/{taskDefinitionName}",
"templated" : true
},
"jobs/executions" : {
"href" : "http://localhost:9393/jobs/executions"
},
"jobs/executions/name" : {
"href" : "http://localhost:9393/jobs/executions{?name}",
"templated" : true
},
"jobs/executions/execution" : {
"href" : "http://localhost:9393/jobs/executions/{id}",
"templated" : true
},
"jobs/executions/execution/steps" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps",
"templated" : true
},
"jobs/executions/execution/steps/step" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}",
"templated" : true
},
"jobs/executions/execution/steps/step/progress" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}/progress",
"templated" : true
},
"jobs/instances/name" : {
"href" : "http://localhost:9393/jobs/instances{?name}",
"templated" : true
},
"jobs/instances/instance" : {
"href" : "http://localhost:9393/jobs/instances/{id}",
"templated" : true
},
"tools/parseTaskTextToGraph" : {
"href" : "http://localhost:9393/tools"
},
"tools/convertTaskGraphToText" : {
"href" : "http://localhost:9393/tools"
},
"counters" : {
"href" : "http://localhost:9393/metrics/counters"
},
"counters/counter" : {
"href" : "http://localhost:9393/metrics/counters/{name}",
"templated" : true
},
"field-value-counters" : {
"href" : "http://localhost:9393/metrics/field-value-counters"
},
"field-value-counters/counter" : {
"href" : "http://localhost:9393/metrics/field-value-counters/{name}",
"templated" : true
},
"aggregate-counters" : {
"href" : "http://localhost:9393/metrics/aggregate-counters"
},
"aggregate-counters/counter" : {
"href" : "http://localhost:9393/metrics/aggregate-counters/{name}",
"templated" : true
},
"apps" : {
"href" : "http://localhost:9393/apps"
},
"about" : {
"href" : "http://localhost:9393/about"
},
"completions/stream" : {
"href" : "http://localhost:9393/completions/stream{?start,detailLevel}",
"templated" : true
},
"completions/task" : {
"href" : "http://localhost:9393/completions/task{?start,detailLevel}",
"templated" : true
}
},
"api.revision" : 14
}链接
索引的主要元素是链接,因为它们允许您遍历API并执行所需的功能:
| 关系 | 描述 |
|---|---|
|
访问元信息,包括启用的功能,安全信息,版本信息 |
|
访问仪表板UI |
|
提供审计跟踪信息 |
|
处理已注册的申请 |
|
公开Stream的DSL完成功能 |
|
公开任务的DSL完成功能 |
|
公开流应用程序的指标 |
|
提供JobExecution资源 |
|
提供特定JobExecution的详细信息 |
|
提供JobExecution的步骤 |
|
返回特定步骤的详细信息 |
|
提供特定步骤的进度信息 |
|
按作业名称检索作业执行 |
|
为特定作业实例提供作业实例资源 |
|
为特定作业名称提供作业实例资源 |
|
提供运行时应用程序资源 |
|
公开特定应用程序的运行时状态 |
|
提供应用程序实例的状态 |
|
提供任务定义资源 |
|
提供特定任务定义的详细信息 |
|
提供任务定义的验证 |
|
返回任务执行并允许启动任务 |
|
提供当前运行任务的计数 |
|
提供任务的计划信息 |
|
提供特定任务的计划信息 |
|
返回给定任务名称的所有任务执行 |
|
提供特定任务执行的详细信息 |
|
公开Streams资源 |
|
处理特定的流定义 |
|
提供流定义的验证 |
|
提供Stream部署操作 |
|
请求(取消)部署现有流定义 |
|
公开处理计数器的资源 |
|
处理特定的柜台 |
|
提供处理聚合计数器的资源 |
|
处理特定的聚合计数器 |
|
提供处理字段值计数器的资源 |
|
处理特定的字段值计数器 |
|
将任务定义解析为图结构 |
|
将图形格式转换为DSL文本格式 |
70.2.服务器元信息
服务器元信息端点提供有关服务器本身的更多信息。以下主题提供了更多详细信息:
70.2.1.检索有关服务器的信息
GET请求返回Spring Cloud Data Flow的元信息,包括:
-
运行时环境信息
-
有关启用哪些功能的信息
-
Spring Cloud Data Flow服务器的依赖信息
-
安全信息
请求结构
GET /about HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/about' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2167
{
"featureInfo" : {
"analyticsEnabled" : true,
"streamsEnabled" : true,
"tasksEnabled" : true,
"skipperEnabled" : false,
"schedulerEnabled" : true
},
"versionInfo" : {
"implementation" : {
"name" : "spring-cloud-starter-dataflow-server-local",
"version" : "1.7.3.RELEASE"
},
"core" : {
"name" : "Spring Cloud Data Flow Core",
"version" : "1.7.3.RELEASE"
},
"dashboard" : {
"name" : "Spring Cloud Dataflow UI",
"version" : "1.7.2.RELEASE"
},
"shell" : {
"name" : "Spring Cloud Data Flow Shell",
"version" : "1.7.3.RELEASE",
"url" : "https://repo.spring.io/libs-release/org/springframework/cloud/spring-cloud-dataflow-shell/1.7.3.RELEASE/spring-cloud-dataflow-shell-1.7.3.RELEASE.jar"
}
},
"securityInfo" : {
"authenticationEnabled" : false,
"authorizationEnabled" : false,
"formLogin" : false,
"authenticated" : false,
"username" : null,
"roles" : [ ]
},
"runtimeEnvironment" : {
"appDeployer" : {
"deployerImplementationVersion" : "1.3.10.RELEASE",
"deployerName" : "LocalAppDeployer",
"deployerSpiVersion" : "1.3.4.RELEASE",
"javaVersion" : "1.8.0_144",
"platformApiVersion" : "Linux 4.4.0-139-generic",
"platformClientVersion" : "4.4.0-139-generic",
"platformHostVersion" : "4.4.0-139-generic",
"platformSpecificInfo" : { },
"platformType" : "Local",
"springBootVersion" : "1.5.16.RELEASE",
"springVersion" : "4.3.19.RELEASE"
},
"taskLauncher" : {
"deployerImplementationVersion" : "1.3.10.RELEASE",
"deployerName" : "LocalTaskLauncher",
"deployerSpiVersion" : "1.3.4.RELEASE",
"javaVersion" : "1.8.0_144",
"platformApiVersion" : "Linux 4.4.0-139-generic",
"platformClientVersion" : "4.4.0-139-generic",
"platformHostVersion" : "4.4.0-139-generic",
"platformSpecificInfo" : { },
"platformType" : "Local",
"springBootVersion" : "1.5.16.RELEASE",
"springVersion" : "4.3.19.RELEASE"
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/about"
}
}
}70.3.注册申请
已注册的应用程序端点提供有关在Spring Cloud Data Flow服务器中注册的应用程序的信息。以下主题提供了更多详细信息:
-
使用版本注册新应用程序(在Skipper模式下)
-
设置默认应用程序版本(在Skipper模式下)
70.3.1.上市申请
GET请求将列出Spring Cloud Data Flow已知的所有应用程序。以下主题提供了更多详细信息:
请求结构
GET /apps?type=source HTTP/1.1
Accept: application/json
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
将返回的应用限制为应用类型。[app,source,processor,sink,task]之一 |
示例请求
$ curl 'http://localhost:9393/apps?type=source' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 911
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : null,
"defaultVersion" : false,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http"
}
}
}, {
"name" : "time",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE",
"version" : null,
"defaultVersion" : false,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/time"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.3.2.获取特定应用的信息
/apps/<type>/<name>上的GET请求获取特定应用程序的信息。以下主题提供了更多详细信息:
请求结构
GET /apps/source/http?exhaustive=false HTTP/1.1
Accept: application/json
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
返回所有应用程序属性,包括常见的Spring Boot属性 |
路径参数
| 参数 | 描述 |
|---|---|
|
要查询的应用程序类型。[app,source,processor,sink,task]之一 |
|
要查询的应用程序的名称 |
示例请求
$ curl 'http://localhost:9393/apps/source/http?exhaustive=false' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2436
{
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : null,
"defaultVersion" : false,
"options" : [ {
"id" : "http.path-pattern",
"name" : "path-pattern",
"type" : "java.lang.String",
"description" : "An Ant-Style pattern to determine which http requests will be captured.",
"shortDescription" : "An Ant-Style pattern to determine which http requests will be captured.",
"defaultValue" : "/",
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"sourceType" : "org.springframework.cloud.stream.app.http.source.HttpSourceProperties",
"sourceMethod" : null,
"deprecated" : false
}, {
"id" : "http.mapped-request-headers",
"name" : "mapped-request-headers",
"type" : "java.lang.String[]",
"description" : "Headers that will be mapped.",
"shortDescription" : "Headers that will be mapped.",
"defaultValue" : null,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"sourceType" : "org.springframework.cloud.stream.app.http.source.HttpSourceProperties",
"sourceMethod" : null,
"deprecated" : false
}, {
"id" : "http.secured",
"name" : "secured",
"type" : "java.lang.Boolean",
"description" : "Secure or not HTTP source path.",
"shortDescription" : "Secure or not HTTP source path.",
"defaultValue" : false,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"sourceType" : "org.springframework.cloud.stream.app.http.source.HttpSourceProperties",
"sourceMethod" : null,
"deprecated" : false
}, {
"id" : "server.port",
"name" : "port",
"type" : "java.lang.Integer",
"description" : "Server HTTP port.",
"shortDescription" : "Server HTTP port.",
"defaultValue" : null,
"hints" : {
"keyHints" : [ ],
"keyProviders" : [ ],
"valueHints" : [ ],
"valueProviders" : [ ]
},
"deprecation" : null,
"sourceType" : "org.springframework.boot.autoconfigure.web.ServerProperties",
"sourceMethod" : null,
"deprecated" : false
} ],
"shortDescription" : null
}70.3.3.注册新的应用程序
/apps/<type>/<name>上的POST请求允许注册新的申请。以下主题提供了更多详细信息:
请求结构
POST /apps/source/http HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE请求参数
| 参数 | 描述 |
|---|---|
|
应用程序位所在的URI |
|
可以找到应用程序元数据jar的URI |
|
如果已存在具有相同名称和类型的注册,则必须为true,否则将发生错误 |
路径参数
| 参数 | 描述 |
|---|---|
|
要注册的应用程序类型。[app,source,processor,sink,task]之一 |
|
要注册的应用程序的名称 |
示例请求
$ curl 'http://localhost:9393/apps/source/http' -i -X POST -d 'uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE'响应结构
HTTP/1.1 201 Created70.3.4.使用版本注册新应用程序
| 要使用此功能,数据流服务器必须处于Skipper模式 |
/apps/<type>/<name>/<version>上的POST请求允许在Skipper模式下注册新应用程序。以下主题提供了更多详细信息:
请求结构
POST /apps/source/http/1.1.0.RELEASE HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE请求参数
| 参数 | 描述 |
|---|---|
|
应用程序位所在的URI |
|
可以找到应用程序元数据jar的URI |
|
如果已存在具有相同名称和类型的注册,则必须为true,否则将发生错误 |
路径参数
| 参数 | 描述 |
|---|---|
|
要注册的应用程序类型。[app,source,processor,sink,task]之一 |
|
要注册的应用程序的名称 |
|
要注册的应用程序的版本 |
示例请求
$ curl 'http://localhost:9393/apps/source/http/1.1.0.RELEASE' -i -X POST -d 'uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE'响应结构
HTTP/1.1 201 Created70.3.5.设置默认应用程序版本
| 要使用此功能,数据流服务器必须处于Skipper模式 |
对于具有name和type的应用程序,可以在Skipper模式下注册多个版本。在这种情况下,可以选择其中一个版本作为默认应用程序。
以下主题提供了更多详细信息:
请求结构
PUT /apps/source/http/1.2.0.RELEASE HTTP/1.1
Accept: application/json
Host: localhost:9393路径参数
| 参数 | 描述 |
|---|---|
|
应用程序的类型。[app,source,processor,sink,task]之一 |
|
应用程序的名称 |
|
应用程序的版本 |
示例请求
$ curl 'http://localhost:9393/apps/source/http/1.2.0.RELEASE' -i -X PUT -H 'Accept: application/json'响应结构
HTTP/1.1 202 Accepted70.3.6.取消注册应用程序
/apps/<type>/<name>上的DELETE请求取消注册以前注册的申请。以下主题提供了更多详细信息:
请求结构
DELETE /apps/source/http HTTP/1.1
Host: localhost:9393路径参数
| 参数 | 描述 |
|---|---|
|
要取消注册的应用程序类型。[app,source,processor,sink,task]之一 |
|
要取消注册的应用程序的名称 |
示例请求
$ curl 'http://localhost:9393/apps/source/http' -i -X DELETE响应结构
HTTP/1.1 200 OK70.3.7.批量注册应用程序
/apps上的POST请求允许一次注册多个应用程序。以下主题提供了更多详细信息:
请求结构
POST /apps HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=false请求参数
| 参数 | 描述 |
|---|---|
|
可以获取包含注册的属性文件的URI。仅限 |
|
内联注册。仅限 |
|
如果已存在具有相同名称和类型的注册,则必须为true,否则将发生错误 |
示例请求
$ curl 'http://localhost:9393/apps' -i -X POST -d 'apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=false'响应结构
HTTP/1.1 201 Created
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 587
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.1.0.RELEASE",
"version" : null,
"defaultVersion" : false,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.4.审计记录
70.4.1.列出所有审核记录
审计记录端点允许您检索审计跟踪信息。
以下主题提供了更多详细信息:
请求结构
GET /audit-records?page=0&size=10&operations=STREAM&actions=CREATE HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
逗号分隔的审计操作列表(可选) |
|
逗号分隔的审计操作列表(可选) |
示例请求
$ curl 'http://localhost:9393/audit-records?page=0&size=10&operations=STREAM&actions=CREATE' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 651
{
"_embedded" : {
"auditRecordResourceList" : [ {
"auditRecordId" : 1,
"createdBy" : null,
"correlationId" : "timelog",
"auditData" : "time --format='YYYY MM DD' | log",
"createdOn" : "2018-12-05T14:41:54.902Z",
"auditAction" : "CREATE",
"auditOperation" : "STREAM",
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.5.流定义
已注册的应用程序端点提供有关在Spring Cloud Data Flow服务器中注册的流定义的信息。以下主题提供了更多详细信息:
70.5.1.创建新的流定义
通过为流定义端点创建POST请求来实现创建流定义。ticktock流的curl请求可能类似于以下内容:
curl -X POST -d "name=ticktock&definition=time | log" localhost:9393/streams/definitions?deploy=false流定义还可以包含其他参数。例如,在“ 请求结构 ” 下显示的示例中,我们还提供了日期时间格式。
以下主题提供了更多详细信息:
请求结构
POST /streams/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&deploy=false请求参数
| 参数 | 描述 |
|---|---|
|
创建的任务定义的名称 |
|
流的定义,使用Data Flow DSL |
|
如果为true,则在创建时部署流(默认为false) |
示例请求
$ curl 'http://localhost:9393/streams/definitions' -i -X POST -d 'name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&deploy=false'响应结构
HTTP/1.1 201 Created
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 307
{
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
}70.5.2.列出所有流定义
流端点允许您列出所有流定义。以下主题提供了更多详细信息:
请求结构
GET /streams/definitions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/streams/definitions?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 628
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.5.3.列出相关的流定义
流端点允许您列出相关的流定义。以下主题提供了更多详细信息:
请求结构
GET /streams/definitions/timelog/related?nested=true HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
我们是否应该递归地找到相关流定义的ByNameLike(可选) |
示例请求
$ curl 'http://localhost:9393/streams/definitions/timelog/related?nested=true' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 644
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog/related?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.5.4.删除单流定义
流端点允许您删除单个流定义。(另请参阅:删除所有流定义。)以下主题提供了更多详细信息:
请求结构
DELETE /streams/definitions/timelog HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/definitions/timelog' -i -X DELETE响应结构
HTTP/1.1 200 OK70.6.流验证
流验证端点允许您在流定义中验证应用程序。以下主题提供了更多详细信息:
70.6.1.请求结构
GET /streams/validation/timelog HTTP/1.1
Host: localhost:939370.6.2.请求参数
此端点没有请求参数。
70.6.3.示例请求
$ curl 'http://localhost:9393/streams/validation/timelog' -i70.6.4.响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 152
{
"appName" : "timelog",
"dsl" : "time --format='YYYY MM DD' | log",
"appStatuses" : {
"source:time" : "valid",
"sink:log" : "valid"
}
}70.7.流部署
部署定义端点提供有关使用Spring Cloud Data Flow服务器注册的部署的信息。以下主题提供了更多详细信息:
70.7.1.部署流定义
流定义端点允许您部署单个流定义。(可选)您可以将应用程序参数作为属性传递到请求正文中。以下主题提供了更多详细信息:
请求结构
POST /streams/deployments/timelog HTTP/1.1
Content-Type: application/json
Host: localhost:9393
Content-Length: 36
{"app.time.timestamp.format":"YYYY"}| 参数 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/timelog' -i -X POST -H 'Content-Type: application/json' -d '{"app.time.timestamp.format":"YYYY"}'响应结构
HTTP/1.1 201 Created70.7.2.取消部署流定义
流定义端点允许您取消部署单个流定义。以下主题提供了更多详细信息:
请求结构
DELETE /streams/deployments/timelog HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/timelog' -i -X DELETE响应结构
HTTP/1.1 200 OK70.7.3.取消部署所有流定义
流定义端点允许您取消部署所有单个流定义。以下主题提供了更多详细信息:
请求结构
DELETE /streams/deployments HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments' -i -X DELETE响应结构
HTTP/1.1 200 OK70.7.4.更新已部署的流
在Skipper模式下使用Spring Cloud Data Flow时,您可以更新已部署的流,并提供其他部署属性。
| 要使用此功能,数据流服务器必须处于Skipper模式 |
请求结构
POST /streams/deployments/update/timelog1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393
Content-Length: 196
{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}| 参数 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/update/timelog1' -i -X POST -H 'Content-Type: application/json' -d '{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}'响应结构
HTTP/1.1 201 Created70.7.5.回滚流定义
将流回滚到前一个或特定版本的流。
| 要使用此功能,数据流服务器必须处于Skipper模式 |
请求结构
POST /streams/deployments/rollback/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
|
要回滚的版本 |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/rollback/timelog1/1' -i -X POST -H 'Content-Type: application/json'响应结构
HTTP/1.1 201 Created70.7.6.获得清单
返回已发布版本的清单。对于具有依赖项的包,清单包含这些依赖项的内容。
| 要使用此功能,数据流服务器必须处于Skipper模式 |
请求结构
GET /streams/deployments/manifest/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有流定义的名称(必需) |
|
流的版本 |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/streams/deployments/manifest/timelog1/1' -i -H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2332
"\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n---\n\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"70.7.7.获取部署历史记录
获取流的部署历史记录。
| 要使用此功能,数据流服务器必须处于Skipper模式 |
请求结构
GET /streams/deployments/history/timelog1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/deployments/history/timelog1' -i -H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 25705
[ {
"name" : "timelog1",
"version" : 3,
"info" : {
"status" : {
"statusCode" : "DEPLOYED",
"platformStatus" : "[{\"deploymentId\":\"timelog1.log-v1\",\"instances\":{\"timelog1.log-v1-0\":{\"instanceNumber\":0,\"baseUrl\":\"http://10.194.6.22:35443\",\"attributes\":{\"guid\":\"35443\",\"pid\":\"680\",\"port\":\"35443\",\"stderr\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544020970140/timelog1.log-v1/stderr_0.log\",\"stdout\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544020970140/timelog1.log-v1/stdout_0.log\",\"url\":\"http://10.194.6.22:35443\",\"working.dir\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544020970140/timelog1.log-v1\"},\"process\":{\"outputStream\":{},\"errorStream\":{},\"alive\":true,\"inputStream\":{}},\"id\":\"timelog1.log-v1-0\",\"state\":\"deployed\"}},\"state\":\"deployed\"},{\"deploymentId\":\"timelog1.time-v3\",\"instances\":{\"timelog1.time-v3-0\":{\"instanceNumber\":0,\"baseUrl\":\"http://10.194.6.22:56016\",\"attributes\":{\"guid\":\"56016\",\"pid\":\"1134\",\"port\":\"56016\",\"stderr\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544021031166/timelog1.time-v3/stderr_0.log\",\"stdout\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544021031166/timelog1.time-v3/stdout_0.log\",\"url\":\"http://10.194.6.22:56016\",\"working.dir\":\"/tmp/spring-cloud-deployer-2950880049650447965/timelog1-1544021031166/timelog1.time-v3\"},\"process\":{\"outputStream\":{},\"errorStream\":{},\"alive\":true,\"inputStream\":{}},\"id\":\"timelog1.time-v3-0\",\"state\":\"deployed\"}},\"state\":\"deployed\"}]"
},
"firstDeployed" : "2018-12-05T14:43:51.059+0000",
"lastDeployed" : "2018-12-05T14:43:51.059+0000",
"deleted" : null,
"description" : "Rollback complete"
},
"pkg" : {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : 2,
"repositoryName" : "local",
"kind" : "SpringCloudDeployerApplication",
"name" : "timelog1",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : "time --format='YYYY MM DD' | log",
"sha256" : null,
"iconUrl" : null
},
"templates" : [ ],
"dependencies" : [ {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "time",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "time.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
}, {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "log",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "log.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
} ],
"configValues" : null,
"fileHolders" : [ ]
},
"configValues" : {
"raw" : null
},
"manifest" : {
"data" : "\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.count\": \"1\"\n \"spring.cloud.deployer.group\": \"timelog1\"\n---\n\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"platformName" : "default"
}, {
"name" : "timelog1",
"version" : 2,
"info" : {
"status" : {
"statusCode" : "DELETED",
"platformStatus" : null
},
"firstDeployed" : "2018-12-05T14:43:20.554+0000",
"lastDeployed" : "2018-12-05T14:43:20.554+0000",
"deleted" : null,
"description" : "Delete complete"
},
"pkg" : {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : 2,
"repositoryName" : "local",
"kind" : "SpringCloudDeployerApplication",
"name" : "timelog1",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : "time --format='YYYY MM DD' | log",
"sha256" : null,
"iconUrl" : null
},
"templates" : [ ],
"dependencies" : [ {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "time",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "time.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
}, {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "log",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "log.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
} ],
"configValues" : null,
"fileHolders" : [ ]
},
"configValues" : {
"raw" : "log:\n spec:\n applicationProperties:\n spring.cloud.dataflow.stream.app.type: sink\ntime:\n spec:\n applicationProperties:\n timestamp.format: YYYYMMDD\n spring.cloud.dataflow.stream.app.type: source\n"
},
"manifest" : {
"data" : "\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYYMMDD\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.count\": \"1\"\n \"spring.cloud.deployer.group\": \"timelog1\"\n---\n\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"platformName" : "default"
}, {
"name" : "timelog1",
"version" : 1,
"info" : {
"status" : {
"statusCode" : "DELETED",
"platformStatus" : null
},
"firstDeployed" : "2018-12-05T14:42:49.973+0000",
"lastDeployed" : "2018-12-05T14:42:49.973+0000",
"deleted" : null,
"description" : "Delete complete"
},
"pkg" : {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : 2,
"repositoryName" : "local",
"kind" : "SpringCloudDeployerApplication",
"name" : "timelog1",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : "time --format='YYYY MM DD' | log",
"sha256" : null,
"iconUrl" : null
},
"templates" : [ ],
"dependencies" : [ {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "time",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "time.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
}, {
"metadata" : {
"apiVersion" : "skipper.spring.io/v1",
"origin" : null,
"repositoryId" : null,
"repositoryName" : null,
"kind" : "SpringCloudDeployerApplication",
"name" : "log",
"displayName" : null,
"version" : "1.0.0",
"packageSourceUrl" : null,
"packageHomeUrl" : null,
"tags" : null,
"maintainer" : "dataflow",
"description" : null,
"sha256" : null,
"iconUrl" : null
},
"templates" : [ {
"name" : "log.yml",
"data" : "apiVersion: skipper.spring.io/v1\nkind: SpringCloudDeployerApplication\nmetadata:\n {{#metadata.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/metadata.entrySet}}\nspec:\n resource: \"{{{spec.resource}}}\"\n resourceMetadata: \"{{{spec.resource}}}:jar:metadata:{{{spec.version}}}\"\n version: \"{{{spec.version}}}\"\n applicationProperties:\n {{#spec.applicationProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.applicationProperties.entrySet}}\n deploymentProperties:\n {{#spec.deploymentProperties.entrySet}}\n \"{{{key}}}\": \"{{{value}}}\"\n {{/spec.deploymentProperties.entrySet}}\n"
} ],
"dependencies" : [ ],
"configValues" : {
"raw" : "\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"version\": \"1.2.0.RELEASE\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"fileHolders" : [ ]
} ],
"configValues" : null,
"fileHolders" : [ ]
},
"configValues" : {
"raw" : null
},
"manifest" : {
"data" : "\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"time\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:time-source-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"timestamp.format\": \"YYYY\"\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"time\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.time.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.output.producer.requiredGroups\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"format\": \"YYYY MM DD\"\n \"spring.cloud.stream.bindings.output.destination\": \"timelog1.time\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"source\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n---\n\"apiVersion\": \"skipper.spring.io/v1\"\n\"kind\": \"SpringCloudDeployerApplication\"\n\"metadata\":\n \"name\": \"log\"\n\"spec\":\n \"resource\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit\"\n \"resourceMetadata\": \"maven://org.springframework.cloud.stream.app:log-sink-rabbit:jar:metadata:1.2.0.RELEASE\"\n \"version\": \"1.2.0.RELEASE\"\n \"applicationProperties\":\n \"spring.metrics.export.triggers.application.includes\": \"integration**\"\n \"spring.cloud.dataflow.stream.app.label\": \"log\"\n \"spring.cloud.stream.metrics.key\": \"timelog1.log.${spring.cloud.application.guid}\"\n \"spring.cloud.stream.bindings.input.group\": \"timelog1\"\n \"spring.cloud.stream.metrics.properties\": \"spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*\"\n \"spring.cloud.dataflow.stream.name\": \"timelog1\"\n \"spring.cloud.dataflow.stream.app.type\": \"sink\"\n \"spring.cloud.stream.bindings.input.destination\": \"timelog1.time\"\n \"deploymentProperties\":\n \"spring.cloud.deployer.group\": \"timelog1\"\n"
},
"platformName" : "default"
} ]70.7.8.获取部署平台
检索支持的部署平台列表。
| 要使用此功能,数据流服务器必须处于Skipper模式 |
请求结构
GET /streams/deployments/platform/list HTTP/1.1
Content-Type: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/streams/deployments/platform/list' -i -H 'Content-Type: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 287
[ {
"id" : null,
"name" : "default",
"type" : "local",
"description" : "ShutdownTimeout = [30], EnvVarsToInherit = [TMP,LANG,LANGUAGE,LC_.*,PATH,SPRING_APPLICATION_JSON], JavaCmd = [/opt/jdk1.8.0_144/jre/bin/java], WorkingDirectoriesRoot = [/tmp], DeleteFilesOnExit = [true]"
} ]70.8.任务定义
任务定义端点提供有关向Spring Cloud Data Flow服务器注册的任务定义的信息。以下主题提供了更多详细信息:
70.8.1.创建新的任务定义
任务定义端点允许您创建新的任务定义。以下主题提供了更多详细信息:
请求结构
POST /tasks/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27请求参数
| 参数 | 描述 |
|---|---|
|
创建的任务定义的名称 |
|
使用Data Flow DSL完成任务的定义 |
示例请求
$ curl 'http://localhost:9393/tasks/definitions' -i -X POST -d 'name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27'响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 255
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"composed" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}70.8.2.列出所有任务定义
任务定义端点允许您获取所有任务定义。以下主题提供了更多详细信息:
请求结构
GET /tasks/definitions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/definitions?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 576
{
"_embedded" : {
"taskDefinitionResourceList" : [ {
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"composed" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.8.3.检索任务定义详细信息
任务定义端点允许您获取单个任务定义。以下主题提供了更多详细信息:
请求结构
GET /tasks/definitions/my-task HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有任务定义的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/definitions/my-task' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 255
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"composed" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}70.8.4.删除任务定义
任务定义端点允许您删除单个任务定义。以下主题提供了更多详细信息:
请求结构
DELETE /tasks/definitions/my-task HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有任务定义的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/definitions/my-task' -i -X DELETE响应结构
HTTP/1.1 200 OK70.9.任务计划程序
任务计划程序端点提供有关使用计划程序实现注册的任务计划的信息。以下主题提供了更多详细信息:
70.9.1.创建新的任务计划
任务计划端点允许您创建新的任务计划。以下主题提供了更多详细信息:
请求结构
POST /tasks/schedules HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
scheduleName=myschedule&taskDefinitionName=mytaskname&properties=scheduler.cron.expression%3D00+22+17+%3F+*&arguments=--foo%3Dbar请求参数
| 参数 | 描述 |
|---|---|
|
创建的计划的名称 |
|
要计划的任务定义的名称 |
|
计划和启动任务所需的属性 |
|
用于启动任务的命令行参数 |
示例请求
$ curl 'http://localhost:9393/tasks/schedules' -i -X POST -d 'scheduleName=myschedule&taskDefinitionName=mytaskname&properties=scheduler.cron.expression%3D00+22+17+%3F+*&arguments=--foo%3Dbar'响应结构
HTTP/1.1 201 Created70.9.2.列出所有时间表
任务计划端点允许您获取所有任务计划。以下主题提供了更多详细信息:
请求结构
GET /tasks/schedules?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/schedules?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 585
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules?page=0&size=1"
}
},
"page" : {
"size" : 1,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.9.3.列出已过滤的计划
任务计划端点允许您获取具有指定任务定义名称的所有任务计划。以下主题提供了更多详细信息:
请求结构
GET /tasks/schedules/instances/FOO?page=0&size=10 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
根据指定的任务定义过滤计划(必需) |
请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 599
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=1"
}
},
"page" : {
"size" : 1,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.9.4.删除任务时间表
任务计划端点允许您删除单个任务计划。以下主题提供了更多详细信息:
请求结构
DELETE /tasks/schedules/mytestschedule HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有计划的名称(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/schedules/mytestschedule' -i -X DELETE响应结构
HTTP/1.1 200 OK70.10.任务验证
任务验证端点允许您在任务定义中验证应用程序。以下主题提供了更多详细信息:
请求结构
GET /tasks/validation/taskC HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/validation/taskC' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 122
{
"appName" : "taskC",
"dsl" : "timestamp --format='yyyy MM dd'",
"appStatuses" : {
"task:taskC" : "valid"
}
}70.11.任务执行
任务执行端点提供有关在Spring Cloud Data Flow服务器中注册的任务执行的信息。以下主题提供了更多详细信息:
70.11.1.启动任务
通过请求创建新任务执行来完成启动任务。以下主题提供了更多详细信息:
请求结构
POST /tasks/executions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3Dbar请求参数
| 参数 | 描述 |
|---|---|
|
要启动的任务定义的名称 |
|
启动时使用的Application和Deployer属性 |
|
要传递给任务的命令行参数 |
示例请求
$ curl 'http://localhost:9393/tasks/executions' -i -X POST -d 'name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3Dbar'响应结构
HTTP/1.1 201 Created
Content-Type: application/json;charset=UTF-8
Content-Length: 1
170.11.2.列出所有任务执行
任务执行端点允许您列出所有任务执行。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/tasks/executions?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 1243
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-7078e799-4b8c-4e4e-8cb8-8a31efd3177b",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/2"
}
}
}, {
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-8f3ba6ff-3b11-4a4b-82b2-60a623e45c2a",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.11.3.列出具有指定任务名称的所有任务执行
任务执行端点允许您列出具有指定任务名称的任务执行。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions?name=taskB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与任务执行关联的名称 |
示例请求
$ curl 'http://localhost:9393/tasks/executions?name=taskB&page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 758
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-7078e799-4b8c-4e4e-8cb8-8a31efd3177b",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/2"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.11.4.任务执行细节
任务执行端点允许您获取有关任务执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions/1 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有任务执行的id(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/executions/1' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 415
{
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-8f3ba6ff-3b11-4a4b-82b2-60a623e45c2a",
"taskExecutionStatus" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions/1"
}
}
}70.11.5.删除任务执行
任务执行端点允许您清理用于部署任务的资源。
| 清理实现是特定于平台的。 |
以下主题提供了更多详细信息:
请求结构
DELETE /tasks/executions/1 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有任务执行的id(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/executions/1' -i -X DELETE响应结构
HTTP/1.1 200 OK70.11.6.任务执行当前计数
任务执行当前端点允许您检索当前正在运行的执行数。以下主题提供了更多详细信息:
请求结构
GET /tasks/executions/current HTTP/1.1
Host: localhost:9393请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/tasks/executions/current' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 65
{
"maximumTaskExecutions" : 20,
"runningExecutionCount" : 1
}70.12.工作执行
作业执行端点提供有关在Spring Cloud Data Flow服务器中注册的作业执行的信息。以下主题提供了更多详细信息:
70.12.1.列出所有工作执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/jobs/executions?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 3357
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB_1",
"startDate" : "2018-12-05",
"startTime" : "14:42:12",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 2,
"version" : null,
"jobName" : "DOCJOB_1",
"instanceId" : 2
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2018-12-05T14:42:12.345Z",
"createTime" : "2018-12-05T14:42:12.343Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:12.345Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 2,
"stopping" : false,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2018-12-05",
"startTime" : "14:42:12",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 2,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 1,
"version" : null,
"jobName" : "DOCJOB",
"instanceId" : 1
},
"stepExecutions" : [ ],
"status" : "STOPPING",
"startTime" : "2018-12-05T14:42:12.339Z",
"createTime" : "2018-12-05T14:42:12.337Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:12.372Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 1,
"stopping" : true,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.12.2.列出具有指定作业名称的所有作业执行
作业执行端点允许您列出所有作业执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions?name=DOCJOB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与作业执行关联的名称 |
示例请求
$ curl 'http://localhost:9393/jobs/executions?name=DOCJOB&page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 1813
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2018-12-05",
"startTime" : "14:42:12",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 2,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 1,
"version" : null,
"jobName" : "DOCJOB",
"instanceId" : 1
},
"stepExecutions" : [ ],
"status" : "STOPPING",
"startTime" : "2018-12-05T14:42:12.339Z",
"createTime" : "2018-12-05T14:42:12.337Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:12.372Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 1,
"stopping" : true,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : true,
"stoppable" : false,
"defined" : false,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.12.3.工作执行细节
作业执行端点使您可以获取有关作业执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/2 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有作业执行的id(必填) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/2' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 1311
{
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB_1",
"startDate" : "2018-12-05",
"startTime" : "14:42:12",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 2,
"version" : 0,
"jobName" : "DOCJOB_1",
"instanceId" : 2
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2018-12-05T14:42:12.345Z",
"createTime" : "2018-12-05T14:42:12.343Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:12.345Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 2,
"stopping" : false,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2"
}
}
}70.12.4.停止执行作业
作业执行端点允许您停止作业执行。以下主题提供了更多详细信息:
请求结构
PUT /jobs/executions/1 HTTP/1.1
Accept: application/json
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
stop=true| 参数 | 描述 |
|---|---|
|
现有作业执行的id(必填) |
请求参数
| 参数 | 描述 |
|---|---|
|
如果设置为true,则发送信号以停止作业 |
示例请求
$ curl 'http://localhost:9393/jobs/executions/1' -i -X PUT -H 'Accept: application/json' -d 'stop=true'响应结构
HTTP/1.1 200 OK70.12.5.重新启动作业执行
作业执行端点允许您重新启动作业执行。以下主题提供了更多详细信息:
请求结构
PUT /jobs/executions/2 HTTP/1.1
Accept: application/json
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
restart=true| 参数 | 描述 |
|---|---|
|
现有作业执行的id(必填) |
请求参数
| 参数 | 描述 |
|---|---|
|
如果设置为true,则发送信号以重新启动作业 |
示例请求
$ curl 'http://localhost:9393/jobs/executions/2' -i -X PUT -H 'Accept: application/json' -d 'restart=true'响应结构
HTTP/1.1 200 OK70.13.工作实例
作业实例端点提供有关在Spring Cloud Data Flow服务器中注册的作业实例的信息。以下主题提供了更多详细信息:
70.13.1.列出所有作业实例
作业实例端点允许您列出所有作业实例。以下主题提供了更多详细信息:
请求结构
GET /jobs/instances?name=DOCJOB&page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
|
与作业实例关联的名称 |
示例请求
$ curl 'http://localhost:9393/jobs/instances?name=DOCJOB&page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 2002
{
"_embedded" : {
"jobInstanceResourceList" : [ {
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2018-12-05",
"startTime" : "14:42:08",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 1,
"version" : 0,
"jobName" : "DOCJOB",
"instanceId" : 1
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2018-12-05T14:42:08.528Z",
"createTime" : "2018-12-05T14:42:08.526Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:08.528Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 1,
"stopping" : false,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : false,
"timeZone" : "UTC"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.13.2.工作实例细节
作业实例端点允许您列出所有作业实例。以下主题提供了更多详细信息:
请求结构
GET /jobs/instances/1 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有作业实例的ID(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/instances/1' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 1487
{
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2018-12-05",
"startTime" : "14:42:08",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobInstance" : {
"id" : 1,
"version" : 0,
"jobName" : "DOCJOB",
"instanceId" : 1
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2018-12-05T14:42:08.528Z",
"createTime" : "2018-12-05T14:42:08.526Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:42:08.528Z",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : "",
"running" : true
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"failureExceptions" : [ ],
"jobConfigurationName" : null,
"running" : true,
"jobId" : 1,
"stopping" : false,
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : false,
"timeZone" : "UTC"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
}70.14.工作步骤执行
作业步骤执行端点提供有关在Spring Cloud Data Flow服务器中注册的作业步骤执行的信息。以下主题提供了更多详细信息:
70.14.1.列出作业执行的所有步骤执行
作业步骤执行端点允许您列出所有作业步骤执行。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps?page=0&size=10 HTTP/1.1
Host: localhost:9393请求参数
| 参数 | 描述 |
|---|---|
|
从零开始的页码(可选) |
|
请求的页面大小(可选) |
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps?page=0&size=10' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 1669
{
"_embedded" : {
"stepExecutionResourceList" : [ {
"jobExecutionId" : 1,
"stepExecution" : {
"id" : 1,
"version" : 0,
"stepName" : "DOCJOB_STEP",
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2018-12-05T14:41:50.841Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:41:50.842Z",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : "",
"running" : true
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobExecutionId" : 1,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"skipCount" : 0
},
"stepType" : "",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}70.14.2.工作步骤执行细节
作业步骤执行端点允许您获取有关作业步骤执行的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps/1 HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有作业执行的id(必填) |
|
特定作业执行的现有步骤执行的id(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps/1' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 1211
{
"jobExecutionId" : 1,
"stepExecution" : {
"id" : 1,
"version" : 0,
"stepName" : "DOCJOB_STEP",
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2018-12-05T14:41:50.841Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:41:50.842Z",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : "",
"running" : true
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobExecutionId" : 1,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"skipCount" : 0
},
"stepType" : "",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
}70.14.3.工作步骤执行进度
作业步骤执行端点允许您获取有关作业步骤执行进度的详细信息。以下主题提供了更多详细信息:
请求结构
GET /jobs/executions/1/steps/1/progress HTTP/1.1
Host: localhost:9393| 参数 | 描述 |
|---|---|
|
现有作业执行的id(必填) |
|
特定作业执行的现有步骤执行的id(必需) |
请求参数
此端点没有请求参数。
示例请求
$ curl 'http://localhost:9393/jobs/executions/1/steps/1/progress' -i响应结构
HTTP/1.1 200 OK
Content-Type: application/hal+json;charset=UTF-8
Content-Length: 2714
{
"stepExecution" : {
"id" : 1,
"version" : 0,
"stepName" : "DOCJOB_STEP",
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2018-12-05T14:41:50.841Z",
"endTime" : null,
"lastUpdated" : "2018-12-05T14:41:50.842Z",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : "",
"running" : true
},
"terminateOnly" : false,
"filterCount" : 0,
"failureExceptions" : [ ],
"jobParameters" : {
"parameters" : { },
"empty" : true
},
"jobExecutionId" : 1,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"skipCount" : 0
},
"stepExecutionHistory" : {
"stepName" : "DOCJOB_STEP",
"count" : 0,
"commitCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"rollbackCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"readCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"writeCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"filterCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"readSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"writeSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"processSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"duration" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"durationPerRead" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
}
},
"percentageComplete" : 0.5,
"finished" : false,
"duration" : 124.0,
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
}70.15.有关应用程序的运行时信息
可以全局或单独获取有关运行系统已知应用程序的信息。以下主题提供了更多详细信息:
70.15.1.在运行时列出所有应用程序
要检索有关所有应用程序的所有实例的信息,请使用GET查询/runtime/apps端点。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2555
{
"_embedded" : {
"appStatusResourceList" : [ {
"deploymentId" : "mystream.http",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.http-0",
"state" : "deploying",
"attributes" : {
"guid" : "27559",
"pid" : "32072",
"port" : "27559",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stdout_0.log",
"url" : "http://10.194.6.22:27559",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http/instances/mystream.http-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http"
}
}
}, {
"deploymentId" : "mystream.log",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.log-0",
"state" : "deploying",
"attributes" : {
"guid" : "47453",
"pid" : "32057",
"port" : "47453",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stdout_0.log",
"url" : "http://10.194.6.22:47453",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log/instances/mystream.log-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.15.2.查询单个应用程序的所有实例
要检索有关特定应用程序的所有实例的信息,请使用GET查询/runtime/apps/<appId>/instances端点。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2555
{
"_embedded" : {
"appStatusResourceList" : [ {
"deploymentId" : "mystream.http",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.http-0",
"state" : "deploying",
"attributes" : {
"guid" : "27559",
"pid" : "32072",
"port" : "27559",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stdout_0.log",
"url" : "http://10.194.6.22:27559",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http/instances/mystream.http-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http"
}
}
}, {
"deploymentId" : "mystream.log",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.log-0",
"state" : "deploying",
"attributes" : {
"guid" : "47453",
"pid" : "32057",
"port" : "47453",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stdout_0.log",
"url" : "http://10.194.6.22:47453",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log/instances/mystream.log-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.15.3.查询单个应用程序的单个实例
最后,要检索有关特定应用程序的特定实例的信息,请使用GET查询/runtime/apps/<appId>/instances/<instanceId>端点。以下主题提供了更多详细信息:
请求结构
GET /runtime/apps HTTP/1.1
Accept: application/json
Host: localhost:9393示例请求
$ curl 'http://localhost:9393/runtime/apps' -i -H 'Accept: application/json'响应结构
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 2555
{
"_embedded" : {
"appStatusResourceList" : [ {
"deploymentId" : "mystream.http",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.http-0",
"state" : "deploying",
"attributes" : {
"guid" : "27559",
"pid" : "32072",
"port" : "27559",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http/stdout_0.log",
"url" : "http://10.194.6.22:27559",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885880/mystream.http"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http/instances/mystream.http-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.http"
}
}
}, {
"deploymentId" : "mystream.log",
"state" : "deploying",
"instances" : {
"_embedded" : {
"appInstanceStatusResourceList" : [ {
"instanceId" : "mystream.log-0",
"state" : "deploying",
"attributes" : {
"guid" : "47453",
"pid" : "32057",
"port" : "47453",
"stderr" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stderr_0.log",
"stdout" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log/stdout_0.log",
"url" : "http://10.194.6.22:47453",
"working.dir" : "/tmp/spring-cloud-deployer-6288619770241875731/mystream-1544020885775/mystream.log"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log/instances/mystream.log-0"
}
}
} ]
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps/mystream.log"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/runtime/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}70.16.流应用程序的度量标准
此REST端点公开流应用程序的度量标准。它要求Metrics Collector应用程序作为单独的服务运行。如果它未运行,则此端点返回空响应。
| 要了解有关Metrics Collector的更多信息,请参阅“ 监视已部署的流应用程序 ”一章。 |
以下主题提供了更多详细信息:
70.16.1.请求结构
例如,典型的请求可能类似于以下内容:
GET /metrics/streams HTTP/1.1
Accept: application/json
Host: localhost:939370.16.2.示例请求
$ curl 'http://localhost:9393/metrics/streams' -i -H 'Accept: application/json'70.16.3.响应结构
此REST端点使用Hystrix通过封面下的Spring Cloud Netflix项目向Metrics Collector发出代理HTTP请求。
70.16.4.示例响应
Metrics Collector未运行时,端点不会生成错误。相反,它优雅地降级并返回空响应,如下所示:
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 3
[ ]但是,如果正在收集度量标准并且Metrics Collector正在运行,您应该会看到类似于下面列表的响应。下面列表中返回的度量标准数据基于在“ Monitoring Deployed Stream Applications ”一章中创建的示例流定义,其中我们创建了time | log,其中部署了每个应用程序的两个实例。
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Content-Length: 30240
[ {
"name" : "foostream",
"applications" : [ {
"name" : "log120RS",
"instances" : [ {
"guid" : "13208",
"index" : 1,
"properties" : {
"spring.cloud.dataflow.stream.app.label" : "log120RS",
"spring.application.index" : "1",
"spring.application.name" : "log-sink",
"spring.cloud.dataflow.stream.name" : "foostream",
"spring.cloud.application.guid" : "13208",
"spring.cloud.dataflow.stream.app.type" : "sink",
"spring.cloud.application.group" : "foostream"
},
"metrics" : [ {
"name" : "integration.channel.input.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.input.sendCount",
"value" : 373.0
}, {
"name" : "integration.channel.input.sendRate.mean",
"value" : 1.0
}, {
"name" : "integration.channel.input.sendRate.max",
"value" : 2.01
}, {
"name" : "integration.channel.input.sendRate.min",
"value" : 0.7
}, {
"name" : "integration.channel.input.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.input.sendRate.count",
"value" : 373.0
}, {
"name" : "integration.channel.errorChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendCount",
"value" : 74.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.mean",
"value" : 0.2
}, {
"name" : "integration.channel.applicationMetrics.sendRate.max",
"value" : 13.49
}, {
"name" : "integration.channel.applicationMetrics.sendRate.min",
"value" : 5.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.count",
"value" : 74.0
}, {
"name" : "integration.channel.nullChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.mean",
"value" : 0.22
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.max",
"value" : 5.42
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.min",
"value" : 0.11
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.stdev",
"value" : 0.17
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.count",
"value" : 373.0
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handler.logSinkHandler.duration.mean",
"value" : 0.22
}, {
"name" : "integration.handler.logSinkHandler.duration.max",
"value" : 5.4
}, {
"name" : "integration.handler.logSinkHandler.duration.min",
"value" : 0.11
}, {
"name" : "integration.handler.logSinkHandler.duration.stdev",
"value" : 0.17
}, {
"name" : "integration.handler.logSinkHandler.duration.count",
"value" : 373.0
}, {
"name" : "integration.handler.logSinkHandler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.mean",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.max",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.min",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.stdev",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handlerCount",
"value" : 3.0
}, {
"name" : "integration.channelCount",
"value" : 4.0
}, {
"name" : "integration.sourceCount",
"value" : 0.0
}, {
"name" : "integration.channel.input.send.mean",
"value" : 1.0
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.2
}, {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
} ]
}, {
"guid" : "60633",
"index" : 0,
"properties" : {
"spring.cloud.dataflow.stream.app.label" : "log120RS",
"spring.application.index" : "0",
"spring.application.name" : "log-sink",
"spring.cloud.dataflow.stream.name" : "foostream",
"spring.cloud.application.guid" : "60633",
"spring.cloud.dataflow.stream.app.type" : "sink",
"spring.cloud.application.group" : "foostream"
},
"metrics" : [ {
"name" : "integration.channel.input.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.input.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.input.sendCount",
"value" : 372.0
}, {
"name" : "integration.channel.input.sendRate.mean",
"value" : 1.0
}, {
"name" : "integration.channel.input.sendRate.max",
"value" : 1.98
}, {
"name" : "integration.channel.input.sendRate.min",
"value" : 0.8
}, {
"name" : "integration.channel.input.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.input.sendRate.count",
"value" : 372.0
}, {
"name" : "integration.channel.errorChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendCount",
"value" : 74.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.mean",
"value" : 0.2
}, {
"name" : "integration.channel.applicationMetrics.sendRate.max",
"value" : 13.09
}, {
"name" : "integration.channel.applicationMetrics.sendRate.min",
"value" : 5.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.count",
"value" : 74.0
}, {
"name" : "integration.channel.nullChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.mean",
"value" : 0.22
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.max",
"value" : 3.46
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.min",
"value" : 0.12
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.stdev",
"value" : 0.18
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.duration.count",
"value" : 372.0
}, {
"name" : "integration.handler.org.springframework.cloud.stream.app.log.sink.LogSinkConfiguration.logSinkHandler.serviceActivator.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handler.logSinkHandler.duration.mean",
"value" : 0.21
}, {
"name" : "integration.handler.logSinkHandler.duration.max",
"value" : 2.84
}, {
"name" : "integration.handler.logSinkHandler.duration.min",
"value" : 0.11
}, {
"name" : "integration.handler.logSinkHandler.duration.stdev",
"value" : 0.18
}, {
"name" : "integration.handler.logSinkHandler.duration.count",
"value" : 372.0
}, {
"name" : "integration.handler.logSinkHandler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.mean",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.max",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.min",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.stdev",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.handlerCount",
"value" : 3.0
}, {
"name" : "integration.channelCount",
"value" : 4.0
}, {
"name" : "integration.sourceCount",
"value" : 0.0
}, {
"name" : "integration.channel.input.send.mean",
"value" : 1.0
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.2
}, {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
} ]
} ],
"aggregateMetrics" : [ {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.4
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.input.send.mean",
"value" : 2.0
} ]
}, {
"name" : "time120RS",
"instances" : [ {
"guid" : "50467",
"index" : 0,
"properties" : {
"spring.cloud.dataflow.stream.app.label" : "time120RS",
"spring.application.index" : "0",
"spring.application.name" : "time-source",
"spring.cloud.dataflow.stream.name" : "foostream",
"spring.cloud.application.guid" : "50467",
"spring.cloud.dataflow.stream.app.type" : "source",
"spring.cloud.application.group" : "foostream"
},
"metrics" : [ {
"name" : "integration.channel.output.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.output.sendCount",
"value" : 369.0
}, {
"name" : "integration.channel.output.sendRate.mean",
"value" : 1.0
}, {
"name" : "integration.channel.output.sendRate.max",
"value" : 1.02
}, {
"name" : "integration.channel.output.sendRate.min",
"value" : 1.0
}, {
"name" : "integration.channel.output.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.output.sendRate.count",
"value" : 369.0
}, {
"name" : "integration.channel.errorChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendCount",
"value" : 73.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.mean",
"value" : 0.2
}, {
"name" : "integration.channel.applicationMetrics.sendRate.max",
"value" : 11.05
}, {
"name" : "integration.channel.applicationMetrics.sendRate.min",
"value" : 5.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.count",
"value" : 73.0
}, {
"name" : "integration.channel.nullChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.mean",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.max",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.min",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.stdev",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.source.org.springframework.cloud.stream.app.time.source.TimeSourceConfiguration.publishTime.inboundChannelAdapter.source.messageCount",
"value" : 369.0
}, {
"name" : "integration.handlerCount",
"value" : 1.0
}, {
"name" : "integration.channelCount",
"value" : 4.0
}, {
"name" : "integration.sourceCount",
"value" : 1.0
}, {
"name" : "integration.channel.output.send.mean",
"value" : 1.0
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.2
}, {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
} ]
}, {
"guid" : "61434",
"index" : 1,
"properties" : {
"spring.cloud.dataflow.stream.app.label" : "time120RS",
"spring.application.index" : "1",
"spring.application.name" : "time-source",
"spring.cloud.dataflow.stream.name" : "foostream",
"spring.cloud.application.guid" : "61434",
"spring.cloud.dataflow.stream.app.type" : "source",
"spring.cloud.application.group" : "foostream"
},
"metrics" : [ {
"name" : "integration.channel.output.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.output.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.output.sendCount",
"value" : 375.0
}, {
"name" : "integration.channel.output.sendRate.mean",
"value" : 1.0
}, {
"name" : "integration.channel.output.sendRate.max",
"value" : 1.02
}, {
"name" : "integration.channel.output.sendRate.min",
"value" : 1.0
}, {
"name" : "integration.channel.output.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.output.sendRate.count",
"value" : 375.0
}, {
"name" : "integration.channel.errorChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.errorChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendCount",
"value" : 74.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.mean",
"value" : 0.2
}, {
"name" : "integration.channel.applicationMetrics.sendRate.max",
"value" : 12.88
}, {
"name" : "integration.channel.applicationMetrics.sendRate.min",
"value" : 5.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.sendRate.count",
"value" : 74.0
}, {
"name" : "integration.channel.nullChannel.errorRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.errorRate.count",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendCount",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.mean",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.max",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.min",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.stdev",
"value" : 0.0
}, {
"name" : "integration.channel.nullChannel.sendRate.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.mean",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.max",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.min",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.stdev",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.duration.count",
"value" : 0.0
}, {
"name" : "integration.handler._org.springframework.integration.errorLogger.handler.activeCount",
"value" : 0.0
}, {
"name" : "integration.source.org.springframework.cloud.stream.app.time.source.TimeSourceConfiguration.publishTime.inboundChannelAdapter.source.messageCount",
"value" : 375.0
}, {
"name" : "integration.handlerCount",
"value" : 1.0
}, {
"name" : "integration.channelCount",
"value" : 4.0
}, {
"name" : "integration.sourceCount",
"value" : 1.0
}, {
"name" : "integration.channel.output.send.mean",
"value" : 1.0
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.2
}, {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
} ]
} ],
"aggregateMetrics" : [ {
"name" : "integration.channel.output.send.mean",
"value" : 2.0
}, {
"name" : "integration.channel.nullChannel.send.mean",
"value" : 0.0
}, {
"name" : "integration.channel.applicationMetrics.send.mean",
"value" : 0.4
}, {
"name" : "integration.channel.errorChannel.send.mean",
"value" : 0.0
} ]
} ]
} ]附录
遇到Spring Cloud Data Flow问题,我们想帮忙!
-
提出问题 - 我们监控stackoverflow.com以获取标记的问题
spring-cloud-dataflow。 -
在github.com/spring-cloud/spring-cloud-dataflow/issues上使用Spring Cloud Data Flow报告错误。
附录A:数据流模板
如前一章所述,Spring Cloud Data Flow的功能完全通过REST端点公开。虽然您可以直接使用这些端点,但Spring Cloud Data Flow还提供了基于Java的API,这使得使用这些REST端点变得更加容易。
中心入口点是org.springframework.cloud.dataflow.rest.client包中的DataFlowTemplate类。
此类实现DataFlowOperations接口并委托给以下子模板,这些子模板为每个功能集提供特定功能:
| 接口 | 描述 |
|---|---|
|
用于流操作的REST客户端 |
|
REST客户端用于计数器操作 |
|
用于字段值计数器操作的REST客户端 |
|
REST客户端用于聚合计数器操作 |
|
用于任务操作的REST客户端 |
|
用于作业操作的REST客户端 |
|
用于app注册表操作的REST客户端 |
|
用于完成操作的REST客户端 |
|
REST Client用于运行时操作 |
初始化DataFlowTemplate时,可以通过HATEOAS提供的REST关系发现子模板。[ 1 ]
| 如果无法解析资源,则相应的子模板将导致NULL。一个常见原因是Spring Cloud Data Flow提供了启动时启用/禁用的特定功能集。有关更多信息,请参阅“ 功能切换 ”。 |
A.1.使用数据流模板
使用数据流模板时,唯一需要的数据流依赖项是Spring Cloud Data Flow Rest Client,如以下Maven代码段所示:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>1.7.3.RELEASE</version>
</dependency>使用该依赖项,您将获得DataFlowTemplate类以及调用Spring Cloud Data Flow服务器所需的所有依赖项。
实例化DataFlowTemplate时,您还传入RestTemplate。请注意,所需的RestTemplate需要一些额外的配置才能在DataFlowTemplate的上下文中有效。将RestTemplate声明为bean时,以下配置就足够了:
@Bean
public static RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(new VndErrorResponseErrorHandler(restTemplate.getMessageConverters()));
for(HttpMessageConverter<?> converter : restTemplate.getMessageConverters()) {
if (converter instanceof MappingJackson2HttpMessageConverter) {
final MappingJackson2HttpMessageConverter jacksonConverter =
(MappingJackson2HttpMessageConverter) converter;
jacksonConverter.getObjectMapper()
.registerModule(new Jackson2HalModule())
.addMixIn(JobExecution.class, JobExecutionJacksonMixIn.class)
.addMixIn(JobParameters.class, JobParametersJacksonMixIn.class)
.addMixIn(JobParameter.class, JobParameterJacksonMixIn.class)
.addMixIn(JobInstance.class, JobInstanceJacksonMixIn.class)
.addMixIn(ExitStatus.class, ExitStatusJacksonMixIn.class)
.addMixIn(StepExecution.class, StepExecutionJacksonMixIn.class)
.addMixIn(ExecutionContext.class, ExecutionContextJacksonMixIn.class)
.addMixIn(StepExecutionHistory.class, StepExecutionHistoryJacksonMixIn.class);
}
}
return restTemplate;
}现在,您可以使用以下代码实例化DataFlowTemplate:
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate(
new URI("http://localhost:9393/"), restTemplate); (1)| 1 | URI指向Spring Cloud Data Flow服务器的ROOT。 |
根据您的要求,您现在可以调用服务器。例如,如果要获取当前可用应用程序的列表,可以运行以下代码:
PagedResources<AppRegistrationResource> apps = dataFlowTemplate.appRegistryOperations().list();
System.out.println(String.format("Retrieved %s application(s)",
apps.getContent().size()));
for (AppRegistrationResource app : apps.getContent()) {
System.out.println(String.format("App Name: %s, App Type: %s, App URI: %s",
app.getName(),
app.getType(),
app.getUri()));
}附录B:“操作方法”指南
本节提供了使用Spring Cloud Data Flow时经常出现的一些常见“我该怎么做......”类型的问题的答案。
如果您遇到我们未在此处讨论的特定问题,您可能需要查看stackoverflow.com以查看是否有人已提供答案。这也是提出新问题的好地方(请使用spring-cloud-dataflow标签)。
我们也非常乐意扩展这一部分。如果您想添加“操作方法”,可以向我们发送拉取请求。
B.1.配置Maven Properties
您可以在启动数据流服务器时通过命令行属性设置maven属性,例如本地maven存储库位置,远程maven存储库,身份验证凭据和代理服务器属性。或者,您可以使用数据流服务器的SPRING_APPLICATION_JSON环境属性设置属性。
如果使用maven存储库解析应用程序,则需要显式配置远程maven存储库,但local数据流服务器除外。其他数据流服务器实现(使用maven资源进行应用程序工件解析)没有远程存储库的默认值。local服务器具有repo.spring.io/libs-snapshot作为默认远程存储库。
要将属性作为命令行选项传递,请使用与以下内容类似的命令运行服务器:
$ java -jar <dataflow-server>.jar --maven.localRepository=mylocal
--maven.remote-repositories.repo1.url=https://repo1
--maven.remote-repositories.repo1.auth.username=repo1user
--maven.remote-repositories.repo1.auth.password=repo1pass
--maven.remote-repositories.repo2.url=https://repo2 --maven.proxy.host=proxyhost
--maven.proxy.port=9018 --maven.proxy.auth.username=proxyuser
--maven.proxy.auth.password=proxypass您还可以使用SPRING_APPLICATION_JSON环境属性:
export SPRING_APPLICATION_JSON='{ "maven": { "local-repository": "local","remote-repositories": { "repo1": { "url": "https://repo1", "auth": { "username": "repo1user", "password": "repo1pass" } },
"repo2": { "url": "https://repo2" } }, "proxy": { "host": "proxyhost", "port": 9018, "auth": { "username": "proxyuser", "password": "proxypass" } } } }'以下是格式良好的JSON中的相同内容:
SPRING_APPLICATION_JSON='{
"maven": {
"local-repository": "local",
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}'
根据Spring Cloud Data Flow服务器实现,您可能必须使用特定于平台的环境设置功能来传递环境属性。例如,在Cloud Foundry中,您将它们传递为cf set-env SPRING_APPLICATION_JSON。
|
B.2.记录
Spring Cloud Data Flow基于多个Spring项目构建,但最终数据流服务器是Spring Boot应用程序,因此适用于任何Spring Boot应用程序的日志记录技术也适用于此。
在进行故障排除时,启用DEBUG日志的两个主要区域可能是有用的
B.2.1.部署日志
Spring Cloud Data Flow建立在Spring Cloud Deployer SPI 之上,而特定于平台的数据流服务器使用相应的SPI实现。具体来说,如果我们要解决部署特定问题(例如网络错误),那么在底层部署程序及其使用的库中启用DEBUG日志会很有用。
要为local-deployer启用DEBUG日志,请按如下所示启动服务器:
$ java -jar <dataflow-server>.jar --logging.level.org.springframework.cloud.deployer.spi.local=DEBUG(其中org.springframework.cloud.deployer.spi.local是本地部署者相关的全局包。)
要为cloudfoundry-deployer启用DEBUG日志,请设置以下环境变量,并在重新分配数据流服务器后,您可以查看有关请求和响应的更多日志,并查看故障的详细堆栈跟踪。cloudfoundry部署者使用cf-java-client,因此您还必须为此库启用DEBUG日志。
$ cf set-env dataflow-server JAVA_OPTS '-Dlogging.level.cloudfoundry-client=DEBUG'
$ cf restage dataflow-server(其中cloudfoundry-client是所有与cf-java-client相关的全局包。)
要查看cf-java-client使用的Reactor日志,那么下面的commad会有所帮助:
$ cf set-env dataflow-server JAVA_OPTS '-Dlogging.level.cloudfoundry-client=DEBUG -Dlogging.level.reactor.ipc.netty=DEBUG'
$ cf restage dataflow-server(其中reactor.ipc.netty是与reactor-netty相关的全局包。)
与上面讨论的local-deployer和cloudfoundry-deployer选项类似,Kubernetes也有相同的设置。有关要为日志记录配置的程序包的更多详细信息,请参阅相应的SPI实现。
|
B.2.2.应用程序日志
Spring Cloud Data Flow中的流应用程序是Spring Cloud Stream应用程序,而这些应用程序又基于Spring Boot。可以使用日志记录配置独立设置它们。
例如,如果您必须对围绕源,处理器和接收器通道传递的header和payload细节进行故障排除,则应使用以下选项部署该流:
dataflow:>stream create foo --definition "http --logging.level.org.springframework.integration=DEBUG | transform --logging.level.org.springframework.integration=DEBUG | log --logging.level.org.springframework.integration=DEBUG" --deploy(其中org.springframework.integration是所有Spring Integration相关的全局包,负责消息传递通道。)
在部署流时,也可以使用deployment属性指定这些属性,如下所示:
dataflow:>stream deploy foo --properties "app.*.logging.level.org.springframework.integration=DEBUG"B.2.3.远程调试
数据流本地服务器允许您调试已部署的应用程序。这是通过部署适当的方式启用JVM的远程调试功能来实现的,如以下示例所示:
stream deploy --name mystream --properties "deployer.fooApp.local.debugPort=9999"上面的示例在调试模式下启动fooApp应用程序,允许在端口9999上附加远程调试器。默认情况下,应用程序以“挂起”模式启动并等待连接(启动)远程调试会话。否则,您可以提供额外的debugSuspend属性,其值为n。
此外,当存在多个应用程序实例时,每个实例的调试端口是debugPort + instanceId的值。
| 与其他属性不同,您不能对应用程序名称使用通配符,因为每个应用程序都必须使用唯一的调试端口。 |
B.2.4.记录重定向
鉴于每个应用程序都是一个维护自己的日志集的独立进程,访问单个日志可能有点不方便,特别是在开发的早期阶段,更频繁地访问日志。由于依赖于将每个应用程序部署为本地JVM进程的本地SCDF服务器也是一种常见模式,因此可以将stdout和stdin从已部署的应用程序重定向到父进程。因此,对于本地SCDF服务器,应用程序日志将显示在正在运行的本地SCDF服务器的日志中。
通常,在部署流时,您会在服务器日志中看到类似以下内容的内容:
017-06-28 09:50:16.372 INFO 41161 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalAppDeployer : Deploying app with deploymentId mystream.myapp instance 0.
Logs will be in /var/folders/l2/63gcnd9d7g5dxxpjbgr0trpw0000gn/T/spring-cloud-dataflow-5939494818997196225/mystream-1498661416369/mystream.myapp但是,通过将local.inheritLogging=true设置为部署属性,您可以看到以下内容:
017-06-28 09:50:16.372 INFO 41161 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalAppDeployer : Deploying app with deploymentId mystream.myapp instance 0.
Logs will be inherited.之后,应用程序日志将显示在服务器日志旁边,如以下示例所示:
stream deploy --name mystream --properties "deployer.*.local.inheritLogging=true”前面的流定义为流中的每个应用程序启用日志重定向。以下流定义仅为名为“my app”的应用程序启用日志重定向。
stream deploy --name mystream --properties "deployer.myapp.local.inheritLogging=true”| 只有local-deployer支持日志重定向。 |
B.3.经常问的问题
在本节中,我们将回顾Spring Cloud Data Flow中的常见问题。
B.3.1.高级SpEL表达式
SpEL表达式的一个强大功能是函数。如果适当的库在类路径中,Spring Integration提供jsonPath()和xpath() SpEL - 函数。所有提供的Spring Cloud Stream应用程序启动程序都在其超级jar中使用json-path和spring-integration-xml。因此,只要表达式可行,我们就可以在Spring Cloud Data Flow流中使用那些SpEL - 函数。例如,我们可以使用几个jsonPath()表达式从HTTP请求转换支持JSON的payload,如下所示:
dataflow:>stream create jsonPathTransform --definition "http | transform --expression=#jsonPath(payload,'$.price') | log" --deploy
...
dataflow:> http post --target http://localhost:8080 --data {"symbol":"SCDF","price":72.04}
dataflow:> http post --target http://localhost:8080 --data {"symbol":"SCDF","price":72.06}
dataflow:> http post --target http://localhost:8080 --data {"symbol":"SCDF","price":72.08}在前面的示例中,我们对传入的有效负载应用jsonPath以仅提取price字段值。类似的语法可以与splitter或filter expression选项一起使用。实际上,任何可用的基于SpEL的选项都可以访问内置的SpEL - 函数。例如,我们可以从JSON数据中提取一些值,以便在将输出发送到Binder之前计算partitionKey,如下所示:
dataflow:>stream deploy foo --properties "deployer.transform.count=2,app.transform.producer.partitionKeyExpression=#jsonPath(payload,'$.symbol')"处理XML数据时,xpath() SpEL - 函数可以应用相同的语法。也可以使用任何其他自定义SpEL - 函数。但是,为此,您应该构建一个包含@Configuration类的库,其中包含适当的SpelFunctionFactoryBean @Bean定义。应重新打包目标Spring Cloud Stream应用程序启动程序以提供具有内置Spring Boot @ComponentScan机制或自动配置挂钩的自定义扩展。
B.3.2.如何使用JDBC-sink?
JDBC-sink可用于将消息有效负载数据插入关系数据库表。默认情况下,它将整个有效内容插入到以jdbc.table-name属性命名的表中。如果未设置,则默认情况下,应用程序期望使用名称为messages的表。要更改此行为,JDBC接收器会接受多个选项,您可以使用流中的--param = value表示法传递或全局更改。JDBC接收器具有jdbc.initialize属性,如果设置为true,则会导致接收器在启动时根据指定的配置创建表。如果该initialize属性为false(默认值),则必须确保要使用的表已可用。
使用jdbc接收器并依赖于MySQL作为后备数据库的所有默认值的流定义类似于以下示例:
dataflow:>stream create --name mydata --definition "time | jdbc --spring.datasource.url=jdbc:mysql://localhost:3306/test --spring.datasource.username=root --spring.datasource.password=root --spring.datasource.driver-class-name=org.mariadb.jdbc.Driver" --deploy在前面的示例中,系统时间每秒都在MySQL中保留。为此,您必须在MySQL数据库中包含以下表:
CREATE TABLE test.messages
(
payload varchar(255)
);mysql> desc test.messages;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| payload | varchar(255) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
1 row in set (0.00 sec)mysql> select * from test.messages;
+-------------------+
| payload |
+-------------------+
| 04/25/17 09:10:04 |
| 04/25/17 09:10:06 |
| 04/25/17 09:10:07 |
| 04/25/17 09:10:08 |
| 04/25/17 09:10:09 |
.............
.............
.............B.3.3.如何使用多个邮件绑定器?
对于在两个不同的消息代理之间使用和处理数据的情况,Spring Cloud Data Flow提供易于覆盖的全局配置,开箱即用bridge-processor和DSL原语以构建这些类型的拓扑。
假设数据在RabbitMQ中排队(例如,queue = myRabbit),并且要求使用所有有效负载并将它们发布到Apache Kafka(例如,topic = myKafka) ,作为下游处理的目的地。
在这种情况下,您应该遵循配置的全局应用程序来定义多个绑定器配置,如以下配置中所示
# Apache Kafka Global Configurations (that is, identified by "kafka1")
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.kafka1.type=kafka
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.binder.brokers=localhost:9092
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.binder.zkNodes=localhost:2181
# RabbitMQ Global Configurations (that is, identified by "rabbit1")
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.rabbit1.type=rabbit
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.host=localhost
spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.binders.rabbit1.environment.spring.rabbitmq.port=5672
在前面的示例中,两个消息代理都在本地运行,并且可以通过各自的端口在localhost访问。
|
这些属性可以在.properties文件中提供,该文件可直接或通过config-server访问服务器,如下所示:
java -jar spring-cloud-dataflow-server-local/target/spring-cloud-dataflow-server-local-1.7.3.RELEASE.jar --spring.config.location=/foo.properties Spring Cloud Data Flow内部使用bridge-processor直接连接不同的命名通道目的地。由于我们要从两个不同的消息传递系统发布和订阅,因此必须在类路径中使用RabbitMQ和Apache Kafka绑定器构建bridge-processor。为此,请转到start-scs.cfapps.io/并选择Bridge Processor,Kafka binder starter和Rabbit binder starter作为依赖项,并按照参考指南中描述的修补程序进行操作。具体来说,对于bridge-processor,您必须导入启动器提供的BridgeProcessorConfiguration。
完成必要的调整后,即可构建应用程序。以下示例将应用程序的名称注册为multiBinderBridge:
dataflow:>app register --type processor --name multiBinderBridge --uri file:///<PATH-TO-FILE>/multipleBinderBridge-0.0.1-SNAPSHOT.jar是时候使用新注册的处理器应用程序创建流定义,如下所示:
dataflow:>stream create fooRabbitToBarKafka --definition ":fooRabbit > multiBinderBridge --spring.cloud.stream.bindings.input.binder=rabbit1 --spring.cloud.stream.bindings.output.binder=kafka1 > :barKafka" --deploy
由于我们要使用来自RabbitMQ的消息(由rabbit1标识)然后将有效负载发布到Apache Kafka(由kafka1标识),因此我们将其作为input和output通道设置分别。
|
该流使用来自RabbitMQ中myRabbit队列的事件,并将数据发送到Apache Kafka中的myKafka主题。
|
附录C:Spring XD到SCDF
本附录介绍了如何从Spring XD迁移到Spring Cloud Data Flow,以及一些可能有用的提示和技巧。
C.1.术语变化
下表描述了从Spring XD到Spring Cloud Data Flow的术语变化:
| 旧 | 新 |
|---|---|
XD-Admin |
Server (implementations: local, Cloud Foundry, and Kubernetes) |
XD-Container |
N/A |
Modules |
Applications |
Admin UI |
Dashboard |
Message Bus |
Binders |
Batch / Job |
Task |
C.2.模块到应用程序
如果您有自定义的Spring XD模块,则需要重构它们以使用Spring Cloud Stream和Spring Cloud Task注释。作为该工作的一部分,您需要更新依赖项并将其构建为普通的Spring Boot应用程序。
C.2.1.定制应用
在转换自定义应用程序时,请记住以下信息:
-
Spring XD的流和批处理模块分别重构为Spring Cloud Stream和Spring Cloud Task应用程序启动器。在重构Spring XD模块时,这些应用程序可用作参考。
-
还有一些用于Spring Cloud Stream和Spring Cloud Task应用的样本供参考。
-
如果您想创建一个全新的自定义应用程序,请使用Spring Cloud Stream和Spring Cloud Task应用程序的入门指南,并查看开发指南。
-
或者,如果要修补任何现成的流应用程序,可以按照此处描述的过程进行操作。
C.2.2.申请注册
在注册应用程序时,请记住以下信息:
-
自定义流/任务应用程序可以注册为Spring Boot uber-jar用于Cloud Foundry或本地实现。它们也可以注册为Local,Cloud Foundry或Kuberenetes实现的docker镜像。除了Maven和docker解析之外,您还可以从
http(s)和file坐标解析应用程序工件。 -
与Spring XD不同,您不必在注册自定义应用程序时上传应用程序位。相反,您需要注册 Maven存储库中托管的应用程序坐标,或者通过上一个项目中讨论的其他方式注册。
-
默认情况下,没有预先加载的现成应用程序。它旨在提供灵活性,以便在您认为适合特定用例要求时注册应用程序。
-
根据活页夹选择,您可以手动添加适当的活页夹依赖项以构建特定于该活页夹类型的应用程序。或者,您可以按照Spring Initializr 过程创建一个嵌入了binder的应用程序。
C.2.3.申请Properties
在修改应用程序的属性时,请记住以下信息:
-
反水槽:
-
Spring Cloud Data Flow中不需要外围设备
redis。如果您打算使用counter-sink,则需要redis,并且您需要拥有自己的redis群集。
-
-
域值 - 抗衡水槽:
-
Spring Cloud Data Flow中不需要外围设备
redis。如果您打算使用field-value-counter-sink,则需要redis,并且您需要拥有自己的运行redis群集。
-
-
总结柜台汇:
-
Spring Cloud Data Flow中不需要外围设备
redis。如果您打算使用aggregate-counter-sink,则需要redis,并且您需要拥有自己的redis群集。
-
C.3.消息Bus至Binders
术语明智地,在Spring Cloud Data Flow中,消息总线实现通常被称为绑定器。
C.3.1.消息Bus
与Spring XD类似,Spring Cloud Data Flow包含一个可用于扩展活页夹界面的抽象。默认情况下,我们将Apache Kafka和RabbitMQ的固定视图作为生产就绪粘合剂。它们作为GA版本提供。
C.3.2.Binders
选择绑定器需要在类路径中提供正确的绑定器依赖关系。如果选择Kafka作为活页夹,则需要注册预先使用Kafka活页夹构建的流应用程序。如果要使用Kafka binder创建自定义应用程序,则需要在类路径中添加以下依赖项:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
<version>1.0.2.RELEASE</version>
</dependency>-
Spring Cloud Stream支持Apache Kafka和RabbitMQ。所有绑定器实现都在其各自的存储库中进行维护和管理。
-
每个Stream / Task应用程序都可以使用您选择的binder实现构建。所有开箱即用的应用程序都是为Kafka和Rabbit预先构建的,可以随时用作Maven工件(Spring Cloud Stream或Spring Cloud Task)或Docker镜像(Spring Cloud Stream或Spring Cloud Task)。更改活页夹需要选择正确的活页夹依赖项。或者,您可以从此版本的Spring Initializr下载预构建的应用程序,其中包含所需的“binder-starter”依赖项。
C.3.3.命名频道
从根本上说,所有消息传递通道都由pub / sub语义支持。与Spring XD不同,消息传递通道仅由topics或topic-exchange支持,并且在新架构中没有queues的表示。
-
${xd.module.index}不再受支持。相反,您可以直接与命名目标进行交互。 -
stream.index更改为:<stream-name>.<label/app-name>-
例如,
ticktock.0更改为:ticktock.time。
-
-
“主题/队列”前缀不需要与命名通道交互。
-
例如,
topic:mytopic更改为:mytopic。 -
例如,
stream create stream1 --definition ":foo > log"。
-
C.3.4.有向图
如果构建非线性流,则可以利用命名目标来构建有向图。
考虑以下来自Spring XD的示例:
stream create f --definition "queue:foo > transform --expression=payload+'-sample1' | log" --deploy
stream create b --definition "queue:bar > transform --expression=payload+'-sample2' | log" --deploy
stream create r --definition "http | router --expression=payload.contains('a')?'queue:sample1':'queue:sample2'" --deploy您可以在Spring Cloud Data Flow中执行以下操作:
stream create f --definition ":foo > transform --expression=payload+'-sample1' | log" --deploy
stream create b --definition ":bar > transform --expression=payload+'-sample2' | log" --deploy
stream create r --definition "http | router --expression=payload.contains('a')?'sample1':'sample2'" --deployC.4.批量到任务
根据定义,任务是任何不会永远运行的应用程序,它们会在某个时刻结束。任务包括Spring Batch个工作。任务应用程序可用于按需用例,例如数据库迁移,机器学习,计划操作等。使用Spring Cloud Task,您可以将Spring Batch作业构建为微服务应用程序。
C.5.Shell和DSL命令的变化
下表显示了对shell和DSL命令的更改:
| 老命令 | 新命令 |
|---|---|
module upload |
app register / app import |
module list |
app list |
module info |
app info |
admin config server |
dataflow config server |
job create |
task create |
job launch |
task launch |
job list |
task list |
job status |
task status |
job display |
task display |
job destroy |
task destroy |
job execution list |
task execution list |
runtime modules |
runtime apps |
C.6.REST API更改
下表显示了REST API的更改:
| 旧API | 新API |
|---|---|
/modules |
/apps |
/runtime/modules |
/runtime/apps |
/runtime/modules/{moduleId} |
/runtime/apps/{appId} |
/jobs/definitions |
/task/definitions |
/jobs/deployments |
/task/deployments |
C.7.UI(包括Flo)
Admin-UI现在名为Dashboard。用于访问仪表板的URI从localhost:9393/admin-ui更改为localhost:9393/dashboard。
-
应用程序(新视图):列出可供使用的所有已注册应用程序。此视图包含URI和每个应用程序支持的属性等详细信息。您还可以从此视图注册/取消注册应用程序。
-
运行时(容器):容器更改为运行时。
xd-container的概念已经消失,取而代之的是作为自主Spring Boot应用程序运行的开箱即用的应用程序。“运行时”选项卡显示在运行时平台中运行的应用程序(实现:本地,Cloud Foundry或Kubernetes)。您可以单击每个应用程序以查看相关详细信息,例如它的运行位置,使用的资源以及其他详细信息。 -
Spring Flo现在是OSS产品。Flo为Spring Cloud Data Flow的“创建流”现在是仪表板中的设计器选项卡。
-
任务(新视图):
-
“模块”子选项卡重命名为“应用程序”。
-
“定义”子选项卡列出了所有任务定义,包括作为任务编排的Spring Batch作业。
-
“执行”子选项卡以类似于Spring XD的作业执行列表的方式列出所有任务执行详细信息。
-
C.8.架构组件
Spring Cloud Data Flow带有显着简化的架构。实际上,与Spring XD相比,您需要更少的外设才能使用Spring Cloud Data Flow。
C.8.1.ZooKeeper
新架构中未使用ZooKeeper。
C.8.2.RDBMS
Spring Cloud Data Flow使用RDBMS而不是Redis进行流/任务定义,应用程序注册和作业存储库。默认配置使用嵌入式H2实例,但支持Oracle,DB2,SqlServer,MySQL / MariaDB,PostgreSQL,H2和HSQLDB数据库。要使用Oracle,DB2和SqlServer,您需要使用Spring Initializr创建自己的数据流服务器并添加适当的JDBC驱动程序依赖项。
C.8.3.Redis的
只有分析功能才需要运行Redis群集。具体来说,当您使用counter-sink,field-value-counter-sink或aggregate-counter-sink应用程序时,还需要有一个正在运行的Redis群集实例。
C.8.4.集群拓扑
Spring XD的xd-admin和xd-container服务器组件由流和任务应用程序替换,这些应用程序本身作为自治Spring Boot应用程序运行。应用程序在各种平台上本地运行,包括Cloud Foundry和Kubernetes。您可以单独开发,测试,部署,向上或向下扩展以及与(Spring Boot)应用程序交互,它们可以孤立地发展。
C.9.中央配置
为了支持应用程序配置属性的集中和一致管理,Spring Cloud Config服务器中包含Spring Cloud Config客户端库以及Spring Cloud Stream应用程序启动器提供的Spring Cloud Stream应用程序。您还可以在数据流服务器启动时将常用应用程序属性传递给所有流。
C.10.分配
Spring Cloud Data Flow是Spring Boot应用程序。根据您选择的平台,您可以下载相应的版本超级jar并将其部署或推送到运行时平台(Cloud Foundry或Kubernetes)。例如,如果在Cloud Foundry上运行Spring Cloud Data Flow,则可以下载Cloud Foundry服务器实现并执行cf push,如Cloud Foundry参考指南中所述。
C.11.Hadoop分发兼容性
hdfs-sink应用程序构建于Spring Hadoop 2.4.0版本之上,因此该应用程序与以下Hadoop发行版兼容:
-
Cloudera:cdh5
-
Pivotal Hadoop:phd30
-
Hortonworks Hadoop:hdp24
-
Hortonworks Hadoop:hdp23
-
Vanilla Hadoop:hadoop26
-
Vanilla Hadoop:2.7.x(默认)
C.12.用例比较
本附录的其余部分回顾了一些用例,以显示Spring XD和Spring Cloud Data Flow之间的差异。
C.12.1.用例#1:Ticktock
此用例假定您已经下载了XD和SCDF分发。
描述:使用local / singlenode的简单ticktock示例。
下表描述了差异:
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a binder of your choice Start a
|
Start an
|
Start
|
Create
|
Create
|
Review |
Review |
C.12.2.用例#2:使用自定义模块或应用程序流
此用例假定您已经下载了XD和SCDF分发。
描述:使用自定义模块或应用程序流。
下表描述了差异:
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a binder of your choice Start a
|
Start an
|
Start
|
Register a custom “processor” module to transform the payload to the desired format
|
Register custom “processor” application to transform payload to a desired format
|
Create a stream with a custom module
|
Create a stream with custom application
|
Review results in the |
Review results by using the |
C.12.3.用例#3:批处理作业
此用例假定您已经下载了XD和SCDF分发。
描述:批处理作业。
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a
|
Start an
|
Start
|
Register a custom “batch job” module
|
Register a custom “batch-job” as task application
|
Create a job with custom batch-job module
|
Create a task with a custom batch-job application
|
Deploy job
|
NA |
Launch job
|
Launch task
|
Review results in the |
Review results by using the |
附录D:建筑
要构建源,您需要安装JDK 1.8。
构建使用Maven包装器,因此您不必安装特定版本的Maven。要为Redis启用测试,请在构建之前运行服务器。有关如何运行Redis的更多信息将在本附录的后面部分中介绍。
主要构建命令如下:
$ ./mvnw clean install
如果您愿意,可以添加'-DskipTests'以避免运行测试。
您也可以自己安装Maven(> = 3.3.3)并在下面的示例中运行mvn命令代替./mvnw。如果您这样做,如果您的本地Maven设置不包含Spring预发布工件的存储库声明,您可能还需要添加-P spring。
|
您可能需要通过将MAVEN_OPTS环境变量设置为类似于-Xmx512m -XX:MaxPermSize=128m的值来增加Maven可用的内存量。我们尝试在.mvn配置中介绍这一点,因此,如果您发现必须这样做以使构建成功,请提出一个票证以将设置添加到源代码管理中。
|
D.1.文档
有一个full配置文件可生成文档。您可以使用以下命令仅构建文档:
$ ./mvnw clean package -DskipTests -P full -pl spring-cloud-dataflow-docs -am
D.2.使用本准则
如果您没有IDE首选项,我们建议您在使用代码时使用Spring Tools Suite或Eclipse。我们使用m2eclipse Eclipse插件来支持Maven。其他IDE和工具通常也可以正常工作。
D.2.1.使用m2eclipse导入Eclipse
在使用Eclipse时,我们建议使用m2eclipe eclipse插件。如果您还没有安装m2eclipse,可以从Eclipse市场获得。
不幸的是,m2e还不支持Maven 3.3。因此,一旦将项目导入Eclipse,您还需要告诉m2eclipse将.settings.xml文件用于项目。如果不这样做,您可能会看到许多与项目中的POM相关的错误。为此:
-
打开Eclipse首选项。
-
展开Maven首选项。
-
选择用户设置。
-
在“用户设置”字段中,单击“浏览”并导航到导入的Spring Cloud项目。
-
选择该项目中的
.settings.xml文件。 -
单击“应用”
-
单击确定。
或者,您可以将Spring Cloud .settings.xml文件中的存储库设置复制到您自己的~/.m2/settings.xml中。
|
D.2.2.在没有m2eclipse的情况下导入Eclipse
如果您不想使用m2eclipse,则可以使用以下命令生成Eclipse项目元数据:
$ ./mvnw eclipse:eclipse
通过从File菜单中选择Import existing projects,可以导入生成的Eclipse项目。
附录E:贡献
Spring Cloud是在非限制性Apache 2.0许可下发布的,遵循非常标准的Github开发过程,使用Github跟踪器解决问题并将pull请求合并到master中。如果您想贡献一些微不足道的东西,请不要犹豫,但请遵循以下指南。
E.1.签署贡献者许可协议
在我们接受非平凡的补丁或拉取请求之前,我们需要您签署贡献者的协议。签署贡献者的协议不会授予任何人对主存储库的提交权限,但它确实意味着我们可以接受您的贡献,如果我们这样做,您将获得作者信用。可能会要求活跃的贡献者加入核心团队,并且可以合并拉取请求。
E.2.代码约定和内务管理
以下指南对拉取请求都不是必不可少的,但它们都有助于您的开发人员理解并使用您的代码。它们也可以在原始拉取请求之后但在合并之前添加。
-
使用Spring Framework代码格式约定。如果使用Eclipse,则可以使用Spring Cloud Build项目中的
eclipse-code-formatter.xml文件导入格式化程序设置。如果使用IntelliJ,则可以使用Eclipse Code Formatter Plugin导入同一文件。 -
确保所有新的
.java文件都有一个简单的Javadoc类注释,至少有一个标识您的@author标记,最好至少有一个段落描述该类的用途。 -
将ASF许可证标头注释添加到所有新的
.java文件(为此,从项目中的现有文件进行复制)。 -
将自己添加为
@author到您实际修改的.java文件(超过整容更改)。 -
添加一些Javadoc,如果更改名称空间,则添加一些XSD doc元素。
-
一些单元测试也会有很多帮助。有人必须这样做,而你的开发人员也很欣赏这种努力。
-
如果没有其他人使用您的分支,请将其针对当前主服务器(或主项目中的其他目标分支)进行rebase。
-
编写提交消息时,请遵循这些约定。如果您修复了现有问题,请在提交消息末尾添加
Fixes gh-XXXX(其中XXXX是问题编号)。